 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep feature fusion for self-supervised monocular depth prediction
Paper and Code
May 16, 2020


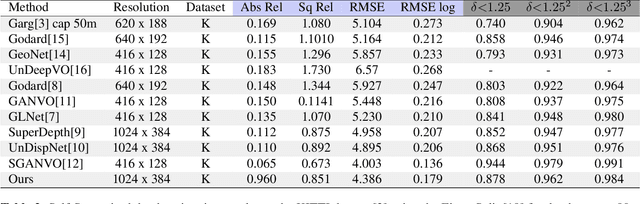
Recent advances in end-to-end unsupervised learning has significantly improved the performance of monocular depth prediction and alleviated the requirement of ground truth depth. Although a plethora of work has been done in enforcing various structural constraints by incorporating multiple losses utilising smoothness, left-right consistency, regularisation and matching surface normals, a few of them take into consideration multi-scale structures present in real world images. Most works utilise a VGG16 or ResNet50 model pre-trained on ImageNet weights for predicting depth. We propose a deep feature fusion method utilising features at multiple scales for learning self-supervised depth from scratch. Our fusion network selects features from both upper and lower levels at every level in the encoder network, thereby creating multiple feature pyramid sub-networks that are fed to the decoder after applying the CoordConv solution. We also propose a refinement module learning higher scale residual depth from a combination of higher level deep features and lower level residual depth using a pixel shuffling framework that super-resolves lower level residual depth. We select the KITTI dataset for evaluation and show that our proposed architecture can produce better or comparable results in depth prediction.