 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Features in Language Models: Geometric Characterization and Model Attribution
May 07, 2026Language models exhibit strong robustness to paraphrasing, suggesting that semantic information may be encoded through stable internal representations, yet the structure and origin of such invariance remain unclear. We propose a local geometric framework in which semantically equivalent inputs occupy structured regions in latent space, with paraphrastic variation along nuisance directions and semantic identity preserved in invariant subspaces. Building on this view, we make three contributions: (1) a geometric characterization of invariant latent features, (2) a contrastive subspace discovery method that separates semantic-changing from semantic-preserving variation, and (3) an application of invariant representations to zero-shot model attribution. Across models and layers, empirical results support these contributions. Invariant structure emerges in specific depth regions, semantic displacement lies largely outside the nuisance subspace, and representation-level interventions indicate a causal role of invariant components in model outputs. Invariant representations also capture model-specific geometric patterns, enabling accurate attribution. These findings suggest that semantic invariance can be viewed as a local geometric property of latent representations, offering a principled perspective on how language models organize meaning.
Watermarking Language Models through Language Models
Nov 07, 2024

This paper presents a novel framework for watermarking language models through prompts generated by language models. The proposed approach utilizes a multi-model setup, incorporating a Prompting language model to generate watermarking instructions, a Marking language model to embed watermarks within generated content, and a Detecting language model to verify the presence of these watermarks. Experiments are conducted using ChatGPT and Mistral as the Prompting and Marking language models, with detection accuracy evaluated using a pretrained classifier model. Results demonstrate that the proposed framework achieves high classification accuracy across various configurations, with 95% accuracy for ChatGPT, 88.79% for Mistral. These findings validate the and adaptability of the proposed watermarking strategy across different language model architectures. Hence the proposed framework holds promise for applications in content attribution, copyright protection, and model authentication.
Robust Image Watermarking based on Cross-Attention and Invariant Domain Learning
Oct 09, 2023Image watermarking involves embedding and extracting watermarks within a cover image, with deep learning approaches emerging to bolster generalization and robustness. Predominantly, current methods employ convolution and concatenation for watermark embedding, while also integrating conceivable augmentation in the training process. This paper explores a robust image watermarking methodology by harnessing cross-attention and invariant domain learning, marking two novel, significant advancements. First, we design a watermark embedding technique utilizing a multi-head cross attention mechanism, enabling information exchange between the cover image and watermark to identify semantically suitable embedding locations. Second, we advocate for learning an invariant domain representation that encapsulates both semantic and noise-invariant information concerning the watermark, shedding light on promising avenues for enhancing image watermarking techniques.
Perspective Transformation Layer
Jan 14, 2022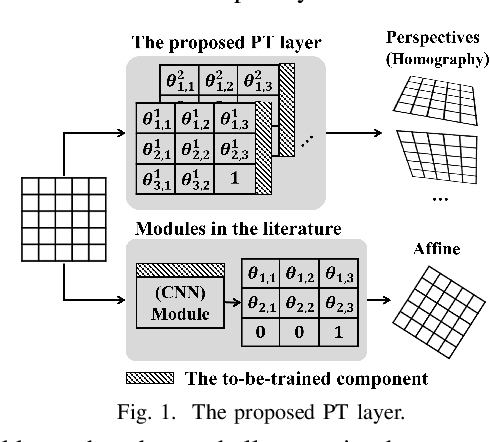

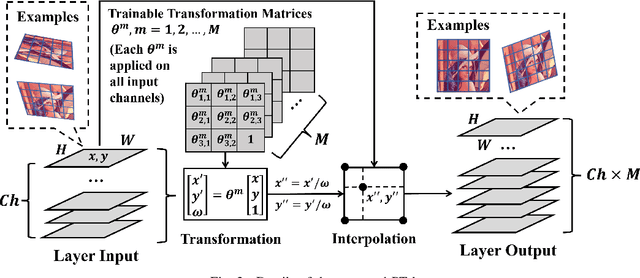
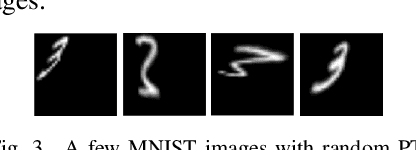
Incorporating geometric transformations that reflect the relative position changes between an observer and an object into computer vision and deep learning models has attracted much attention in recent years. However, the existing proposals mainly focus on affine transformations that cannot fully show viewpoint changes. Furthermore, current solutions often apply a neural network module to learn a single transformation matrix, which ignores the possibility for various viewpoints and creates extra to-be-trained module parameters. In this paper, a layer (PT layer) is proposed to learn the perspective transformations that not only model the geometries in affine transformation but also reflect the viewpoint changes. In addition, being able to be directly trained with gradient descent like traditional layers such as convolutional layers, a single proposed PT layer can learn an adjustable number of multiple viewpoints without training extra module parameters. The experiments and evaluations confirm the superiority of the proposed PT layer.