 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMatch: A Large-scale Audio Beat Matching Benchmark for Boosting Deep Learning Assistant Video Editing
Mar 03, 2023The explosion of short videos has dramatically reshaped the manners people socialize, yielding a new trend for daily sharing and access to the latest information. These rich video resources, on the one hand, benefited from the popularization of portable devices with cameras, but on the other, they can not be independent of the valuable editing work contributed by numerous video creators. In this paper, we investigate a novel and practical problem, namely audio beat matching (ABM), which aims to recommend the proper transition time stamps based on the background music. This technique helps to ease the labor-intensive work during video editing, saving energy for creators so that they can focus more on the creativity of video content. We formally define the ABM problem and its evaluation protocol. Meanwhile, a large-scale audio dataset, i.e., the AutoMatch with over 87k finely annotated background music, is presented to facilitate this newly opened research direction. To further lay solid foundations for the following study, we also propose a novel model termed BeatX to tackle this challenging task. Alongside, we creatively present the concept of label scope, which eliminates the data imbalance issues and assigns adaptive weights for the ground truth during the training procedure in one stop. Though plentiful short video platforms have flourished for a long time, the relevant research concerning this scenario is not sufficient, and to the best of our knowledge, AutoMatch is the first large-scale dataset to tackle the audio beat matching problem. We hope the released dataset and our competitive baseline can encourage more attention to this line of research. The dataset and codes will be made publicly available.
FFusionCGAN: An end-to-end fusion method for few-focus images using conditional GAN in cytopathological digital slides
Jan 03, 2020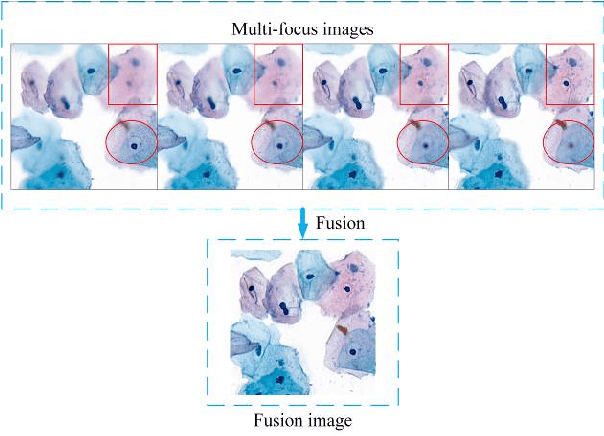
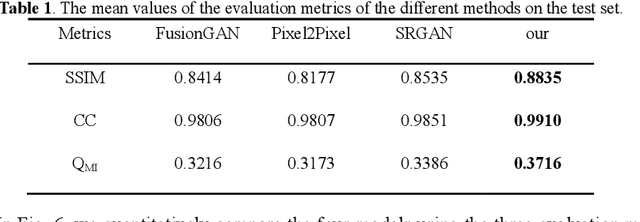
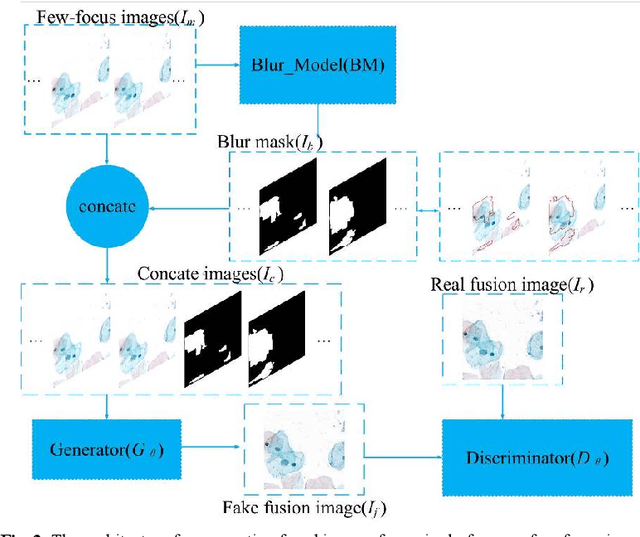
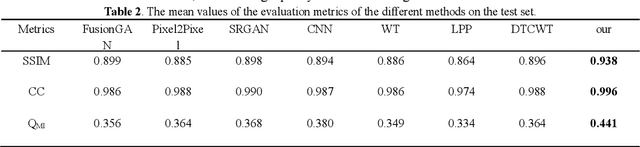
Multi-focus image fusion technologies compress different focus depth images into an image in which most objects are in focus. However, although existing image fusion techniques, including traditional algorithms and deep learning-based algorithms, can generate high-quality fused images, they need multiple images with different focus depths in the same field of view. This criterion may not be met in some cases where time efficiency is required or the hardware is insufficient. The problem is especially prominent in large-size whole slide images. This paper focused on the multi-focus image fusion of cytopathological digital slide images, and proposed a novel method for generating fused images from single-focus or few-focus images based on conditional generative adversarial network (GAN). Through the adversarial learning of the generator and discriminator, the method is capable of generating fused images with clear textures and large depth of field. Combined with the characteristics of cytopathological images, this paper designs a new generator architecture combining U-Net and DenseBlock, which can effectively improve the network's receptive field and comprehensively encode image features. Meanwhile, this paper develops a semantic segmentation network that identifies the blurred regions in cytopathological images. By integrating the network into the generative model, the quality of the generated fused images is effectively improved. Our method can generate fused images from only single-focus or few-focus images, thereby avoiding the problem of collecting multiple images of different focus depths with increased time and hardware costs. Furthermore, our model is designed to learn the direct mapping of input source images to fused images without the need to manually design complex activity level measurements and fusion rules as in traditional methods.
Multi-stage domain adversarial style reconstruction for cytopathological image stain normalization
Sep 11, 2019
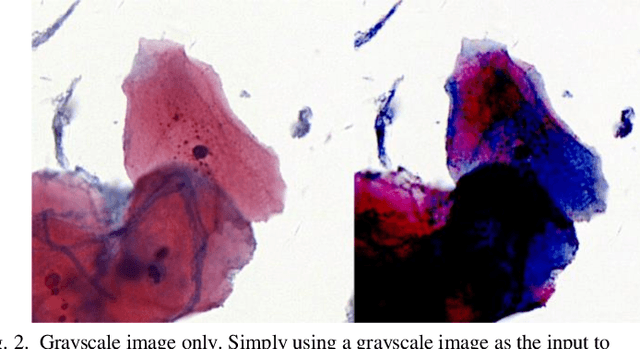

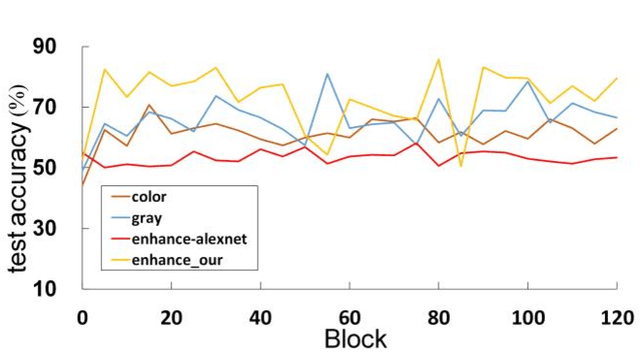
The different stain styles of cytopathological images have a negative effect on the generalization ability of automated image analysis algorithms. This article proposes a new framework that normalizes the stain style for cytopathological images through a stain removal module and a multi-stage domain adversarial style reconstruction module. We convert colorful images into grayscale images with a color-encoding mask. Using the mask, reconstructed images retain their basic color without red and blue mixing, which is important for cytopathological image interpretation. The style reconstruction module consists of per-pixel regression with intradomain adversarial learning, inter-domain adversarial learning, and optional task-based refining. Per-pixel regression with intradomain adversarial learning establishes the generative network from the decolorized input to the reconstructed output. The interdomain adversarial learning further reduces the difference in stain style. The generation network can be optimized by combining it with the task network. Experimental results show that the proposed techniques help to optimize the generation network. The average accuracy increases from 75.41% to 84.79% after the intra-domain adversarial learning, and to 87.00% after interdomain adversarial learning. Under the guidance of the task network, the average accuracy rate reaches 89.58%. The proposed method achieves unsupervised stain normalization of cytopathological images, while preserving the cell structure, texture structure, and cell color properties of the image. This method overcomes the problem of generalizing the task models between different stain styles of cytopathological images.