 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVServe: Service-Aware KV Cache Compression for Communication-Efficient Disaggregated LLM Serving
May 13, 2026LLMs are widely adopted in production, pushing inference systems to their limits. Disaggregated LLM serving (e.g., PD separation and KV state disaggregation) improves scalability and cost efficiency, but it also turns KV into an explicit payload crossing network and storage boundaries, making KV a dominant end-to-end bottleneck. Existing KV compression are typically static runtime configurations, despite production service context varies over time in workload mix, bandwidth, and SLO/quality budgets. As a result, a fixed choice can be suboptimal or even increase latency. We present \emph{KVServe}, the first service-aware and adaptive KV communication compression framework for disaggregated LLM serving: KVServe (1) unifies KV compression into a modular strategy space with new components and cross-method recomposition; (2) introduces Bayesian Profiling Engine that efficiently searches this space and distills a 3D Pareto candidate set, reducing $50\times$ offline search overhead; and (3) deploys a Service-Aware Online Controller that combines an analytical latency model with a lightweight bandit to select profiles under constraints and correct offline-to-online mismatch. Integrated into vLLM and evaluated across datasets, models, GPUs and networks, KVServe achieves up to $9.13\times$ JCT speedup in PD-separated serving and up to $32.8\times$ TTFT reduction in KV-disaggregated serving.
TACO: Efficient Communication Compression of Intermediate Tensors for Scalable Tensor-Parallel LLM Training
Apr 27, 2026Handling communication overhead in large-scale tensor-parallel training remains a critical challenge due to the dense, near-zero distributions of intermediate tensors, which exacerbate errors under frequent communication and introduce significant computational overhead during compression. To this end, we propose TACO (Tensor-parallel Adaptive COmmunication compression), a robust FP8-based framework for compressing TP intermediate tensors. First, we employ a data-driven reshaping strategy combined with an Adaptive Scale-Hadamard Transform to enable high-fidelity FP8 quantization, while its Dual-Scale Quantization mechanism ensures numerical stability throughout training. Second, we design a highly fused compression operator to reduce memory traffic and kernel launch overhead, allowing efficient overlap with communication. Finally, we integrate TACO with existing state-of-the-art methods for Data and Pipeline Parallelism to develop a compression-enabled 3D-parallel training framework. Detailed experiments on GPT models and Qwen model demonstrate up to 1.87X end-to-end throughput improvement while maintaining near-lossless accuracy, validating the effectiveness and efficiency of TACO in large-scale training.
GreenHyperSpectra: A multi-source hyperspectral dataset for global vegetation trait prediction
Jul 09, 2025Plant traits such as leaf carbon content and leaf mass are essential variables in the study of biodiversity and climate change. However, conventional field sampling cannot feasibly cover trait variation at ecologically meaningful spatial scales. Machine learning represents a valuable solution for plant trait prediction across ecosystems, leveraging hyperspectral data from remote sensing. Nevertheless, trait prediction from hyperspectral data is challenged by label scarcity and substantial domain shifts (\eg across sensors, ecological distributions), requiring robust cross-domain methods. Here, we present GreenHyperSpectra, a pretraining dataset encompassing real-world cross-sensor and cross-ecosystem samples designed to benchmark trait prediction with semi- and self-supervised methods. We adopt an evaluation framework encompassing in-distribution and out-of-distribution scenarios. We successfully leverage GreenHyperSpectra to pretrain label-efficient multi-output regression models that outperform the state-of-the-art supervised baseline. Our empirical analyses demonstrate substantial improvements in learning spectral representations for trait prediction, establishing a comprehensive methodological framework to catalyze research at the intersection of representation learning and plant functional traits assessment. All code and data are available at: https://github.com/echerif18/HyspectraSSL.
How to Learn More? Exploring Kolmogorov-Arnold Networks for Hyperspectral Image Classification
Jun 22, 2024



Convolutional Neural Networks (CNNs) and vision transformers (ViTs) have shown excellent capability in complex hyperspectral image (HSI) classification. However, these models require a significant number of training data and are computational resources. On the other hand, modern Multi-Layer Perceptrons (MLPs) have demonstrated great classification capability. These modern MLP-based models require significantly less training data compared to CNNs and ViTs, achieving the state-of-the-art classification accuracy. Recently, Kolmogorov-Arnold Networks (KANs) were proposed as viable alternatives for MLPs. Because of their internal similarity to splines and their external similarity to MLPs, KANs are able to optimize learned features with remarkable accuracy in addition to being able to learn new features. Thus, in this study, we assess the effectiveness of KANs for complex HSI data classification. Moreover, to enhance the HSI classification accuracy obtained by the KANs, we develop and propose a Hybrid architecture utilizing 1D, 2D, and 3D KANs. To demonstrate the effectiveness of the proposed KAN architecture, we conducted extensive experiments on three newly created HSI benchmark datasets: QUH-Pingan, QUH-Tangdaowan, and QUH-Qingyun. The results underscored the competitive or better capability of the developed hybrid KAN-based model across these benchmark datasets over several other CNN- and ViT-based algorithms, including 1D-CNN, 2DCNN, 3D CNN, VGG-16, ResNet-50, EfficientNet, RNN, and ViT. The code are publicly available at (https://github.com/aj1365/HSIConvKAN)
Decision-making for Autonomous Vehicles on Highway: Deep Reinforcement Learning with Continuous Action Horizon
Aug 26, 2020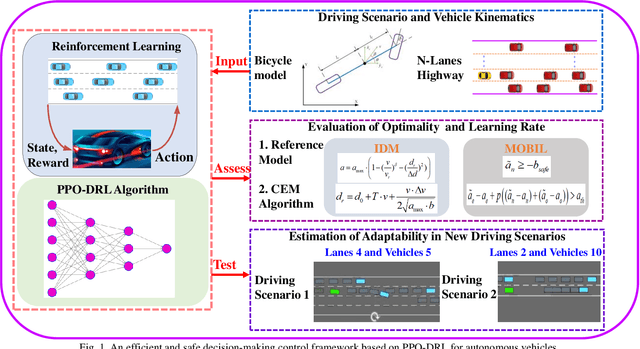

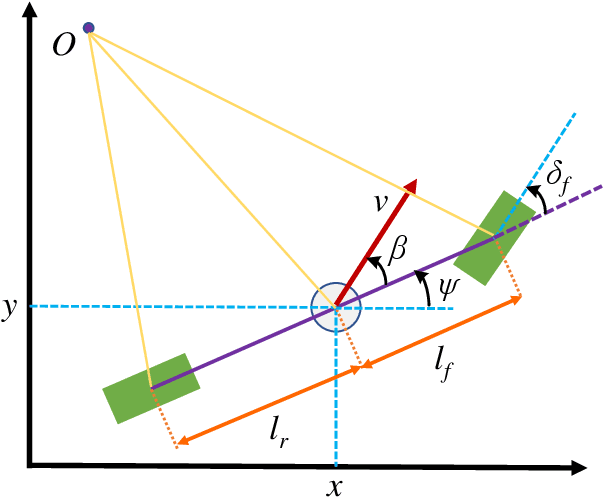
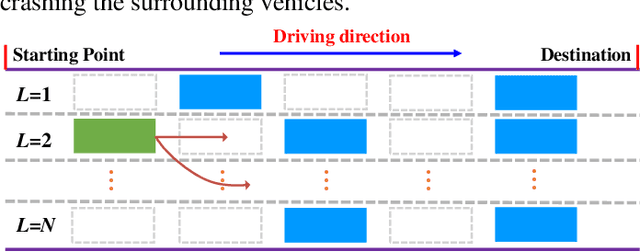
Decision-making strategy for autonomous vehicles de-scribes a sequence of driving maneuvers to achieve a certain navigational mission. This paper utilizes the deep reinforcement learning (DRL) method to address the continuous-horizon decision-making problem on the highway. First, the vehicle kinematics and driving scenario on the freeway are introduced. The running objective of the ego automated vehicle is to execute an efficient and smooth policy without collision. Then, the particular algorithm named proximal policy optimization (PPO)-enhanced DRL is illustrated. To overcome the challenges in tardy training efficiency and sample inefficiency, this applied algorithm could realize high learning efficiency and excellent control performance. Finally, the PPO-DRL-based decision-making strategy is estimated from multiple perspectives, including the optimality, learning efficiency, and adaptability. Its potential for online application is discussed by applying it to similar driving scenarios.