 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixerSENet: A Lightweight Framework for Efficient Hyperspectral Image Classification
Jun 01, 2026In this paper, a novel framework, MixerSENet, is introduced for hyperspectral image (HSI) classification, designed to address the challenges of computational efficiency and limited labeled data. The proposed model processes hyperspectral image patches while maintaining consistent size and resolution throughout the network, effectively decoupling the mixing of spatial and channel dimensions. Notably, MixerSENet is lightweight and computationally efficient, requiring fewer parameters compared to traditional models, making it suitable for resource-constrained environments. A squeeze and excitation block is incorporated into the model to refine feature extraction, enhancing the network's ability to capture more informative features. Experimental results on two benchmark datasets demonstrate that MixerSENet achieves superior performance, reaching an overall accuracy (OA) of 82.47% on Houston13 dataset and 96.70% on the Qingyun dataset, outperforming state-of-the-art methods including 3D-CNN, HybridKAN, HSIFormer, SimPoolFormer, and MorphMamba. Furthermore, a detailed analysis of computational efficiency shows that MixerSENet achieves a favorable balance between accuracy and efficiency, with only 53,146 parameters and an low inference time, confirming its practicality for real-world applications. At publication, source code will be publicly available at https://github.com/mqalkhatib/MixerSENet.
Decision Support System to triage of liver trauma
Aug 04, 2024



Trauma significantly impacts global health, accounting for over 5 million deaths annually, which is comparable to mortality rates from diseases such as tuberculosis, AIDS, and malaria. In Iran, the financial repercussions of road traffic accidents represent approximately 2% of the nation's Gross National Product each year. Bleeding is the leading cause of mortality in trauma patients within the first 24 hours following an injury, making rapid diagnosis and assessment of severity crucial. Trauma patients require comprehensive scans of all organs, generating a large volume of data. Evaluating CT images for the entire body is time-consuming and requires significant expertise, underscoring the need for efficient time management in diagnosis. Efficient diagnostic processes can significantly reduce treatment costs and decrease the likelihood of secondary complications. In this context, the development of a reliable Decision Support System (DSS) for trauma triage, particularly focused on the abdominal area, is vital. This paper presents a novel method for detecting liver bleeding and lacerations using CT scans, utilising the GAN Pix2Pix translation model. The effectiveness of the method is quantified by Dice score metrics, with the model achieving an accuracy of 97% for liver bleeding and 93% for liver laceration detection. These results represent a notable improvement over current state-of-the-art technologies. The system's design integrates seamlessly with existing medical imaging technologies, making it a practical addition to emergency medical services. This research underscores the potential of advanced image translation models like GAN Pix2Pix in improving the precision and speed of medical diagnostics in critical care scenarios.
How to Learn More? Exploring Kolmogorov-Arnold Networks for Hyperspectral Image Classification
Jun 22, 2024



Convolutional Neural Networks (CNNs) and vision transformers (ViTs) have shown excellent capability in complex hyperspectral image (HSI) classification. However, these models require a significant number of training data and are computational resources. On the other hand, modern Multi-Layer Perceptrons (MLPs) have demonstrated great classification capability. These modern MLP-based models require significantly less training data compared to CNNs and ViTs, achieving the state-of-the-art classification accuracy. Recently, Kolmogorov-Arnold Networks (KANs) were proposed as viable alternatives for MLPs. Because of their internal similarity to splines and their external similarity to MLPs, KANs are able to optimize learned features with remarkable accuracy in addition to being able to learn new features. Thus, in this study, we assess the effectiveness of KANs for complex HSI data classification. Moreover, to enhance the HSI classification accuracy obtained by the KANs, we develop and propose a Hybrid architecture utilizing 1D, 2D, and 3D KANs. To demonstrate the effectiveness of the proposed KAN architecture, we conducted extensive experiments on three newly created HSI benchmark datasets: QUH-Pingan, QUH-Tangdaowan, and QUH-Qingyun. The results underscored the competitive or better capability of the developed hybrid KAN-based model across these benchmark datasets over several other CNN- and ViT-based algorithms, including 1D-CNN, 2DCNN, 3D CNN, VGG-16, ResNet-50, EfficientNet, RNN, and ViT. The code are publicly available at (https://github.com/aj1365/HSIConvKAN)
Spatial Gated Multi-Layer Perceptron for Land Use and Land Cover Mapping
Aug 09, 2023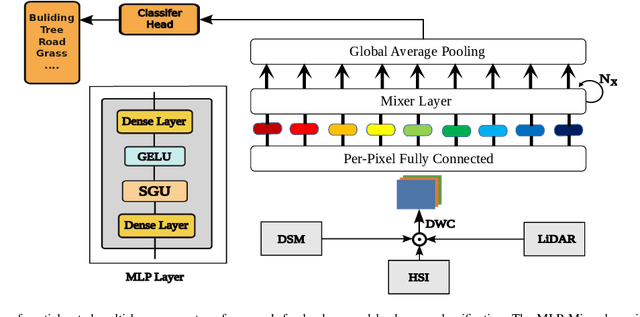
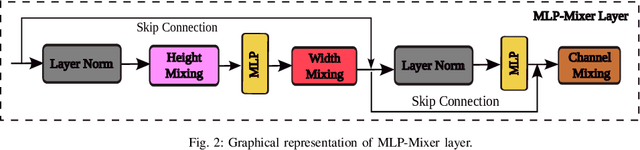

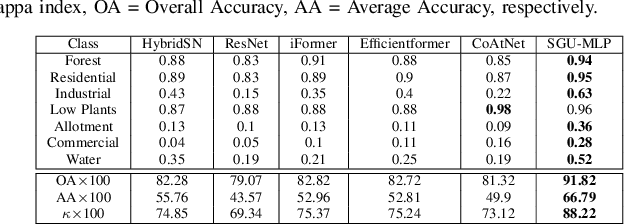
Convolutional Neural Networks (CNNs) are models that are utilized extensively for the hierarchical extraction of features. Vision transformers (ViTs), through the use of a self-attention mechanism, have recently achieved superior modeling of global contextual information compared to CNNs. However, to realize their image classification strength, ViTs require substantial training datasets. Where the available training data are limited, current advanced multi-layer perceptrons (MLPs) can provide viable alternatives to both deep CNNs and ViTs. In this paper, we developed the SGU-MLP, a learning algorithm that effectively uses both MLPs and spatial gating units (SGUs) for precise land use land cover (LULC) mapping. Results illustrated the superiority of the developed SGU-MLP classification algorithm over several CNN and CNN-ViT-based models, including HybridSN, ResNet, iFormer, EfficientFormer and CoAtNet. The proposed SGU-MLP algorithm was tested through three experiments in Houston, USA, Berlin, Germany and Augsburg, Germany. The SGU-MLP classification model was found to consistently outperform the benchmark CNN and CNN-ViT-based algorithms. For example, for the Houston experiment, SGU-MLP significantly outperformed HybridSN, CoAtNet, Efficientformer, iFormer and ResNet by approximately 15%, 19%, 20%, 21%, and 25%, respectively, in terms of average accuracy. The code will be made publicly available at https://github.com/aj1365/SGUMLP
SoilNet: An Attention-based Spatio-temporal Deep Learning Framework for Soil Organic Carbon Prediction with Digital Soil Mapping in Europe
Aug 07, 2023Digital soil mapping (DSM) is an advanced approach that integrates statistical modeling and cutting-edge technologies, including machine learning (ML) methods, to accurately depict soil properties and their spatial distribution. Soil organic carbon (SOC) is a crucial soil attribute providing valuable insights into soil health, nutrient cycling, greenhouse gas emissions, and overall ecosystem productivity. This study highlights the significance of spatial-temporal deep learning (DL) techniques within the DSM framework. A novel architecture is proposed, incorporating spatial information using a base convolutional neural network (CNN) model and spatial attention mechanism, along with climate temporal information using a long short-term memory (LSTM) network, for SOC prediction across Europe. The model utilizes a comprehensive set of environmental features, including Landsat-8 images, topography, remote sensing indices, and climate time series, as input features. Results demonstrate that the proposed framework outperforms conventional ML approaches like random forest commonly used in DSM, yielding lower root mean square error (RMSE). This model is a robust tool for predicting SOC and could be applied to other soil properties, thereby contributing to the advancement of DSM techniques and facilitating land management and decision-making processes based on accurate information.
Neighborhood Attention Makes the Encoder of ResUNet Stronger for Accurate Road Extraction
Jun 08, 2023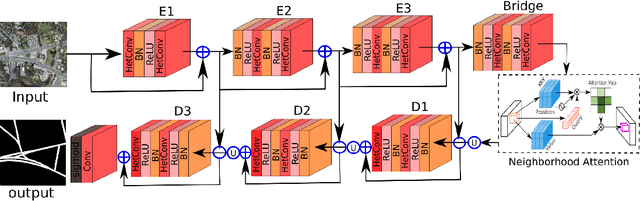


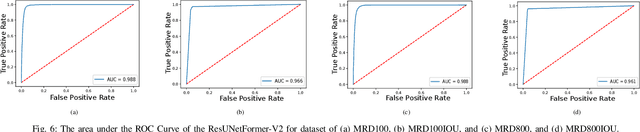
In the domain of remote sensing image interpretation, road extraction from high-resolution aerial imagery has already been a hot research topic. Although deep CNNs have presented excellent results for semantic segmentation, the efficiency and capabilities of vision transformers are yet to be fully researched. As such, for accurate road extraction, a deep semantic segmentation neural network that utilizes the abilities of residual learning, HetConvs, UNet, and vision transformers, which is called \texttt{ResUNetFormer}, is proposed in this letter. The developed \texttt{ResUNetFormer} is evaluated on various cutting-edge deep learning-based road extraction techniques on the public Massachusetts road dataset. Statistical and visual results demonstrate the superiority of the \texttt{ResUNetFormer} over the state-of-the-art CNNs and vision transformers for segmentation. The code will be made available publicly at \url{https://github.com/aj1365/ResUNetFormer}.