 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAADepth: Adapting Data Augmentation and Attention for Self-Supervised Monocular Depth Estimation
Paper and Code
Mar 01, 2021
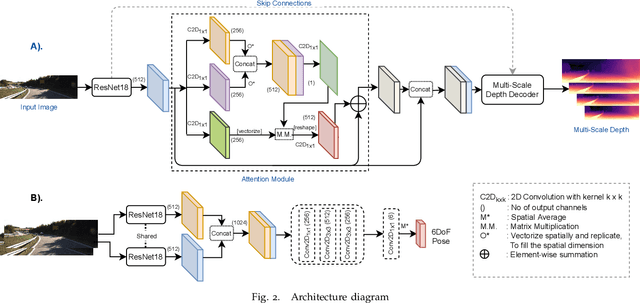

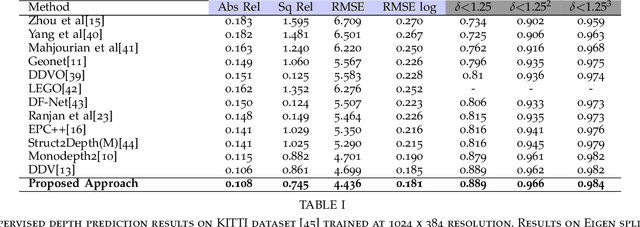
Self-supervised learning of depth has been a highly studied topic of research as it alleviates the requirement of having ground truth annotations for predicting depth. Depth is learnt as an intermediate solution to the task of view synthesis, utilising warped photometric consistency. Although it gives good results when trained using stereo data, the predicted depth is still sensitive to noise, illumination changes and specular reflections. Also, occlusion can be tackled better by learning depth from a single camera. We propose ADAA, utilising depth augmentation as depth supervision for learning accurate and robust depth. We propose a relational self-attention module that learns rich contextual features and further enhances depth results. We also optimize the auto-masking strategy across all losses by enforcing L1 regularisation over mask. Our novel progressive training strategy first learns depth at a lower resolution and then progresses to the original resolution with slight training. We utilise a ResNet18 encoder, learning features for prediction of both depth and pose. We evaluate our predicted depth on the standard KITTI driving dataset and achieve state-of-the-art results for monocular depth estimation whilst having significantly lower number of trainable parameters in our deep learning framework. We also evaluate our model on Make3D dataset showing better generalization than other methods.