 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFFusionCGAN: An end-to-end fusion method for few-focus images using conditional GAN in cytopathological digital slides
Paper and Code
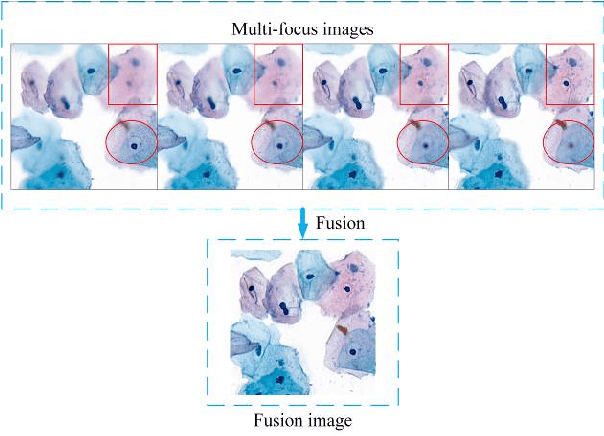
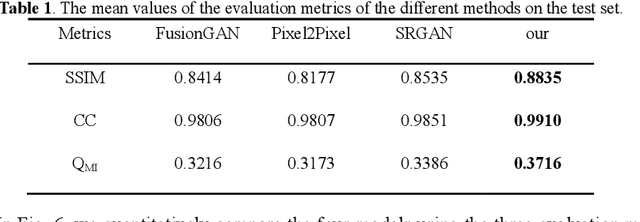
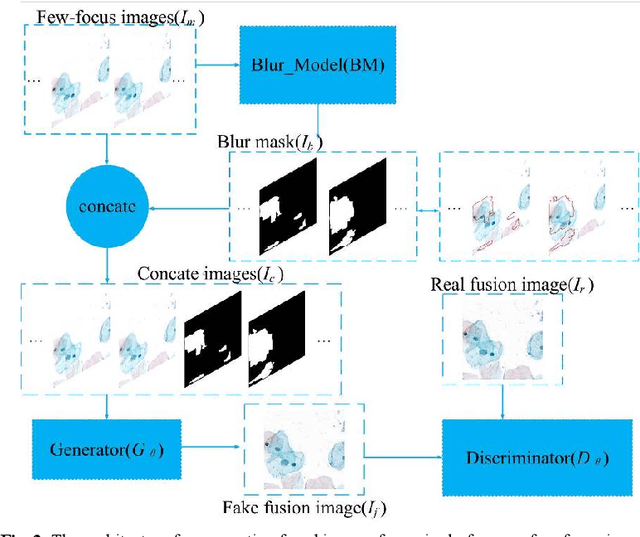
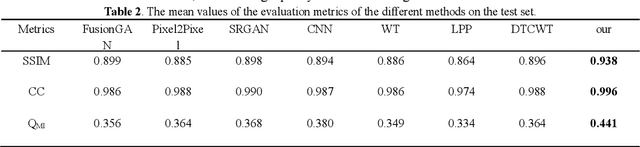
Multi-focus image fusion technologies compress different focus depth images into an image in which most objects are in focus. However, although existing image fusion techniques, including traditional algorithms and deep learning-based algorithms, can generate high-quality fused images, they need multiple images with different focus depths in the same field of view. This criterion may not be met in some cases where time efficiency is required or the hardware is insufficient. The problem is especially prominent in large-size whole slide images. This paper focused on the multi-focus image fusion of cytopathological digital slide images, and proposed a novel method for generating fused images from single-focus or few-focus images based on conditional generative adversarial network (GAN). Through the adversarial learning of the generator and discriminator, the method is capable of generating fused images with clear textures and large depth of field. Combined with the characteristics of cytopathological images, this paper designs a new generator architecture combining U-Net and DenseBlock, which can effectively improve the network's receptive field and comprehensively encode image features. Meanwhile, this paper develops a semantic segmentation network that identifies the blurred regions in cytopathological images. By integrating the network into the generative model, the quality of the generated fused images is effectively improved. Our method can generate fused images from only single-focus or few-focus images, thereby avoiding the problem of collecting multiple images of different focus depths with increased time and hardware costs. Furthermore, our model is designed to learn the direct mapping of input source images to fused images without the need to manually design complex activity level measurements and fusion rules as in traditional methods.