 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Concealment: Free Lunch for Defending Adversarial Attacks
Paper and Code

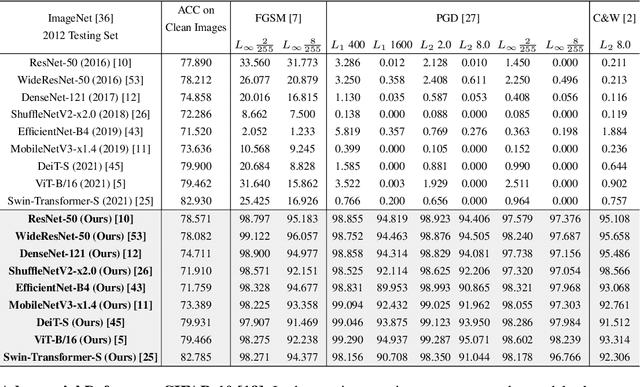
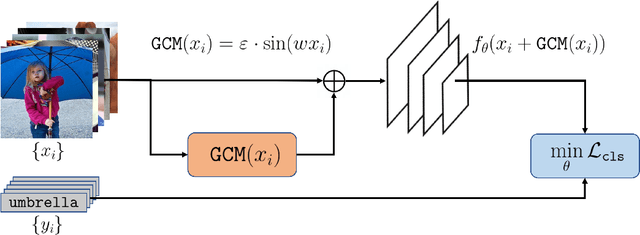

Recent studies show that the deep neural networks (DNNs) have achieved great success in various tasks. However, even the \emph{state-of-the-art} deep learning based classifiers are extremely vulnerable to adversarial examples, resulting in sharp decay of discrimination accuracy in the presence of enormous unknown attacks. Given the fact that neural networks are widely used in the open world scenario which can be safety-critical situations, mitigating the adversarial effects of deep learning methods has become an urgent need. Generally, conventional DNNs can be attacked with a dramatically high success rate since their gradient is exposed thoroughly in the white-box scenario, making it effortless to ruin a well trained classifier with only imperceptible perturbations in the raw data space. For tackling this problem, we propose a plug-and-play layer that is training-free, termed as \textbf{G}radient \textbf{C}oncealment \textbf{M}odule (GCM), concealing the vulnerable direction of gradient while guaranteeing the classification accuracy during the inference time. GCM reports superior defense results on the ImageNet classification benchmark, improving up to 63.41\% top-1 attack robustness (AR) when faced with adversarial inputs compared to the vanilla DNNs. Moreover, we use GCM in the CVPR 2022 Robust Classification Challenge, currently achieving \textbf{2nd} place in Phase II with only a tiny version of ConvNext. The code will be made available.