 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra-slender Coaxial Antagonistic Tubular Robot for Ambidextrous Manipulation
Dec 25, 2024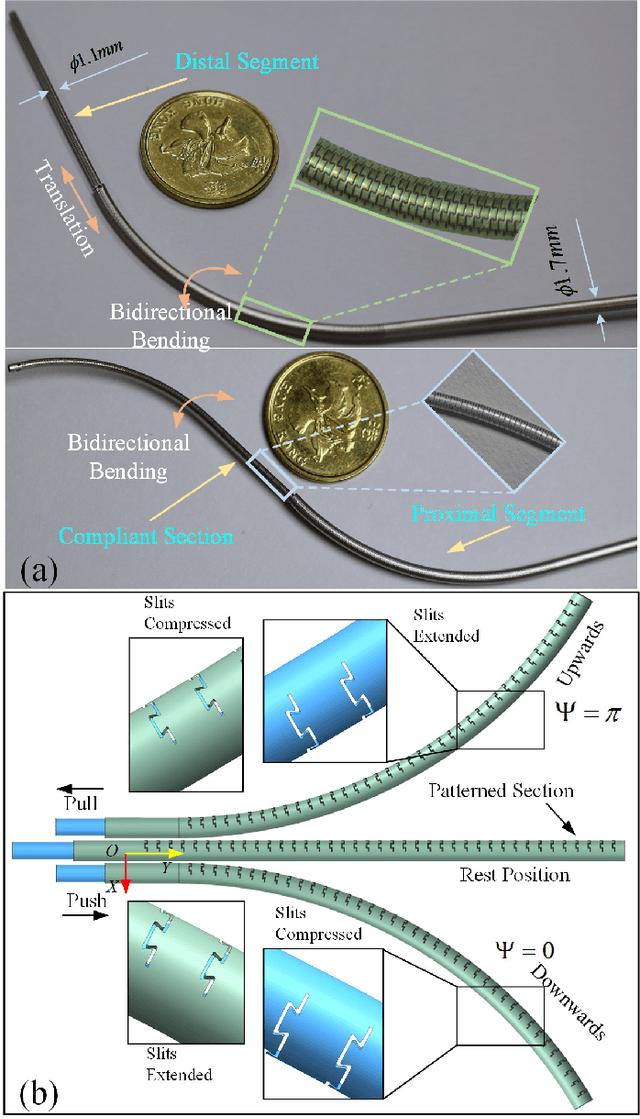


As soft continuum manipulators characterize terrific compliance and maneuverability in narrow unstructured space, low stiffness and limited dexterity are two obvious shortcomings in practical applications. To address the issues, a novel asymmetric coaxial antagonistic tubular robot (CATR) arm with high stiffness has been proposed, where two asymmetrically patterned metal tubes were fixed at the tip end with a shift angle of 180{\deg} and axial actuation force at the other end deforms the tube. Delicately designed and optimized steerable section and fully compliant section enable the soft manipulator high dexterity and stiffness. The basic kinetostatics model of a single segment was established on the basis of geometric and statics, and constrained optimization algorithm promotes finding the actuation inputs for a given desired task configuration. In addition, we have specifically built the design theory for the slits patterned on the tube surface, taking both bending angle and stiffness into account. Experiments demonstrate that the proposed robot arm is dexterous and has greater stiffness compared with same-size continuum robots. Furthermore, experiments also showcase the potential in minimally invasive surgery.
Evaluating the Application of ChatGPT in Outpatient Triage Guidance: A Comparative Study
Apr 27, 2024



The integration of Artificial Intelligence (AI) in healthcare presents a transformative potential for enhancing operational efficiency and health outcomes. Large Language Models (LLMs), such as ChatGPT, have shown their capabilities in supporting medical decision-making. Embedding LLMs in medical systems is becoming a promising trend in healthcare development. The potential of ChatGPT to address the triage problem in emergency departments has been examined, while few studies have explored its application in outpatient departments. With a focus on streamlining workflows and enhancing efficiency for outpatient triage, this study specifically aims to evaluate the consistency of responses provided by ChatGPT in outpatient guidance, including both within-version response analysis and between-version comparisons. For within-version, the results indicate that the internal response consistency for ChatGPT-4.0 is significantly higher than ChatGPT-3.5 (p=0.03) and both have a moderate consistency (71.2% for 4.0 and 59.6% for 3.5) in their top recommendation. However, the between-version consistency is relatively low (mean consistency score=1.43/3, median=1), indicating few recommendations match between the two versions. Also, only 50% top recommendations match perfectly in the comparisons. Interestingly, ChatGPT-3.5 responses are more likely to be complete than those from ChatGPT-4.0 (p=0.02), suggesting possible differences in information processing and response generation between the two versions. The findings offer insights into AI-assisted outpatient operations, while also facilitating the exploration of potentials and limitations of LLMs in healthcare utilization. Future research may focus on carefully optimizing LLMs and AI integration in healthcare systems based on ergonomic and human factors principles, precisely aligning with the specific needs of effective outpatient triage.