 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccounting for Focus Ambiguity in Visual Questions
Jan 04, 2025



No existing work on visual question answering explicitly accounts for ambiguity regarding where the content described in the question is located in the image. To fill this gap, we introduce VQ-FocusAmbiguity, the first VQA dataset that visually grounds each region described in the question that is necessary to arrive at the answer. We then provide an analysis showing how our dataset for visually grounding `questions' is distinct from visually grounding `answers', and characterize the properties of the questions and segmentations provided in our dataset. Finally, we benchmark modern models for two novel tasks: recognizing whether a visual question has focus ambiguity and localizing all plausible focus regions within the image. Results show that the dataset is challenging for modern models. To facilitate future progress on these tasks, we publicly share the dataset with an evaluation server at https://focusambiguity.github.io/.
BIV-Priv-Seg: Locating Private Content in Images Taken by People With Visual Impairments
Jul 25, 2024
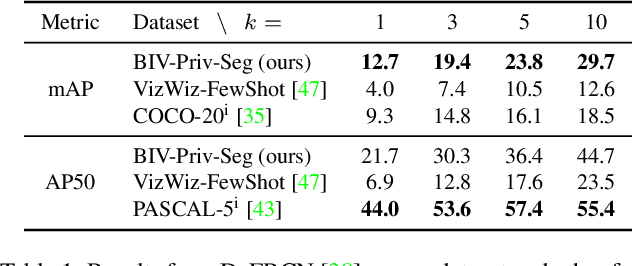


Individuals who are blind or have low vision (BLV) are at a heightened risk of sharing private information if they share photographs they have taken. To facilitate developing technologies that can help preserve privacy, we introduce BIV-Priv-Seg, the first localization dataset originating from people with visual impairments that shows private content. It contains 1,028 images with segmentation annotations for 16 private object categories. We first characterize BIV-Priv-Seg and then evaluate modern models' performance for locating private content in the dataset. We find modern models struggle most with locating private objects that are not salient, small, and lack text as well as recognizing when private content is absent from an image. We facilitate future extensions by sharing our new dataset with the evaluation server at https://vizwiz.org/tasks-and-datasets/object-localization.
VizWiz-FewShot: Locating Objects in Images Taken by People With Visual Impairments
Jul 24, 2022


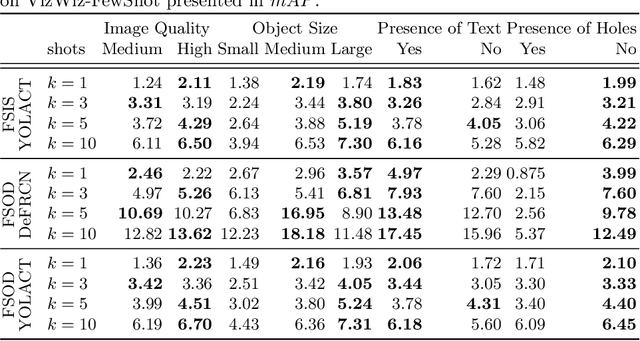
We introduce a few-shot localization dataset originating from photographers who authentically were trying to learn about the visual content in the images they took. It includes nearly 10,000 segmentations of 100 categories in over 4,500 images that were taken by people with visual impairments. Compared to existing few-shot object detection and instance segmentation datasets, our dataset is the first to locate holes in objects (e.g., found in 12.3\% of our segmentations), it shows objects that occupy a much larger range of sizes relative to the images, and text is over five times more common in our objects (e.g., found in 22.4\% of our segmentations). Analysis of three modern few-shot localization algorithms demonstrates that they generalize poorly to our new dataset. The algorithms commonly struggle to locate objects with holes, very small and very large objects, and objects lacking text. To encourage a larger community to work on these unsolved challenges, we publicly share our annotated few-shot dataset at https://vizwiz.org .