 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspective Transformation Layer
Paper and Code
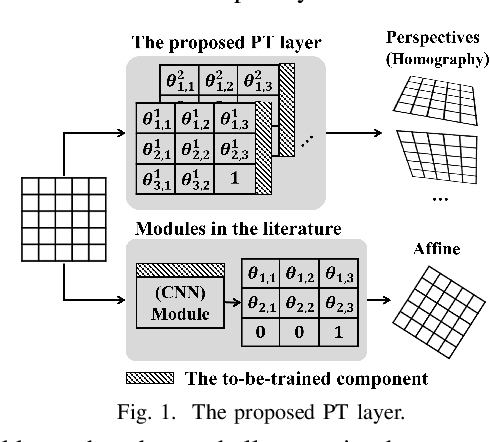

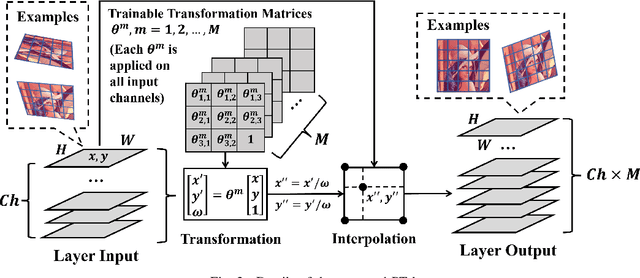
Incorporating geometric transformations that reflect the relative position changes between an observer and an object into computer vision and deep learning models has attracted much attention in recent years. However, the existing proposals mainly focus on affine transformations that cannot fully show viewpoint changes. Furthermore, current solutions often apply a neural network module to learn a single transformation matrix, which ignores the possibility for various viewpoints and creates extra to-be-trained module parameters. In this paper, a layer (PT layer) is proposed to learn the perspective transformations that not only model the geometries in affine transformation but also reflect the viewpoint changes. In addition, being able to be directly trained with gradient descent like traditional layers such as convolutional layers, a single proposed PT layer can learn an adjustable number of multiple viewpoints without training extra module parameters. The experiments and evaluations confirm the superiority of the proposed PT layer.