 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffSTR: Controlled Diffusion Models for Scene Text Removal
Oct 29, 2024To prevent unauthorized use of text in images, Scene Text Removal (STR) has become a crucial task. It focuses on automatically removing text and replacing it with a natural, text-less background while preserving significant details such as texture, color, and contrast. Despite its importance in privacy protection, STR faces several challenges, including boundary artifacts, inconsistent texture and color, and preserving correct shadows. Most STR approaches estimate a text region mask to train a model, solving for image translation or inpainting to generate a text-free image. Thus, the quality of the generated image depends on the accuracy of the inpainting mask and the generator's capability. In this work, we leverage the superior capabilities of diffusion models in generating high-quality, consistent images to address the STR problem. We introduce a ControlNet diffusion model, treating STR as an inpainting task. To enhance the model's robustness, we develop a mask pretraining pipeline to condition our diffusion model. This involves training a masked autoencoder (MAE) using a combination of box masks and coarse stroke masks, and fine-tuning it using masks derived from our novel segmentation-based mask refinement framework. This framework iteratively refines an initial mask and segments it using the SLIC and Hierarchical Feature Selection (HFS) algorithms to produce an accurate final text mask. This improves mask prediction and utilizes rich textural information in natural scene images to provide accurate inpainting masks. Experiments on the SCUT-EnsText and SCUT-Syn datasets demonstrate that our method significantly outperforms existing state-of-the-art techniques.
GraVITON: Graph based garment warping with attention guided inversion for Virtual-tryon
Jun 04, 2024Virtual try-on, a rapidly evolving field in computer vision, is transforming e-commerce by improving customer experiences through precise garment warping and seamless integration onto the human body. While existing methods such as TPS and flow address the garment warping but overlook the finer contextual details. In this paper, we introduce a novel graph based warping technique which emphasizes the value of context in garment flow. Our graph based warping module generates warped garment as well as a coarse person image, which is utilised by a simple refinement network to give a coarse virtual tryon image. The proposed work exploits latent diffusion model to generate the final tryon, treating garment transfer as an inpainting task. The diffusion model is conditioned with decoupled cross attention based inversion of visual and textual information. We introduce an occlusion aware warping constraint that generates dense warped garment, without any holes and occlusion. Our method, validated on VITON-HD and Dresscode datasets, showcases substantial state-of-the-art qualitative and quantitative results showing considerable improvement in garment warping, texture preservation, and overall realism.
Single Stage Warped Cloth Learning and Semantic-Contextual Attention Feature Fusion for Virtual TryOn
Oct 08, 2023Image-based virtual try-on aims to fit an in-shop garment onto a clothed person image. Garment warping, which aligns the target garment with the corresponding body parts in the person image, is a crucial step in achieving this goal. Existing methods often use multi-stage frameworks to handle clothes warping, person body synthesis and tryon generation separately or rely on noisy intermediate parser-based labels. We propose a novel single-stage framework that implicitly learns the same without explicit multi-stage learning. Our approach utilizes a novel semantic-contextual fusion attention module for garment-person feature fusion, enabling efficient and realistic cloth warping and body synthesis from target pose keypoints. By introducing a lightweight linear attention framework that attends to garment regions and fuses multiple sampled flow fields, we also address misalignment and artifacts present in previous methods. To achieve simultaneous learning of warped garment and try-on results, we introduce a Warped Cloth Learning Module. WCLM uses segmented warped garments as ground truth, operating within a single-stage paradigm. Our proposed approach significantly improves the quality and efficiency of virtual try-on methods, providing users with a more reliable and realistic virtual try-on experience. We evaluate our method on the VITON dataset and demonstrate its state-of-the-art performance in terms of both qualitative and quantitative metrics.
MaskMTL: Attribute prediction in masked facial images with deep multitask learning
Jan 11, 2022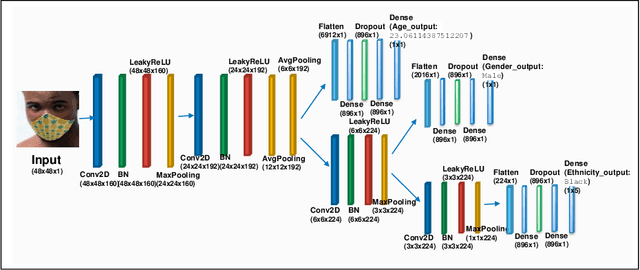
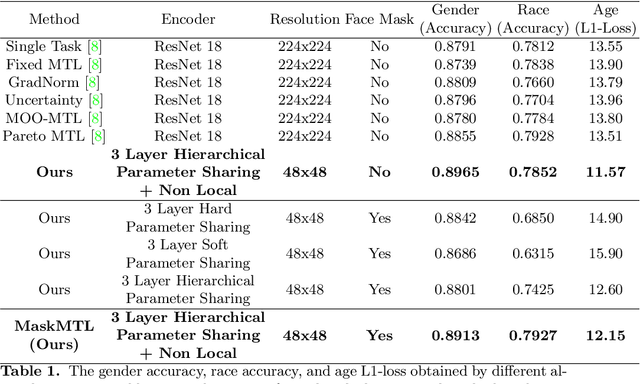

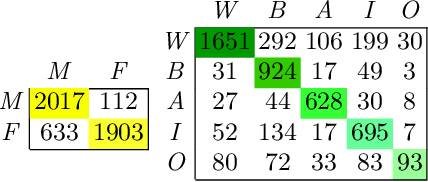
Predicting attributes in the landmark free facial images is itself a challenging task which gets further complicated when the face gets occluded due to the usage of masks. Smart access control gates which utilize identity verification or the secure login to personal electronic gadgets may utilize face as a biometric trait. Particularly, the Covid-19 pandemic increasingly validates the essentiality of hygienic and contactless identity verification. In such cases, the usage of masks become more inevitable and performing attribute prediction helps in segregating the target vulnerable groups from community spread or ensuring social distancing for them in a collaborative environment. We create a masked face dataset by efficiently overlaying masks of different shape, size and textures to effectively model variability generated by wearing mask. This paper presents a deep Multi-Task Learning (MTL) approach to jointly estimate various heterogeneous attributes from a single masked facial image. Experimental results on benchmark face attribute UTKFace dataset demonstrate that the proposed approach supersedes in performance to other competing techniques. The source code is available at https://github.com/ritikajha/Attribute-prediction-in-masked-facial-images-with-deep-multitask-learning
ADAADepth: Adapting Data Augmentation and Attention for Self-Supervised Monocular Depth Estimation
Mar 01, 2021
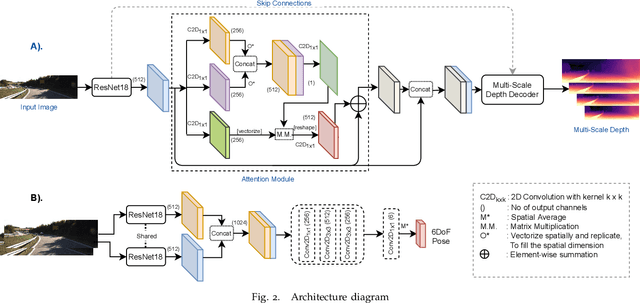

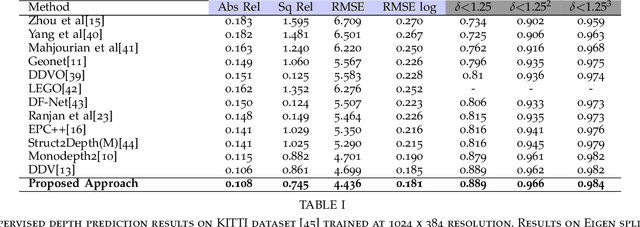
Self-supervised learning of depth has been a highly studied topic of research as it alleviates the requirement of having ground truth annotations for predicting depth. Depth is learnt as an intermediate solution to the task of view synthesis, utilising warped photometric consistency. Although it gives good results when trained using stereo data, the predicted depth is still sensitive to noise, illumination changes and specular reflections. Also, occlusion can be tackled better by learning depth from a single camera. We propose ADAA, utilising depth augmentation as depth supervision for learning accurate and robust depth. We propose a relational self-attention module that learns rich contextual features and further enhances depth results. We also optimize the auto-masking strategy across all losses by enforcing L1 regularisation over mask. Our novel progressive training strategy first learns depth at a lower resolution and then progresses to the original resolution with slight training. We utilise a ResNet18 encoder, learning features for prediction of both depth and pose. We evaluate our predicted depth on the standard KITTI driving dataset and achieve state-of-the-art results for monocular depth estimation whilst having significantly lower number of trainable parameters in our deep learning framework. We also evaluate our model on Make3D dataset showing better generalization than other methods.
Deep feature fusion for self-supervised monocular depth prediction
May 16, 2020


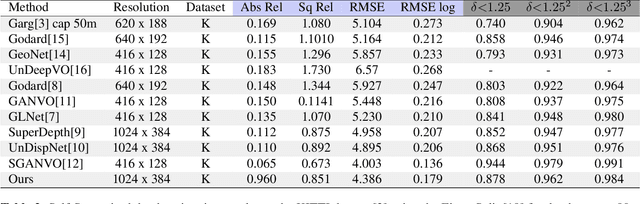
Recent advances in end-to-end unsupervised learning has significantly improved the performance of monocular depth prediction and alleviated the requirement of ground truth depth. Although a plethora of work has been done in enforcing various structural constraints by incorporating multiple losses utilising smoothness, left-right consistency, regularisation and matching surface normals, a few of them take into consideration multi-scale structures present in real world images. Most works utilise a VGG16 or ResNet50 model pre-trained on ImageNet weights for predicting depth. We propose a deep feature fusion method utilising features at multiple scales for learning self-supervised depth from scratch. Our fusion network selects features from both upper and lower levels at every level in the encoder network, thereby creating multiple feature pyramid sub-networks that are fed to the decoder after applying the CoordConv solution. We also propose a refinement module learning higher scale residual depth from a combination of higher level deep features and lower level residual depth using a pixel shuffling framework that super-resolves lower level residual depth. We select the KITTI dataset for evaluation and show that our proposed architecture can produce better or comparable results in depth prediction.
Aerial multi-object tracking by detection using deep association networks
Sep 04, 2019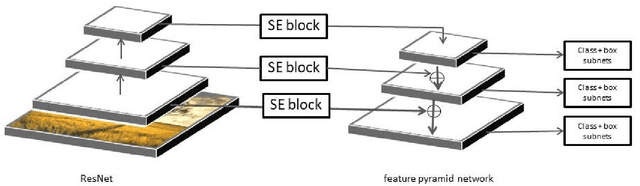
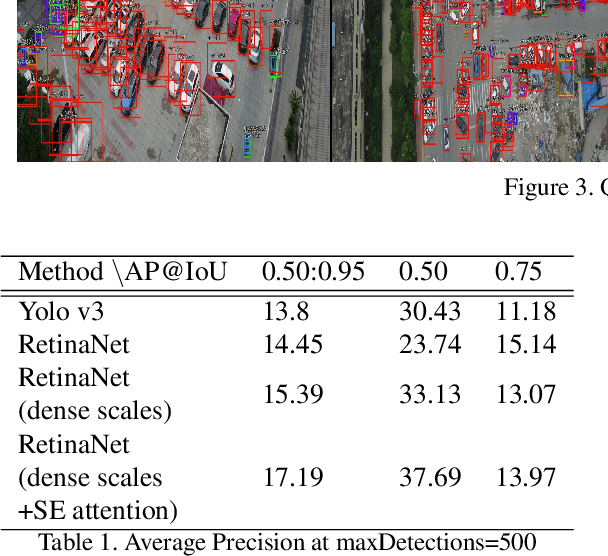

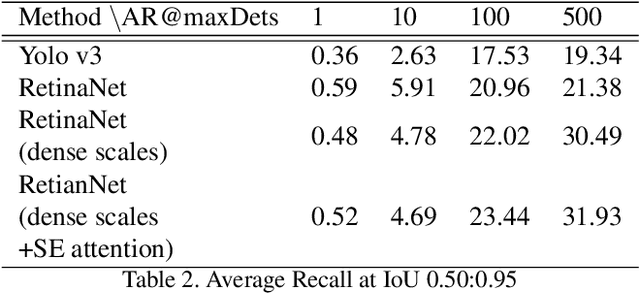
A lot a research is focused on object detection and it has achieved significant advances with deep learning techniques in recent years. Inspite of the existing research, these algorithms are not usually optimal for dealing with sequences or images captured by drone-based platforms, due to various challenges such as view point change, scales, density of object distribution and occlusion. In this paper, we develop a model for detection of objects in drone images using the VisDrone2019 DET dataset. Using the RetinaNet model as our base, we modify the anchor scales to better handle the detection of dense distribution and small size of the objects. We explicitly model the channel interdependencies by using "Squeeze-and-Excitation" (SE) blocks that adaptively recalibrates channel-wise feature responses. This helps to bring significant improvements in performance at a slight additional computational cost. Using this architecture for object detection, we build a custom DeepSORT network for object detection on the VisDrone2019 MOT dataset by training a custom Deep Association network for the algorithm.
Fast Hierarchical Depth Map Computation from Stereo
Jan 28, 2019


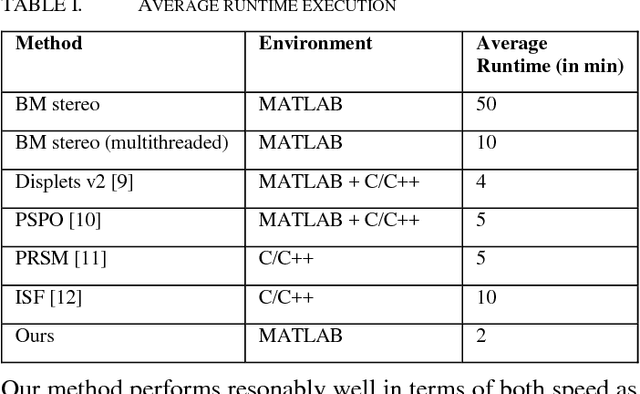
Disparity by Block Matching stereo is usually used in applications with limited computational power in order to get depth estimates. However, the research on simple stereo methods has been lesser than the energy based counterparts which promise a better quality depth map with more potential for future improvements. Semi-global-matching (SGM) methods offer good performance and easy implementation but suffer from the problem of very high memory footprint because it's working on the full disparity space image. On the other hand, Block matching stereo needs much less memory. In this paper, we introduce a novel multi-scale-hierarchical block-matching approach using a pyramidal variant of depth and cost functions which drastically improves the results of standard block matching stereo techniques while preserving the low memory footprint and further reducing the complexity of standard block matching. We tested our new multi block matching scheme on the Middlebury stereo benchmark. For the Middlebury benchmark we get results that are only slightly worse than state of the art SGM implementations.
Nrityantar: Pose oblivious Indian classical dance sequence classification system
Dec 13, 2018
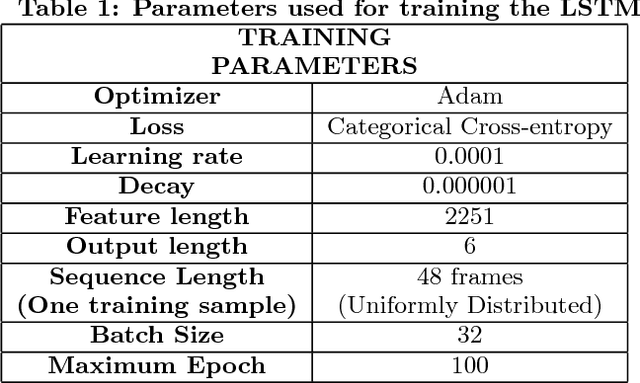


In this paper, we attempt to advance the research work done in human action recognition to a rather specialized application namely Indian Classical Dance (ICD) classification. The variation in such dance forms in terms of hand and body postures, facial expressions or emotions and head orientation makes pose estimation an extremely challenging task. To circumvent this problem, we construct a pose-oblivious shape signature which is fed to a sequence learning framework. The pose signature representation is done in two-fold process. First, we represent person-pose in first frame of a dance video using symmetric Spatial Transformer Networks (STN) to extract good person object proposals and CNN-based parallel single person pose estimator (SPPE). Next, the pose basis are converted to pose flows by assigning a similarity score between successive poses followed by non-maximal suppression. Instead of feeding a simple chain of joints in the sequence learner which generally hinders the network performance we constitute a feature vector of the normalized distance vectors, flow, angles between anchor joints which captures the adjacency configuration in the skeletal pattern. Thus, the kinematic relationship amongst the body joints across the frames using pose estimation helps in better establishing the spatio-temporal dependencies. We present an exhaustive empirical evaluation of state-of-the-art deep network based methods for dance classification on ICD dataset.