 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Prototype Encoding for Incremental Video Highlights Detection
Paper and Code


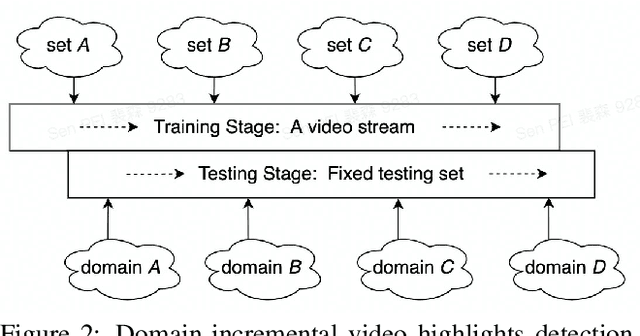
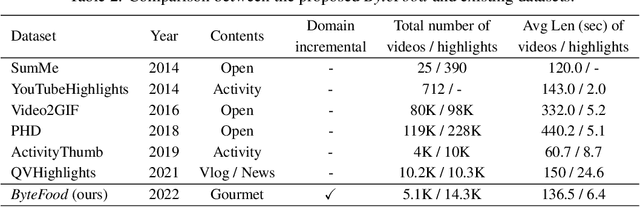
Video highlights detection has been long researched as a topic in computer vision tasks, digging the user-appealing clips out given unexposed raw video inputs. However, in most case, the mainstream methods in this line of research are built on the closed world assumption, where a fixed number of highlight categories is defined properly in advance and need all training data to be available at the same time, and as a result, leads to poor scalability with respect to both the highlight categories and the size of the dataset. To tackle the problem mentioned above, we propose a video highlights detector that is able to learn incrementally, namely \textbf{G}lobal \textbf{P}rototype \textbf{E}ncoding (GPE), capturing newly defined video highlights in the extended dataset via their corresponding prototypes. Alongside, we present a well annotated and costly dataset termed \emph{ByteFood}, including more than 5.1k gourmet videos belongs to four different domains which are \emph{cooking}, \emph{eating}, \emph{food material}, and \emph{presentation} respectively. To the best of our knowledge, this is the first time the incremental learning settings are introduced to video highlights detection, which in turn relieves the burden of training video inputs and promotes the scalability of conventional neural networks in proportion to both the size of the dataset and the quantity of domains. Moreover, the proposed GPE surpasses current incremental learning methods on \emph{ByteFood}, reporting an improvement of 1.57\% mAP at least. The code and dataset will be made available sooner.