 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffSTR: Controlled Diffusion Models for Scene Text Removal
Oct 29, 2024To prevent unauthorized use of text in images, Scene Text Removal (STR) has become a crucial task. It focuses on automatically removing text and replacing it with a natural, text-less background while preserving significant details such as texture, color, and contrast. Despite its importance in privacy protection, STR faces several challenges, including boundary artifacts, inconsistent texture and color, and preserving correct shadows. Most STR approaches estimate a text region mask to train a model, solving for image translation or inpainting to generate a text-free image. Thus, the quality of the generated image depends on the accuracy of the inpainting mask and the generator's capability. In this work, we leverage the superior capabilities of diffusion models in generating high-quality, consistent images to address the STR problem. We introduce a ControlNet diffusion model, treating STR as an inpainting task. To enhance the model's robustness, we develop a mask pretraining pipeline to condition our diffusion model. This involves training a masked autoencoder (MAE) using a combination of box masks and coarse stroke masks, and fine-tuning it using masks derived from our novel segmentation-based mask refinement framework. This framework iteratively refines an initial mask and segments it using the SLIC and Hierarchical Feature Selection (HFS) algorithms to produce an accurate final text mask. This improves mask prediction and utilizes rich textural information in natural scene images to provide accurate inpainting masks. Experiments on the SCUT-EnsText and SCUT-Syn datasets demonstrate that our method significantly outperforms existing state-of-the-art techniques.
GraVITON: Graph based garment warping with attention guided inversion for Virtual-tryon
Jun 04, 2024
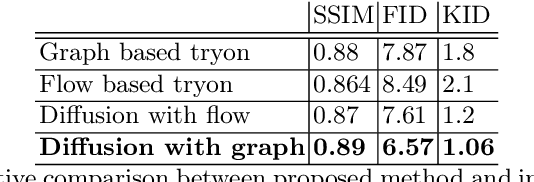
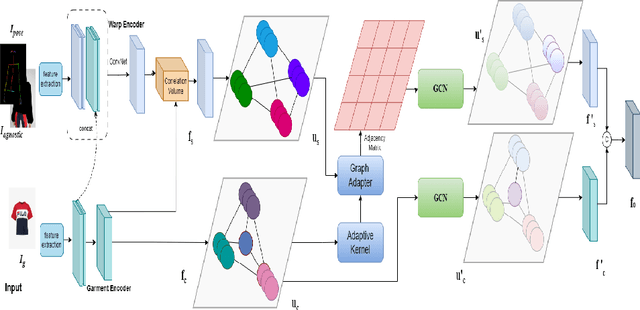

Virtual try-on, a rapidly evolving field in computer vision, is transforming e-commerce by improving customer experiences through precise garment warping and seamless integration onto the human body. While existing methods such as TPS and flow address the garment warping but overlook the finer contextual details. In this paper, we introduce a novel graph based warping technique which emphasizes the value of context in garment flow. Our graph based warping module generates warped garment as well as a coarse person image, which is utilised by a simple refinement network to give a coarse virtual tryon image. The proposed work exploits latent diffusion model to generate the final tryon, treating garment transfer as an inpainting task. The diffusion model is conditioned with decoupled cross attention based inversion of visual and textual information. We introduce an occlusion aware warping constraint that generates dense warped garment, without any holes and occlusion. Our method, validated on VITON-HD and Dresscode datasets, showcases substantial state-of-the-art qualitative and quantitative results showing considerable improvement in garment warping, texture preservation, and overall realism.
Single Stage Warped Cloth Learning and Semantic-Contextual Attention Feature Fusion for Virtual TryOn
Oct 08, 2023



Image-based virtual try-on aims to fit an in-shop garment onto a clothed person image. Garment warping, which aligns the target garment with the corresponding body parts in the person image, is a crucial step in achieving this goal. Existing methods often use multi-stage frameworks to handle clothes warping, person body synthesis and tryon generation separately or rely on noisy intermediate parser-based labels. We propose a novel single-stage framework that implicitly learns the same without explicit multi-stage learning. Our approach utilizes a novel semantic-contextual fusion attention module for garment-person feature fusion, enabling efficient and realistic cloth warping and body synthesis from target pose keypoints. By introducing a lightweight linear attention framework that attends to garment regions and fuses multiple sampled flow fields, we also address misalignment and artifacts present in previous methods. To achieve simultaneous learning of warped garment and try-on results, we introduce a Warped Cloth Learning Module. WCLM uses segmented warped garments as ground truth, operating within a single-stage paradigm. Our proposed approach significantly improves the quality and efficiency of virtual try-on methods, providing users with a more reliable and realistic virtual try-on experience. We evaluate our method on the VITON dataset and demonstrate its state-of-the-art performance in terms of both qualitative and quantitative metrics.