 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVizWiz-FewShot: Locating Objects in Images Taken by People With Visual Impairments
Paper and Code
Jul 24, 2022


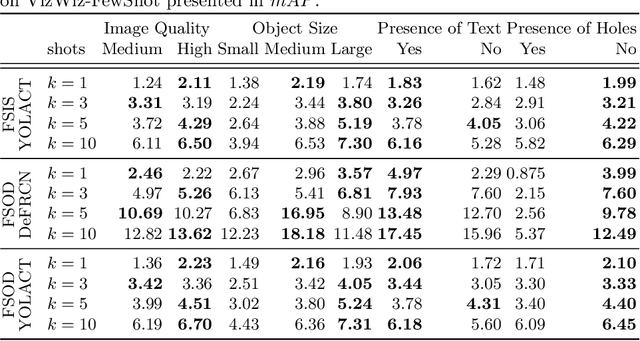
We introduce a few-shot localization dataset originating from photographers who authentically were trying to learn about the visual content in the images they took. It includes nearly 10,000 segmentations of 100 categories in over 4,500 images that were taken by people with visual impairments. Compared to existing few-shot object detection and instance segmentation datasets, our dataset is the first to locate holes in objects (e.g., found in 12.3\% of our segmentations), it shows objects that occupy a much larger range of sizes relative to the images, and text is over five times more common in our objects (e.g., found in 22.4\% of our segmentations). Analysis of three modern few-shot localization algorithms demonstrates that they generalize poorly to our new dataset. The algorithms commonly struggle to locate objects with holes, very small and very large objects, and objects lacking text. To encourage a larger community to work on these unsolved challenges, we publicly share our annotated few-shot dataset at https://vizwiz.org .