Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCFormer: One-Class Transformer Network for Image Classification
Paper and Code
Apr 25, 2022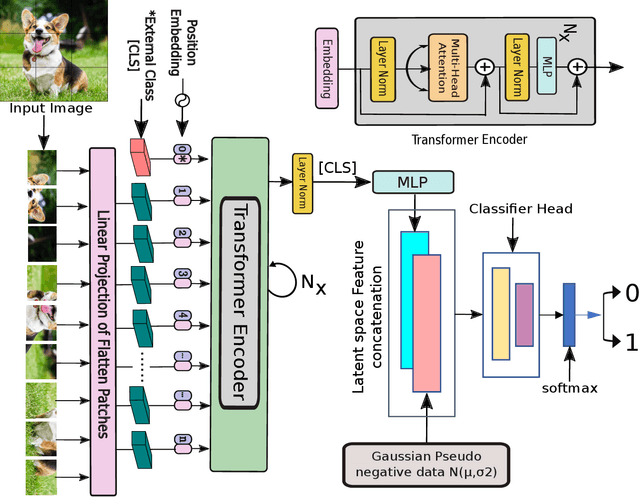

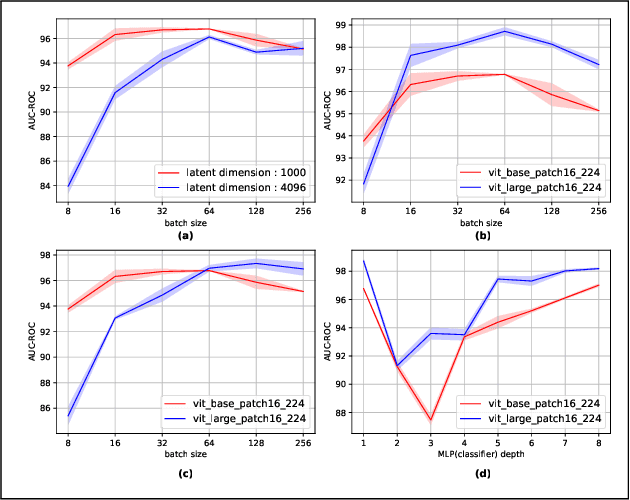
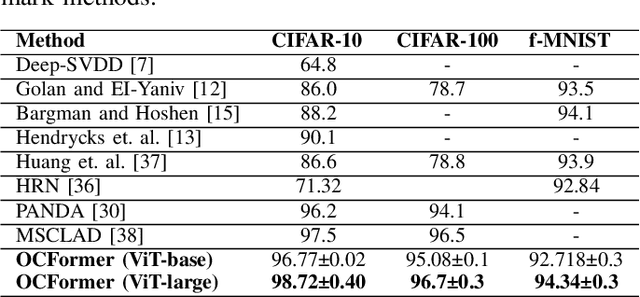
We propose a novel deep learning framework based on Vision Transformers (ViT) for one-class classification. The core idea is to use zero-centered Gaussian noise as a pseudo-negative class for latent space representation and then train the network using the optimal loss function. In prior works, there have been tremendous efforts to learn a good representation using varieties of loss functions, which ensures both discriminative and compact properties. The proposed one-class Vision Transformer (OCFormer) is exhaustively experimented on CIFAR-10, CIFAR-100, Fashion-MNIST and CelebA eyeglasses datasets. Our method has shown significant improvements over competing CNN based one-class classifier approaches.
View paper on