 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProIn: Learning to Predict Trajectory Based on Progressive Interactions for Autonomous Driving
Mar 25, 2024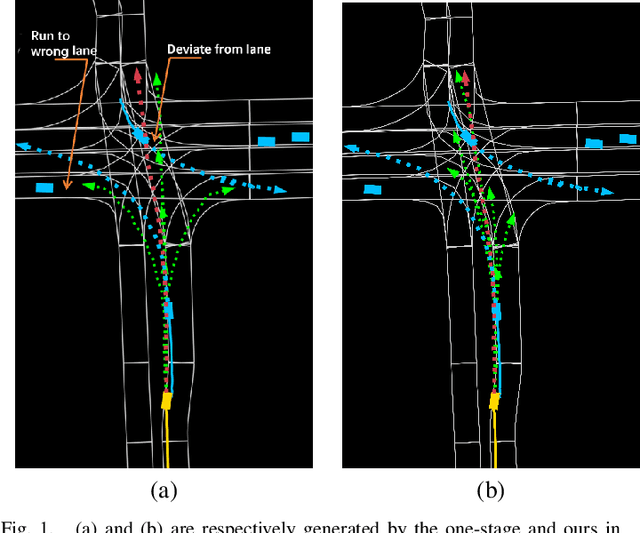
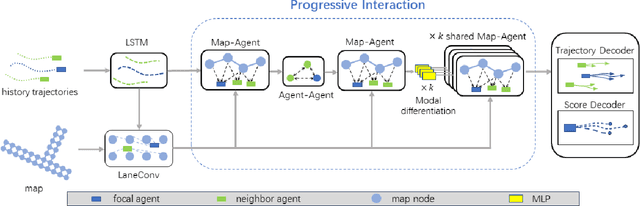
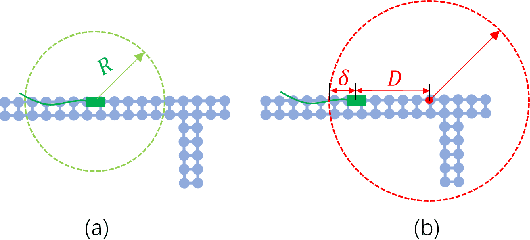
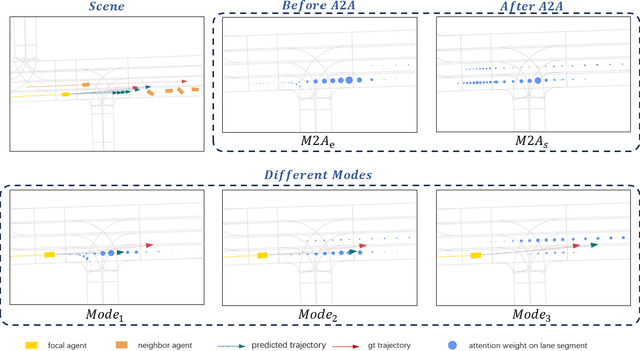
Accurate motion prediction of pedestrians, cyclists, and other surrounding vehicles (all called agents) is very important for autonomous driving. Most existing works capture map information through an one-stage interaction with map by vector-based attention, to provide map constraints for social interaction and multi-modal differentiation. However, these methods have to encode all required map rules into the focal agent's feature, so as to retain all possible intentions' paths while at the meantime to adapt to potential social interaction. In this work, a progressive interaction network is proposed to enable the agent's feature to progressively focus on relevant maps, in order to better learn agents' feature representation capturing the relevant map constraints. The network progressively encode the complex influence of map constraints into the agent's feature through graph convolutions at the following three stages: after historical trajectory encoder, after social interaction, and after multi-modal differentiation. In addition, a weight allocation mechanism is proposed for multi-modal training, so that each mode can obtain learning opportunities from a single-mode ground truth. Experiments have validated the superiority of progressive interactions to the existing one-stage interaction, and demonstrate the effectiveness of each component. Encouraging results were obtained in the challenging benchmarks.
IDAN: Image Difference Attention Network for Change Detection
Aug 17, 2022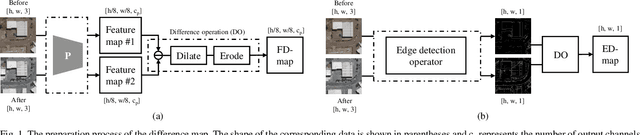
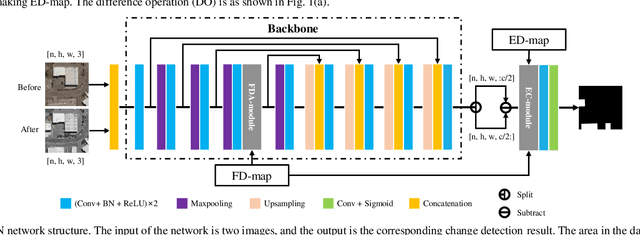
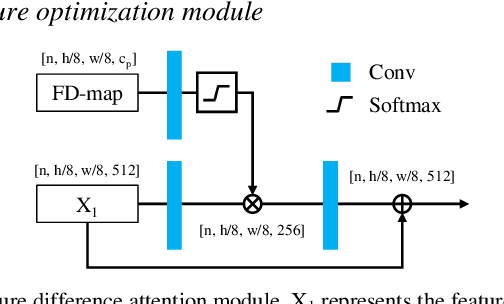
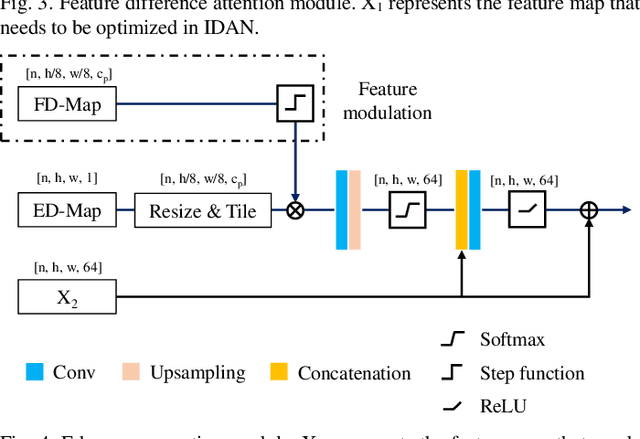
Remote sensing image change detection is of great importance in disaster assessment and urban planning. The mainstream method is to use encoder-decoder models to detect the change region of two input images. Since the change content of remote sensing images has the characteristics of wide scale range and variety, it is necessary to improve the detection accuracy of the network by increasing the attention mechanism, which commonly includes: Squeeze-and-Excitation block, Non-local and Convolutional Block Attention Module, among others. These methods consider the importance of different location features between channels or within channels, but fail to perceive the differences between input images. In this paper, we propose a novel image difference attention network (IDAN). In the image preprocessing stage, we use a pre-training model to extract the feature differences between two input images to obtain the feature difference map (FD-map), and Canny for edge detection to obtain the edge difference map (ED-map). In the image feature extracting stage, the FD-map and ED-map are input to the feature difference attention module and edge compensation module, respectively, to optimize the features extracted by IDAN. Finally, the change detection result is obtained through the feature difference operation. IDAN comprehensively considers the differences in regional and edge features of images and thus optimizes the extracted image features. The experimental results demonstrate that the F1-score of IDAN improves 1.62% and 1.98% compared to the baseline model on WHU dataset and LEVIR-CD dataset, respectively.
Road detection via a dual-task network based on cross-layer graph fusion modules
Aug 17, 2022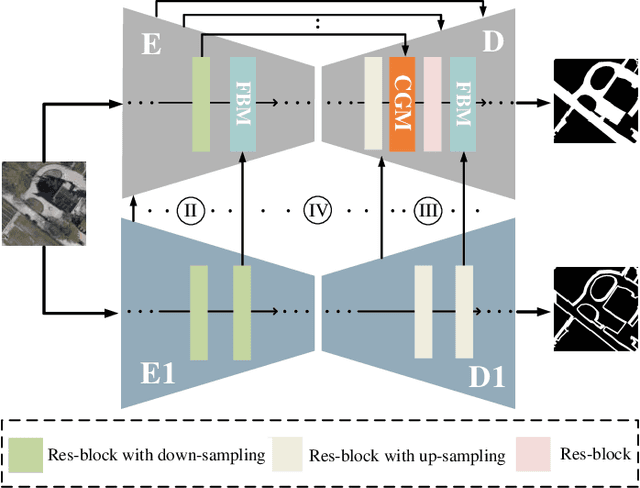
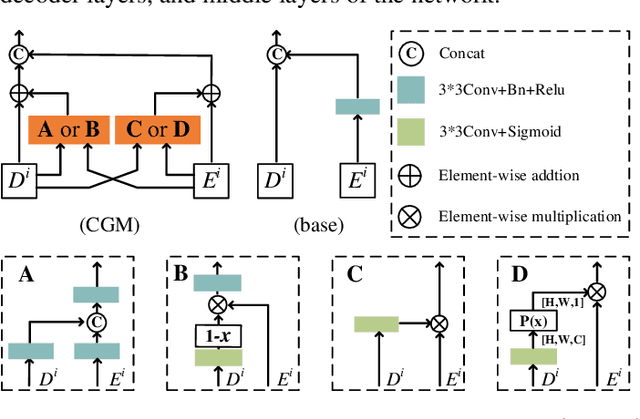
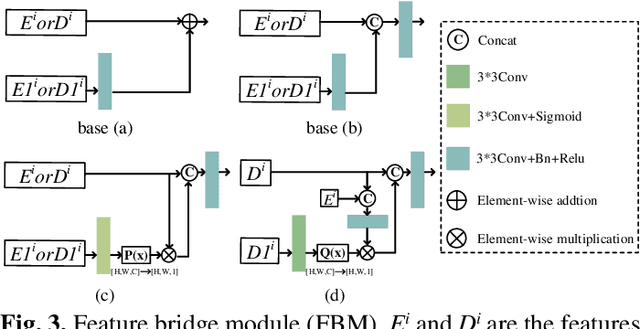
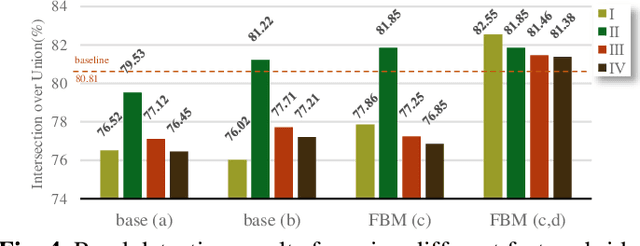
Road detection based on remote sensing images is of great significance to intelligent traffic management. The performances of the mainstream road detection methods are mainly determined by their extracted features, whose richness and robustness can be enhanced by fusing features of different types and cross-layer connections. However, the features in the existing mainstream model frameworks are often similar in the same layer by the single-task training, and the traditional cross-layer fusion ways are too simple to obtain an efficient effect, so more complex fusion ways besides concatenation and addition deserve to be explored. Aiming at the above defects, we propose a dual-task network (DTnet) for road detection and cross-layer graph fusion module (CGM): the DTnet consists of two parallel branches for road area and edge detection, respectively, while enhancing the feature diversity by fusing features between two branches through our designed feature bridge modules (FBM). The CGM improves the cross-layer fusion effect by a complex feature stream graph, and four graph patterns are evaluated. Experimental results on three public datasets demonstrate that our method effectively improves the final detection result.