 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Large Language Models are autonomous practitioners of evidence-based medicine
Jan 05, 2024



Background: Evidence-based medicine (EBM) is fundamental to modern clinical practice, requiring clinicians to continually update their knowledge and apply the best clinical evidence in patient care. The practice of EBM faces challenges due to rapid advancements in medical research, leading to information overload for clinicians. The integration of artificial intelligence (AI), specifically Generative Large Language Models (LLMs), offers a promising solution towards managing this complexity. Methods: This study involved the curation of real-world clinical cases across various specialties, converting them into .json files for analysis. LLMs, including proprietary models like ChatGPT 3.5 and 4, Gemini Pro, and open-source models like LLaMA v2 and Mixtral-8x7B, were employed. These models were equipped with tools to retrieve information from case files and make clinical decisions similar to how clinicians must operate in the real world. Model performance was evaluated based on correctness of final answer, judicious use of tools, conformity to guidelines, and resistance to hallucinations. Results: GPT-4 was most capable of autonomous operation in a clinical setting, being generally more effective in ordering relevant investigations and conforming to clinical guidelines. Limitations were observed in terms of model ability to handle complex guidelines and diagnostic nuances. Retrieval Augmented Generation made recommendations more tailored to patients and healthcare systems. Conclusions: LLMs can be made to function as autonomous practitioners of evidence-based medicine. Their ability to utilize tooling can be harnessed to interact with the infrastructure of a real-world healthcare system and perform the tasks of patient management in a guideline directed manner. Prompt engineering may help to further enhance this potential and transform healthcare for the clinician and the patient.
Cross-Modal Contrastive Learning for Abnormality Classification and Localization in Chest X-rays with Radiomics using a Feedback Loop
Apr 19, 2021
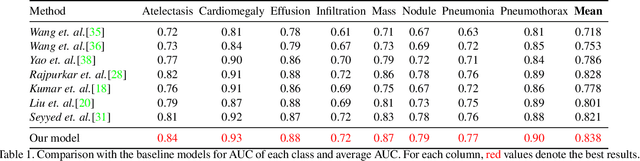
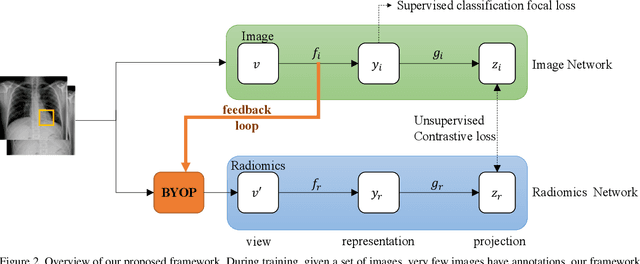
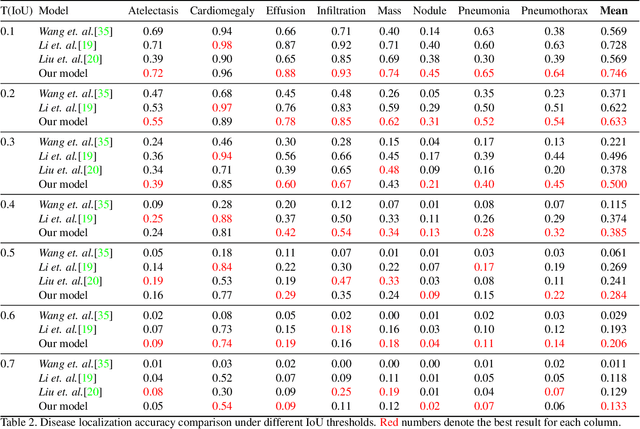
Building a highly accurate predictive model for these tasks usually requires a large number of manually annotated labels and pixel regions (bounding boxes) of abnormalities. However, it is expensive to acquire such annotations, especially the bounding boxes. Recently, contrastive learning has shown strong promise in leveraging unlabeled natural images to produce highly generalizable and discriminative features. However, extending its power to the medical image domain is under-explored and highly non-trivial, since medical images are much less amendable to data augmentations. In contrast, their domain knowledge, as well as multi-modality information, is often crucial. To bridge this gap, we propose an end-to-end semi-supervised cross-modal contrastive learning framework, that simultaneously performs disease classification and localization tasks. The key knob of our framework is a unique positive sampling approach tailored for the medical images, by seamlessly integrating radiomic features as an auxiliary modality. Specifically, we first apply an image encoder to classify the chest X-rays and to generate the image features. We next leverage Grad-CAM to highlight the crucial (abnormal) regions for chest X-rays (even when unannotated), from which we extract radiomic features. The radiomic features are then passed through another dedicated encoder to act as the positive sample for the image features generated from the same chest X-ray. In this way, our framework constitutes a feedback loop for image and radiomic modality features to mutually reinforce each other. Their contrasting yields cross-modality representations that are both robust and interpretable. Extensive experiments on the NIH Chest X-ray dataset demonstrate that our approach outperforms existing baselines in both classification and localization tasks.