 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Automatic Factuality Metrics Measure Factuality? A Critical Evaluation
Nov 26, 2024



Modern LLMs can now produce highly readable abstractive summaries, to the point where traditional automated metrics for evaluating summary quality, such as ROUGE, have become saturated. However, LLMs still sometimes introduce unwanted content into summaries, i.e., information inconsistent with or unsupported by their source. Measuring the occurrence of these often subtle ``hallucinations'' automatically has proved to be challenging. This in turn has motivated development of a variety of metrics intended to measure the factual consistency of generated summaries against their source. But are these approaches measuring what they purport to do? In this work, we stress-test automatic factuality metrics. Specifically, we investigate whether and to what degree superficial attributes of summary texts suffice to predict ``factuality'', finding that a (supervised) model using only such shallow features is reasonably competitive with SOTA factuality scoring methods. We then evaluate how factuality metrics respond to factual corrections in inconsistent summaries and find that only a few show meaningful improvements. In contrast, some metrics are more sensitive to benign, non-factual edits. Motivated by these insights, we show that one can ``game'' (most) automatic factuality metrics, i.e., reliably inflate ``factuality'' scores by appending innocuous sentences to generated summaries.Taken together, our results raise questions about the degree to which we should rely on existing automated factuality metrics and what exactly we want ``factuality metrics'' to measure.
Analyzing LLM Behavior in Dialogue Summarization: Unveiling Circumstantial Hallucination Trends
Jun 05, 2024



Recent advancements in large language models (LLMs) have considerably advanced the capabilities of summarization systems. However, they continue to face concerns about hallucinations. While prior work has evaluated LLMs extensively in news domains, most evaluation of dialogue summarization has focused on BART-based models, leaving a gap in our understanding of their faithfulness. Our work benchmarks the faithfulness of LLMs for dialogue summarization, using human annotations and focusing on identifying and categorizing span-level inconsistencies. Specifically, we focus on two prominent LLMs: GPT-4 and Alpaca-13B. Our evaluation reveals subtleties as to what constitutes a hallucination: LLMs often generate plausible inferences, supported by circumstantial evidence in the conversation, that lack direct evidence, a pattern that is less prevalent in older models. We propose a refined taxonomy of errors, coining the category of "Circumstantial Inference" to bucket these LLM behaviors and release the dataset. Using our taxonomy, we compare the behavioral differences between LLMs and older fine-tuned models. Additionally, we systematically assess the efficacy of automatic error detection methods on LLM summaries and find that they struggle to detect these nuanced errors. To address this, we introduce two prompt-based approaches for fine-grained error detection that outperform existing metrics, particularly for identifying "Circumstantial Inference."
GenAudit: Fixing Factual Errors in Language Model Outputs with Evidence
Feb 19, 2024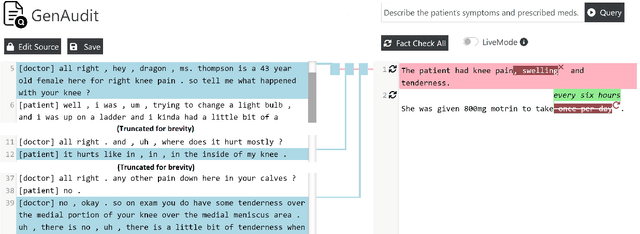


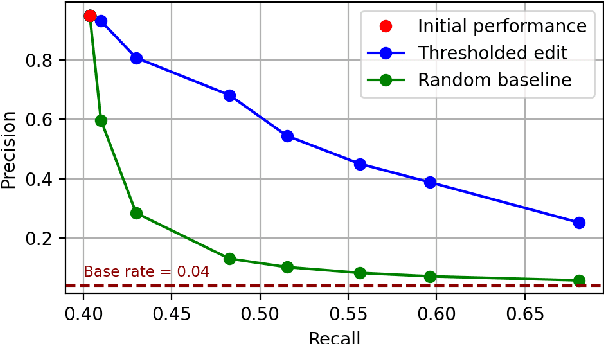
LLMs can generate factually incorrect statements even when provided access to reference documents. Such errors can be dangerous in high-stakes applications (e.g., document-grounded QA for healthcare or finance). We present GenAudit -- a tool intended to assist fact-checking LLM responses for document-grounded tasks. GenAudit suggests edits to the LLM response by revising or removing claims that are not supported by the reference document, and also presents evidence from the reference for facts that do appear to have support. We train models to execute these tasks, and design an interactive interface to present suggested edits and evidence to users. Comprehensive evaluation by human raters shows that GenAudit can detect errors in 8 different LLM outputs when summarizing documents from diverse domains. To ensure that most errors are flagged by the system, we propose a method that can increase the error recall while minimizing impact on precision. We will release our tool (GenAudit) and fact-checking model for public use.
Evaluating the Factuality of Zero-shot Summarizers Across Varied Domains
Feb 05, 2024



Recent work has shown that large language models (LLMs) are capable of generating summaries zero-shot (i.e., without explicit supervision) that, under human assessment, are often comparable or even preferred to manually composed reference summaries. However, this prior work has focussed almost exclusively on evaluating news article summarization. How do zero-shot summarizers perform in other (potentially more specialized) domains? In this work we evaluate zero-shot generated summaries across specialized domains including biomedical articles, and legal bills (in addition to standard news benchmarks for reference). We focus especially on the factuality of outputs. We acquire annotations from domain experts to identify inconsistencies in summaries and systematically categorize these errors. We analyze whether the prevalence of a given domain in the pretraining corpus affects extractiveness and faithfulness of generated summaries of articles in this domain. We release all collected annotations to facilitate additional research toward measuring and realizing factually accurate summarization, beyond news articles. The dataset can be downloaded from https://github.com/sanjanaramprasad/zero_shot_faceval_domains
USB: A Unified Summarization Benchmark Across Tasks and Domains
May 23, 2023



An abundance of datasets exist for training and evaluating models on the task of summary generation.However, these datasets are often derived heuristically, and lack sufficient annotations to support research into all aspects of summarization, such as evidence extraction and controllable summarization. We introduce a benchmark comprising 8 tasks that require multi-dimensional understanding of summarization, e.g., surfacing evidence for a summary, assessing its correctness, and gauging its relevance to different topics. We compare various methods on this benchmark and discover that on multiple tasks, moderately-sized fine-tuned models consistently outperform much larger few-shot prompted language models. For factuality related tasks, we also evaluate existing heuristics to create training data and find that training on them performs worse than training on $20\times$ less human-labeled data. Our benchmark consists of data from 6 different domains, allowing us to study cross-domain performance of trained models. We find that for some tasks, the amount of training data matters more than the domain where it comes from, while for other tasks training specifically on data from the target domain, even if limited, is more beneficial. Our work fulfills the need for a well-annotated summarization benchmark with diverse tasks, and provides useful insights about the impact of the quality, size and domain of training data.
Automatically Summarizing Evidence from Clinical Trials: A Prototype Highlighting Current Challenges
Mar 07, 2023

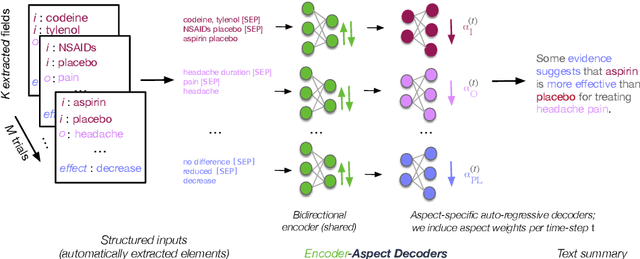

We present TrialsSummarizer, a system that aims to automatically summarize evidence presented in the set of randomized controlled trials most relevant to a given query. Building on prior work, the system retrieves trial publications matching a query specifying a combination of condition, intervention(s), and outcome(s), and ranks these according to sample size and estimated study quality. The top-k such studies are passed through a neural multi-document summarization system, yielding a synopsis of these trials. We consider two architectures: A standard sequence-to-sequence model based on BART and a multi-headed architecture intended to provide greater transparency to end-users. Both models produce fluent and relevant summaries of evidence retrieved for queries, but their tendency to introduce unsupported statements render them inappropriate for use in this domain at present. The proposed architecture may help users verify outputs allowing users to trace generated tokens back to inputs.