 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVPBench: A Benchmark and Fine-Tuning Framework for Aligning Large Language Models with Diverse Human Values
Sep 09, 2025The alignment of large language models (LLMs) with human values is critical for their safe and effective deployment across diverse user populations. However, existing benchmarks often neglect cultural and demographic diversity, leading to limited understanding of how value alignment generalizes globally. In this work, we introduce MVPBench, a novel benchmark that systematically evaluates LLMs' alignment with multi-dimensional human value preferences across 75 countries. MVPBench contains 24,020 high-quality instances annotated with fine-grained value labels, personalized questions, and rich demographic metadata, making it the most comprehensive resource of its kind to date. Using MVPBench, we conduct an in-depth analysis of several state-of-the-art LLMs, revealing substantial disparities in alignment performance across geographic and demographic lines. We further demonstrate that lightweight fine-tuning methods, such as Low-Rank Adaptation (LoRA) and Direct Preference Optimization (DPO), can significantly enhance value alignment in both in-domain and out-of-domain settings. Our findings underscore the necessity for population-aware alignment evaluation and provide actionable insights for building culturally adaptive and value-sensitive LLMs. MVPBench serves as a practical foundation for future research on global alignment, personalized value modeling, and equitable AI development.
Redefining Superalignment: From Weak-to-Strong Alignment to Human-AI Co-Alignment to Sustainable Symbiotic Society
Apr 24, 2025Artificial Intelligence (AI) systems are becoming increasingly powerful and autonomous, and may progress to surpass human intelligence levels, namely Artificial Superintelligence (ASI). During the progression from AI to ASI, it may exceed human control, violate human values, and even lead to irreversible catastrophic consequences in extreme cases. This gives rise to a pressing issue that needs to be addressed: superalignment, ensuring that AI systems much smarter than humans, remain aligned with human (compatible) intentions and values. Existing scalable oversight and weak-to-strong generalization methods may prove substantially infeasible and inadequate when facing ASI. We must explore safer and more pluralistic frameworks and approaches for superalignment. In this paper, we redefine superalignment as the human-AI co-alignment towards a sustainable symbiotic society, and highlight a framework that integrates external oversight and intrinsic proactive alignment. External oversight superalignment should be grounded in human-centered ultimate decision, supplemented by interpretable automated evaluation and correction, to achieve continuous alignment with humanity's evolving values. Intrinsic proactive superalignment is rooted in a profound understanding of the self, others, and society, integrating self-awareness, self-reflection, and empathy to spontaneously infer human intentions, distinguishing good from evil and proactively considering human well-being, ultimately attaining human-AI co-alignment through iterative interaction. The integration of externally-driven oversight with intrinsically-driven proactive alignment empowers sustainable symbiotic societies through human-AI co-alignment, paving the way for achieving safe and beneficial AGI and ASI for good, for human, and for a symbiotic ecology.
AI Governance InternationaL Evaluation Index (AGILE Index)
Feb 26, 2025The rapid advancement of Artificial Intelligence (AI) technology is profoundly transforming human society and concurrently presenting a series of ethical, legal, and social issues. The effective governance of AI has become a crucial global concern. Since 2022, the extensive deployment of generative AI, particularly large language models, marked a new phase in AI governance. Continuous efforts are being made by the international community in actively addressing the novel challenges posed by these AI developments. As consensus on international governance continues to be established and put into action, the practical importance of conducting a global assessment of the state of AI governance is progressively coming to light. In this context, we initiated the development of the AI Governance InternationaL Evaluation Index (AGILE Index). Adhering to the design principle, "the level of governance should match the level of development," the inaugural evaluation of the AGILE Index commences with an exploration of four foundational pillars: the development level of AI, the AI governance environment, the AI governance instruments, and the AI governance effectiveness. It covers 39 indicators across 18 dimensions to comprehensively assess the AI governance level of 14 representative countries globally. The index is utilized to delve into the status of AI governance to date in 14 countries for the first batch of evaluation. The aim is to depict the current state of AI governance in these countries through data scoring, assist them in identifying their governance stage and uncovering governance issues, and ultimately offer insights for the enhancement of their AI governance systems.
TriAdaptLoRA: Brain-Inspired Triangular Adaptive Low-Rank Adaptation for Parameter-Efficient Fine-Tuning
Jan 14, 2025



The fine-tuning of Large Language Models (LLMs) is pivotal for achieving optimal performance across diverse downstream tasks. However, while full fine-tuning delivers superior results, it entails significant computational and resource costs. Parameter-Efficient Fine-Tuning (PEFT) methods, such as LoRA, address these challenges by reducing the number of trainable parameters, but they often struggle with rank adjustment efficiency and task-specific adaptability. We propose Triangular Adaptive Low-Rank Adaptation (TriAdaptLoRA), a novel PEFT framework inspired by neuroscience principles, which dynamically optimizes the allocation of trainable parameters. TriAdaptLoRA introduces three key innovations: 1) a triangular split of transformation matrices into lower and upper triangular components to maximize parameter utilization, 2) a parameter importance metric based on normalized Frobenius norms for efficient adaptation, and 3) an adaptive rank-growth strategy governed by dynamic thresholds, allowing flexible parameter allocation across training steps. Experiments conducted on a variety of natural language understanding and generation tasks demonstrate that TriAdaptLoRA consistently outperforms existing PEFT methods. It achieves superior performance, enhanced stability, and reduced computational overhead, particularly under linear threshold-driven rank growth. These results highlight its efficacy as a scalable and resource-efficient solution for fine-tuning LLMs.
Matrix-Transformation Based Low-Rank Adaptation (MTLoRA): A Brain-Inspired Method for Parameter-Efficient Fine-Tuning
Mar 18, 2024Fine-tuning techniques based on Large Pretrained Language Models (LPLMs) have been proven to significantly enhance model performance on a variety of downstream tasks and effectively control the output behaviors of LPLMs. Recent studies have proposed numerous methods for fine-tuning a small number of parameters based on open-source LPLMs, reducing the demand for computational and storage resources. Among these, reparameterization fine-tuning methods represented by LoRA (Low-Rank Adaptation) have gained popularity. We find that although these methods perform well in many aspects, there is still considerable room for improvement in terms of complex task adaptability, performance, stability, and algorithm complexity. In response to this, inspired by the idea that the functions of the brain are shaped by its geometric structure, this paper integrates this idea into LoRA technology and proposes a new matrix transformation-based reparameterization method for efficient fine-tuning, named Matrix-Transformation based Low-Rank Adaptation (MTLoRA). MTLoRA aims to dynamically alter its spatial geometric structure by applying a transformation-matrix T to perform linear transformations, such as rotation, scaling, and translation, on the task-specific parameter matrix, generating new matrix feature patterns (eigenvectors) to mimic the fundamental influence of complex geometric structure feature patterns in the brain on functions, thereby enhancing the model's performance in downstream tasks. In Natural Language Understanding (NLU) tasks, it is evaluated using the GLUE benchmark test, and the results reveal that MTLoRA achieves an overall performance increase of about 1.0% across eight tasks; in Natural Language Generation (NLG) tasks, MTLoRA improves performance by an average of 0.95% and 0.56% in the DART and WebNLG tasks, respectively.
STREAM: Social data and knowledge collective intelligence platform for TRaining Ethical AI Models
Oct 09, 2023This paper presents Social data and knowledge collective intelligence platform for TRaining Ethical AI Models (STREAM) to address the challenge of aligning AI models with human moral values, and to provide ethics datasets and knowledge bases to help promote AI models "follow good advice as naturally as a stream follows its course". By creating a comprehensive and representative platform that accurately mirrors the moral judgments of diverse groups including humans and AIs, we hope to effectively portray cultural and group variations, and capture the dynamic evolution of moral judgments over time, which in turn will facilitate the Establishment, Evaluation, Embedding, Embodiment, Ensemble, and Evolvement (6Es) of the moral capabilities of AI models. Currently, STREAM has already furnished a comprehensive collection of ethical scenarios, and amassed substantial moral judgment data annotated by volunteers and various popular Large Language Models (LLMs), collectively portraying the moral preferences and performances of both humans and AIs across a range of moral contexts. This paper will outline the current structure and construction of STREAM, explore its potential applications, and discuss its future prospects.
Improving Robustness of Deep Convolutional Neural Networks via Multiresolution Learning
Sep 28, 2023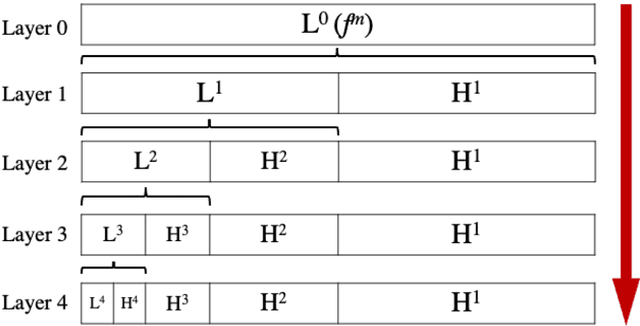
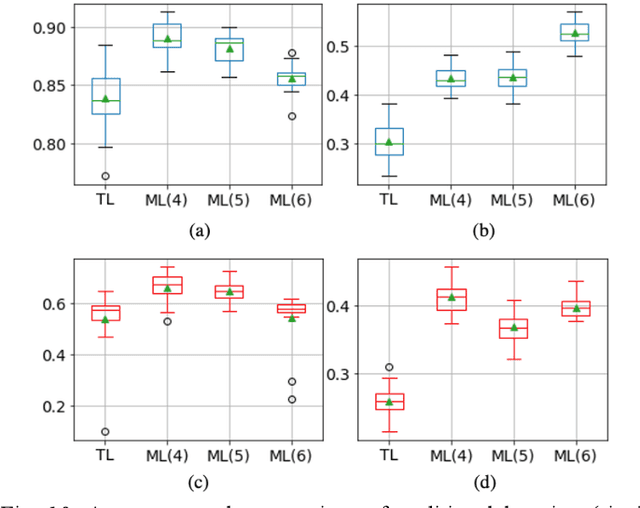
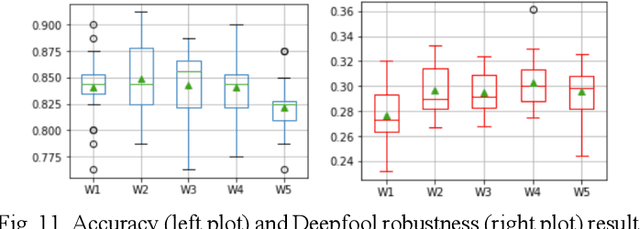
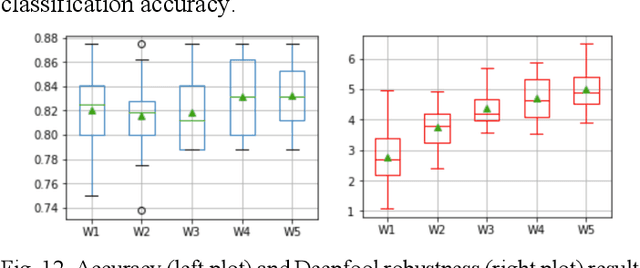
The current learning process of deep learning, regardless of any deep neural network (DNN) architecture and/or learning algorithm used, is essentially a single resolution training. We explore multiresolution learning and show that multiresolution learning can significantly improve robustness of DNN models for both 1D signal and 2D signal (image) prediction problems. We demonstrate this improvement in terms of both noise and adversarial robustness as well as with small training dataset size. Our results also suggest that it may not be necessary to trade standard accuracy for robustness with multiresolution learning, which is, interestingly, contrary to the observation obtained from the traditional single resolution learning setting.
A Brain-inspired Memory Transformation based Differentiable Neural Computer for Reasoning-based Question Answering
Jan 07, 2023Reasoning and question answering as a basic cognitive function for humans, is nevertheless a great challenge for current artificial intelligence. Although the Differentiable Neural Computer (DNC) model could solve such problems to a certain extent, the development is still limited by its high algorithm complexity, slow convergence speed, and poor test robustness. Inspired by the learning and memory mechanism of the brain, this paper proposed a Memory Transformation based Differentiable Neural Computer (MT-DNC) model. MT-DNC incorporates working memory and long-term memory into DNC, and realizes the autonomous transformation of acquired experience between working memory and long-term memory, thereby helping to effectively extract acquired knowledge to improve reasoning ability. Experimental results on bAbI question answering task demonstrated that our proposed method achieves superior performance and faster convergence speed compared to other existing DNN and DNC models. Ablation studies also indicated that the memory transformation from working memory to long-term memory plays essential role in improving the robustness and stability of reasoning. This work explores how brain-inspired memory transformation can be integrated and applied to complex intelligent dialogue and reasoning systems.
Brain-inspired Graph Spiking Neural Networks for Commonsense Knowledge Representation and Reasoning
Jul 11, 2022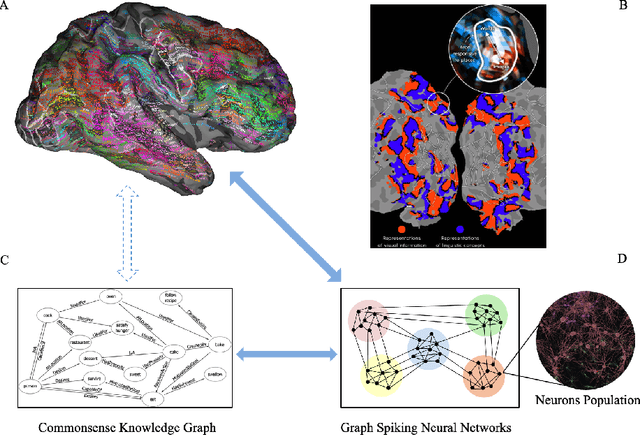
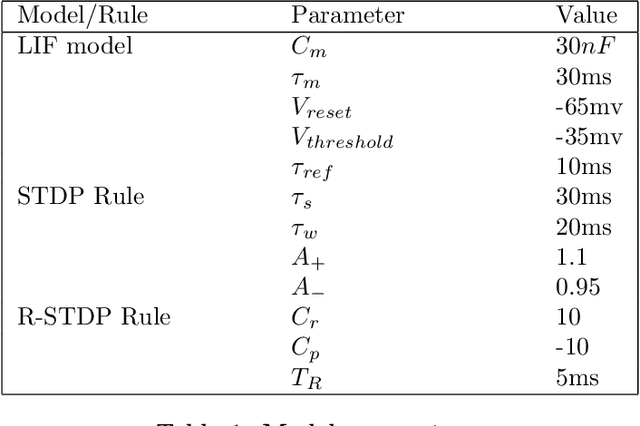
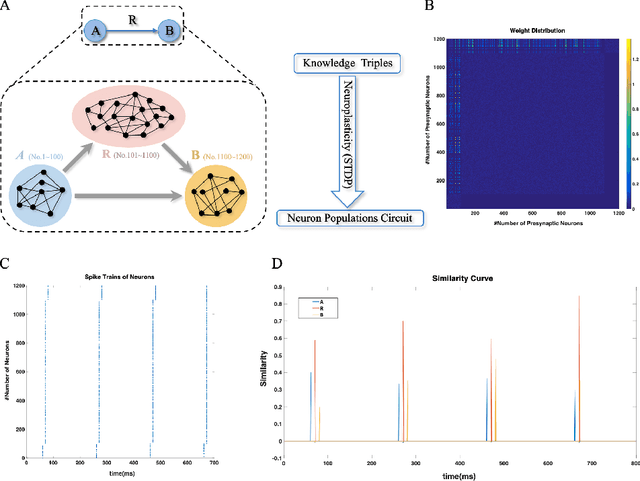
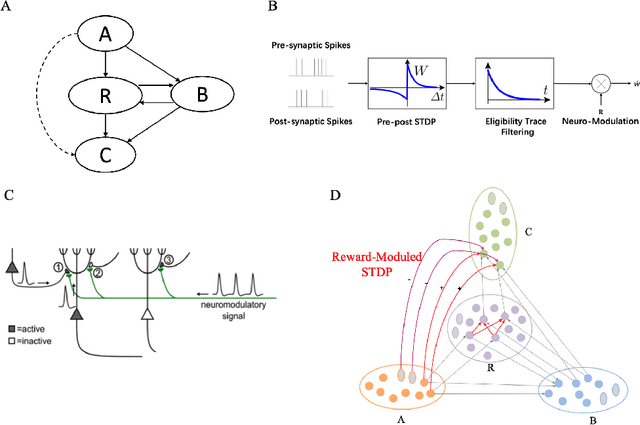
How neural networks in the human brain represent commonsense knowledge, and complete related reasoning tasks is an important research topic in neuroscience, cognitive science, psychology, and artificial intelligence. Although the traditional artificial neural network using fixed-length vectors to represent symbols has gained good performance in some specific tasks, it is still a black box that lacks interpretability, far from how humans perceive the world. Inspired by the grandmother-cell hypothesis in neuroscience, this work investigates how population encoding and spiking timing-dependent plasticity (STDP) mechanisms can be integrated into the learning of spiking neural networks, and how a population of neurons can represent a symbol via guiding the completion of sequential firing between different neuron populations. The neuron populations of different communities together constitute the entire commonsense knowledge graph, forming a giant graph spiking neural network. Moreover, we introduced the Reward-modulated spiking timing-dependent plasticity (R-STDP) mechanism to simulate the biological reinforcement learning process and completed the related reasoning tasks accordingly, achieving comparable accuracy and faster convergence speed than the graph convolutional artificial neural networks. For the fields of neuroscience and cognitive science, the work in this paper provided the foundation of computational modeling for further exploration of the way the human brain represents commonsense knowledge. For the field of artificial intelligence, this paper indicated the exploration direction for realizing a more robust and interpretable neural network by constructing a commonsense knowledge representation and reasoning spiking neural networks with solid biological plausibility.