 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolBridge: An Open-Source Dataset to Equip LLMs with External Tool Capabilities
Paper and Code


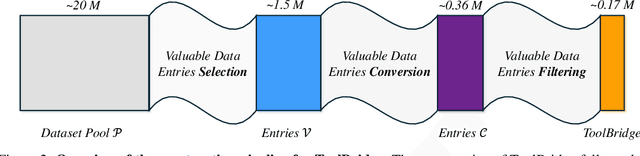

Through the integration of external tools, large language models (LLMs) such as GPT-4o and Llama 3.1 significantly expand their functional capabilities, evolving from elementary conversational agents to general-purpose assistants. We argue that the primary drivers of these advancements are the quality and diversity of the training data. However, the existing LLMs with external tool integration provide only limited transparency regarding their datasets and data collection methods, which has led to the initiation of this research. Specifically, in this paper, our objective is to elucidate the detailed process involved in constructing datasets that empower LLMs to effectively learn how to utilize external tools and make this information available to the public through the introduction of ToolBridge. ToolBridge proposes to employ a collection of general open-access datasets as its raw dataset pool and applies a series of strategies to identify appropriate data entries from the pool for external tool API insertions. By supervised fine-tuning on these curated data entries, LLMs can invoke external tools in appropriate contexts to boost their predictive accuracy, particularly for basic functions including data processing, numerical computation, and factual retrieval. Our experiments rigorously isolates model architectures and training configurations, focusing exclusively on the role of data. The experimental results indicate that LLMs trained on ToolBridge demonstrate consistent performance improvements on both standard benchmarks and custom evaluation datasets. All the associated code and data will be open-source at https://github.com/CharlesPikachu/ToolBridge, promoting transparency and facilitating the broader community to explore approaches for equipping LLMs with external tools capabilities.