 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoFormer: A Vision and Sequence Transformer-based Approach for Greenhouse Gas Monitoring
Feb 11, 2024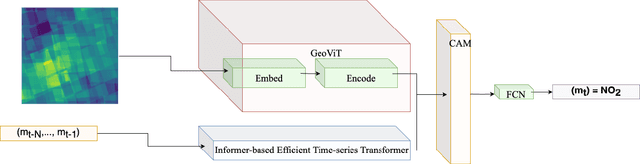
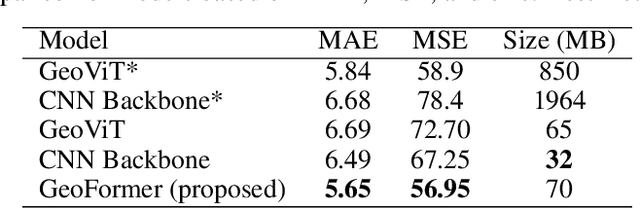
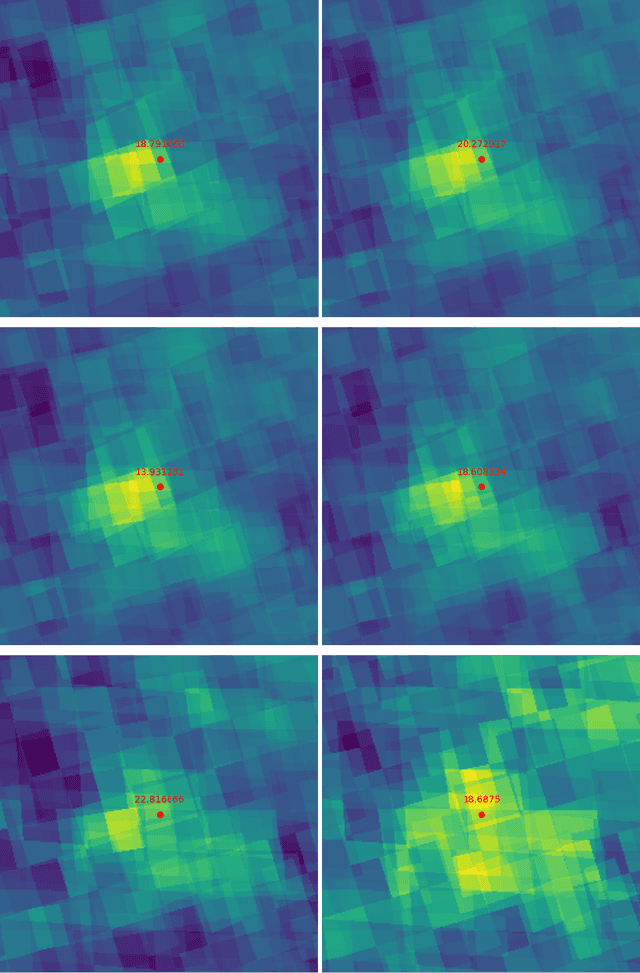
Air pollution represents a pivotal environmental challenge globally, playing a major role in climate change via greenhouse gas emissions and negatively affecting the health of billions. However predicting the spatial and temporal patterns of pollutants remains challenging. The scarcity of ground-based monitoring facilities and the dependency of air pollution modeling on comprehensive datasets, often inaccessible for numerous areas, complicate this issue. In this work, we introduce GeoFormer, a compact model that combines a vision transformer module with a highly efficient time-series transformer module to predict surface-level nitrogen dioxide (NO2) concentrations from Sentinel-5P satellite imagery. We train the proposed model to predict surface-level NO2 measurements using a dataset we constructed with Sentinel-5P images of ground-level monitoring stations, and their corresponding NO2 concentration readings. The proposed model attains high accuracy (MAE 5.65), demonstrating the efficacy of combining vision and time-series transformer architectures to harness satellite-derived data for enhanced GHG emission insights, proving instrumental in advancing climate change monitoring and emission regulation efforts globally.
GeoViT: A Versatile Vision Transformer Architecture for Geospatial Image Analysis
Nov 24, 2023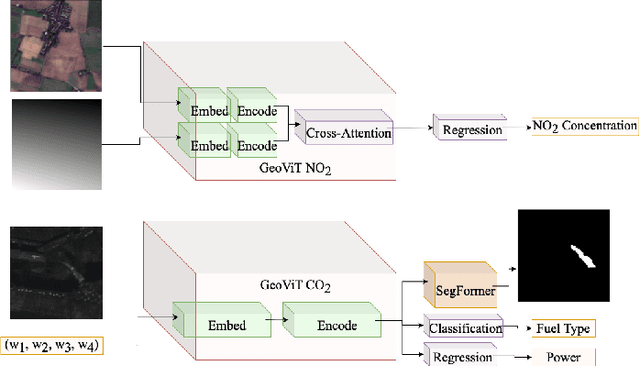
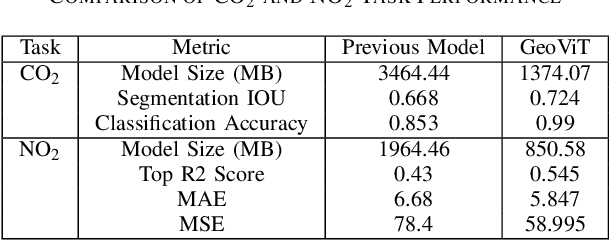
Greenhouse gases are pivotal drivers of climate change, necessitating precise quantification and source identification to foster mitigation strategies. We introduce GeoViT, a compact vision transformer model adept in processing satellite imagery for multimodal segmentation, classification, and regression tasks targeting CO2 and NO2 emissions. Leveraging GeoViT, we attain superior accuracy in estimating power generation rates, fuel type, plume coverage for CO2, and high-resolution NO2 concentration mapping, surpassing previous state-of-the-art models while significantly reducing model size. GeoViT demonstrates the efficacy of vision transformer architectures in harnessing satellite-derived data for enhanced GHG emission insights, proving instrumental in advancing climate change monitoring and emission regulation efforts globally.
Style Description based Text-to-Speech with Conditional Prosodic Layer Normalization based Diffusion GAN
Oct 27, 2023In this paper, we present a Diffusion GAN based approach (Prosodic Diff-TTS) to generate the corresponding high-fidelity speech based on the style description and content text as an input to generate speech samples within only 4 denoising steps. It leverages the novel conditional prosodic layer normalization to incorporate the style embeddings into the multi head attention based phoneme encoder and mel spectrogram decoder based generator architecture to generate the speech. The style embedding is generated by fine tuning the pretrained BERT model on auxiliary tasks such as pitch, speaking speed, emotion,gender classifications. We demonstrate the efficacy of our proposed architecture on multi-speaker LibriTTS and PromptSpeech datasets, using multiple quantitative metrics that measure generated accuracy and MOS.
KL Regularized Normalization Framework for Low Resource Tasks
Dec 21, 2022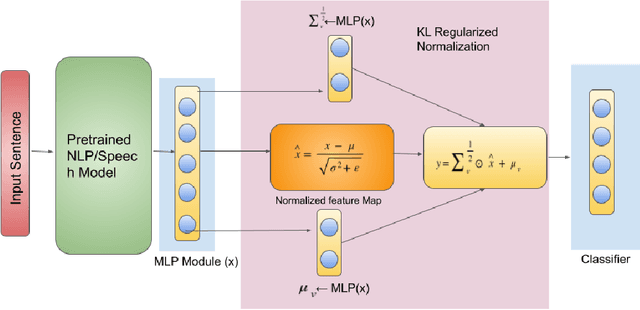
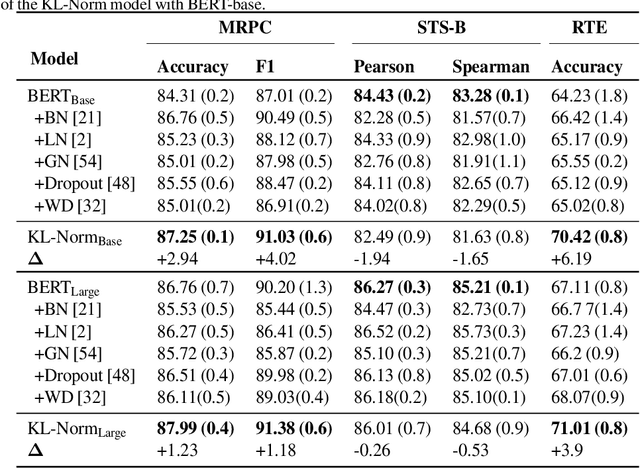
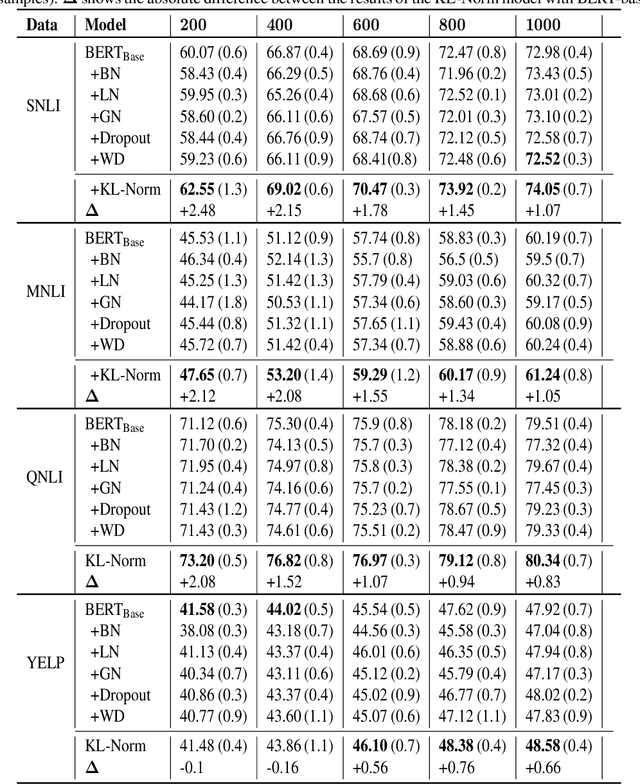
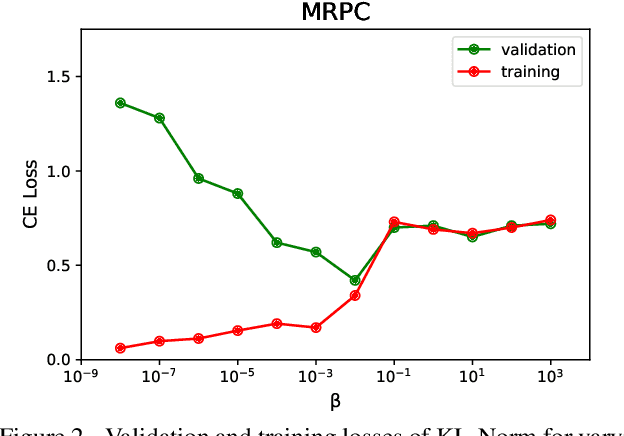
Large pre-trained models, such as Bert, GPT, and Wav2Vec, have demonstrated great potential for learning representations that are transferable to a wide variety of downstream tasks . It is difficult to obtain a large quantity of supervised data due to the limited availability of resources and time. In light of this, a significant amount of research has been conducted in the area of adopting large pre-trained datasets for diverse downstream tasks via fine tuning, linear probing, or prompt tuning in low resource settings. Normalization techniques are essential for accelerating training and improving the generalization of deep neural networks and have been successfully used in a wide variety of applications. A lot of normalization techniques have been proposed but the success of normalization in low resource downstream NLP and speech tasks is limited. One of the reasons is the inability to capture expressiveness by rescaling parameters of normalization. We propose KullbackLeibler(KL) Regularized normalization (KL-Norm) which make the normalized data well behaved and helps in better generalization as it reduces over-fitting, generalises well on out of domain distributions and removes irrelevant biases and features with negligible increase in model parameters and memory overheads. Detailed experimental evaluation on multiple low resource NLP and speech tasks, demonstrates the superior performance of KL-Norm as compared to other popular normalization and regularization techniques.
One Shot Audio to Animated Video Generation
Feb 19, 2021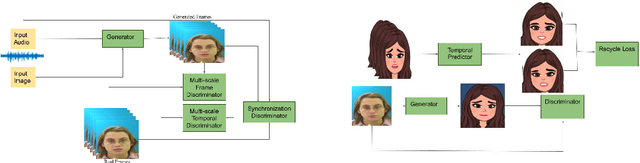


We consider the challenging problem of audio to animated video generation. We propose a novel method OneShotAu2AV to generate an animated video of arbitrary length using an audio clip and a single unseen image of a person as an input. The proposed method consists of two stages. In the first stage, OneShotAu2AV generates the talking-head video in the human domain given an audio and a person's image. In the second stage, the talking-head video from the human domain is converted to the animated domain. The model architecture of the first stage consists of spatially adaptive normalization based multi-level generator and multiple multilevel discriminators along with multiple adversarial and non-adversarial losses. The second stage leverages attention based normalization driven GAN architecture along with temporal predictor based recycle loss and blink loss coupled with lipsync loss, for unsupervised generation of animated video. In our approach, the input audio clip is not restricted to any specific language, which gives the method multilingual applicability. OneShotAu2AV can generate animated videos that have: (a) lip movements that are in sync with the audio, (b) natural facial expressions such as blinks and eyebrow movements, (c) head movements. Experimental evaluation demonstrates superior performance of OneShotAu2AV as compared to U-GAT-IT and RecycleGan on multiple quantitative metrics including KID(Kernel Inception Distance), Word error rate, blinks/sec
Robust One Shot Audio to Video Generation
Dec 14, 2020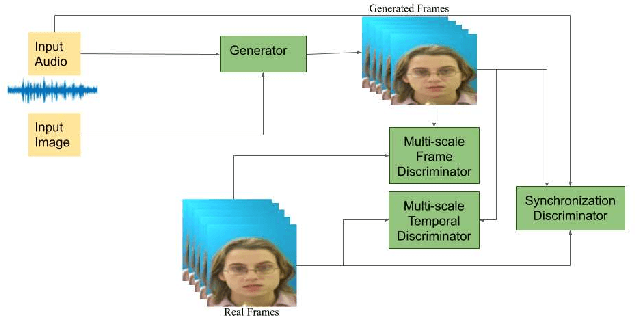
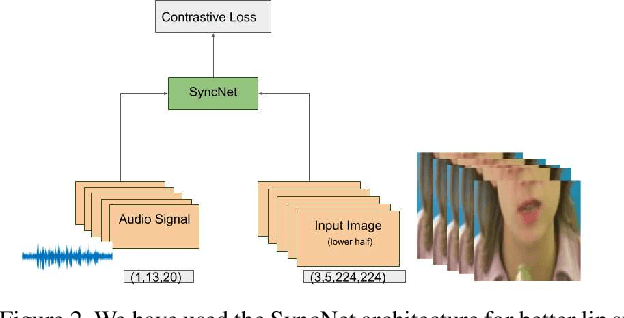

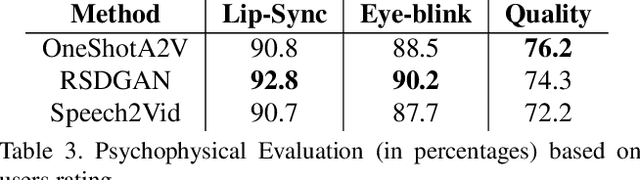
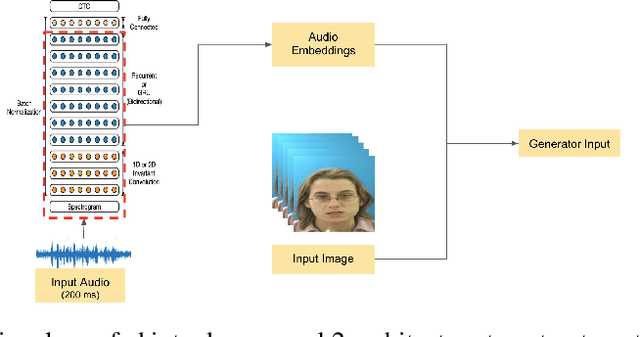
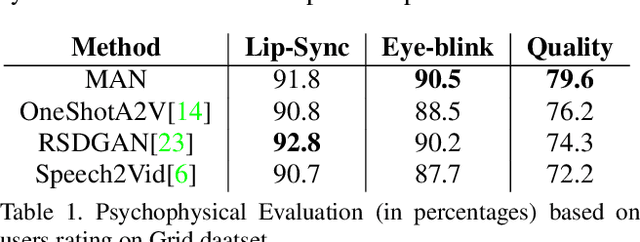
Audio to Video generation is an interesting problem that has numerous applications across industry verticals including film making, multi-media, marketing, education and others. High-quality video generation with expressive facial movements is a challenging problem that involves complex learning steps for generative adversarial networks. Further, enabling one-shot learning for an unseen single image increases the complexity of the problem while simultaneously making it more applicable to practical scenarios. In the paper, we propose a novel approach OneShotA2V to synthesize a talking person video of arbitrary length using as input: an audio signal and a single unseen image of a person. OneShotA2V leverages curriculum learning to learn movements of expressive facial components and hence generates a high-quality talking-head video of the given person. Further, it feeds the features generated from the audio input directly into a generative adversarial network and it adapts to any given unseen selfie by applying fewshot learning with only a few output updation epochs. OneShotA2V leverages spatially adaptive normalization based multi-level generator and multiple multi-level discriminators based architecture. The input audio clip is not restricted to any specific language, which gives the method multilingual applicability. Experimental evaluation demonstrates superior performance of OneShotA2V as compared to Realistic Speech-Driven Facial Animation with GANs(RSDGAN) [43], Speech2Vid [8], and other approaches, on multiple quantitative metrics including: SSIM (structural similarity index), PSNR (peak signal to noise ratio) and CPBD (image sharpness). Further, qualitative evaluation and Online Turing tests demonstrate the efficacy of our approach.
Multi Modal Adaptive Normalization for Audio to Video Generation
Dec 14, 2020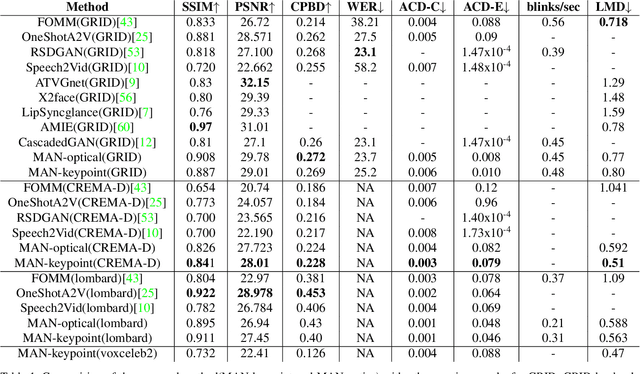

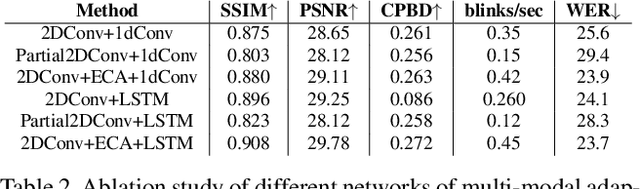
Speech-driven facial video generation has been a complex problem due to its multi-modal aspects namely audio and video domain. The audio comprises lots of underlying features such as expression, pitch, loudness, prosody(speaking style) and facial video has lots of variability in terms of head movement, eye blinks, lip synchronization and movements of various facial action units along with temporal smoothness. Synthesizing highly expressive facial videos from the audio input and static image is still a challenging task for generative adversarial networks. In this paper, we propose a multi-modal adaptive normalization(MAN) based architecture to synthesize a talking person video of arbitrary length using as input: an audio signal and a single image of a person. The architecture uses the multi-modal adaptive normalization, keypoint heatmap predictor, optical flow predictor and class activation map[58] based layers to learn movements of expressive facial components and hence generates a highly expressive talking-head video of the given person. The multi-modal adaptive normalization uses the various features of audio and video such as Mel spectrogram, pitch, energy from audio signals and predicted keypoint heatmap/optical flow and a single image to learn the respective affine parameters to generate highly expressive video. Experimental evaluation demonstrates superior performance of the proposed method as compared to Realistic Speech-Driven Facial Animation with GANs(RSDGAN) [53], Speech2Vid [10], and other approaches, on multiple quantitative metrics including: SSIM (structural similarity index), PSNR (peak signal to noise ratio), CPBD (image sharpness), WER(word error rate), blinks/sec and LMD(landmark distance). Further, qualitative evaluation and Online Turing tests demonstrate the efficacy of our approach.
Few Shot Adaptive Normalization Driven Multi-Speaker Speech Synthesis
Dec 14, 2020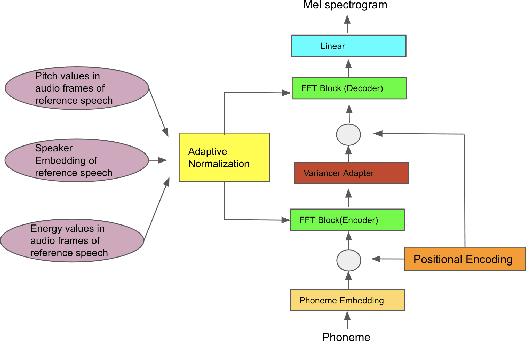

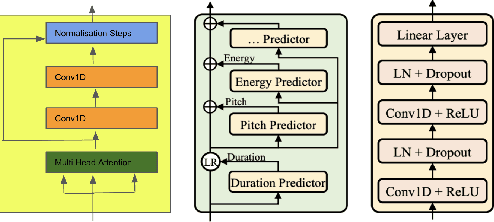
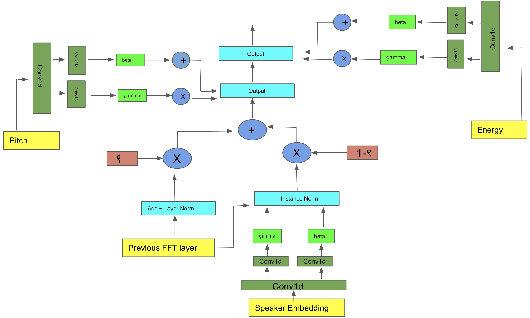
The style of the speech varies from person to person and every person exhibits his or her own style of speaking that is determined by the language, geography, culture and other factors. Style is best captured by prosody of a signal. High quality multi-speaker speech synthesis while considering prosody and in a few shot manner is an area of active research with many real-world applications. While multiple efforts have been made in this direction, it remains an interesting and challenging problem. In this paper, we present a novel few shot multi-speaker speech synthesis approach (FSM-SS) that leverages adaptive normalization architecture with a non-autoregressive multi-head attention model. Given an input text and a reference speech sample of an unseen person, FSM-SS can generate speech in that person's style in a few shot manner. Additionally, we demonstrate how the affine parameters of normalization help in capturing the prosodic features such as energy and fundamental frequency in a disentangled fashion and can be used to generate morphed speech output. We demonstrate the efficacy of our proposed architecture on multi-speaker VCTK and LibriTTS datasets, using multiple quantitative metrics that measure generated speech distortion and MoS, along with speaker embedding analysis of the generated speech vs the actual speech samples.
CatFedAvg: Optimising Communication-efficiency and Classification Accuracy in Federated Learning
Nov 14, 2020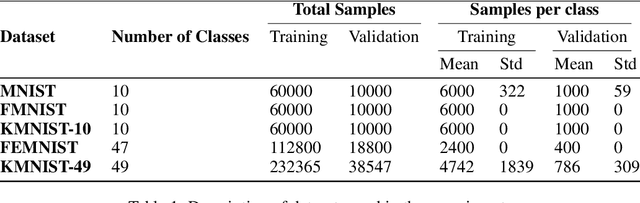
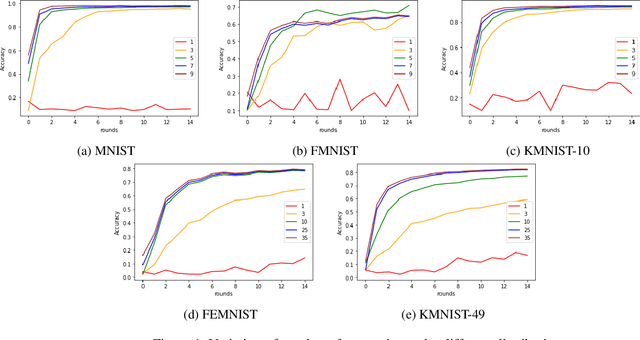

Federated learning has allowed the training of statistical models over remote devices without the transfer of raw client data. In practice, training in heterogeneous and large networks introduce novel challenges in various aspects like network load, quality of client data, security and privacy. Recent works in FL have worked on improving communication efficiency and addressing uneven client data distribution independently, but none have provided a unified solution for both challenges. We introduce a new family of Federated Learning algorithms called CatFedAvg which not only improves the communication efficiency but improves the quality of learning using a category coverage maximization strategy. We use the FedAvg framework and introduce a simple and efficient step every epoch to collect meta-data about the client's training data structure which the central server uses to request a subset of weight updates. We explore two distinct variations which allow us to further explore the tradeoffs between communication efficiency and model accuracy. Our experiments based on a vision classification task have shown that an increase of 10% absolute points in accuracy using the MNIST dataset with 70% absolute points lower network transfer over FedAvg. We also run similar experiments with Fashion MNIST, KMNIST-10, KMNIST-49 and EMNIST-47. Further, under extreme data imbalance experiments for both globally and individual clients, we see the model performing better than FedAvg. The ablation study further explores its behaviour under varying data and client parameter conditions showcasing the robustness of the proposed approach.
Fed-Focal Loss for imbalanced data classification in Federated Learning
Nov 12, 2020
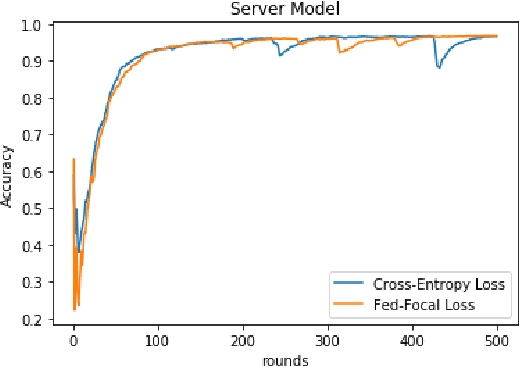
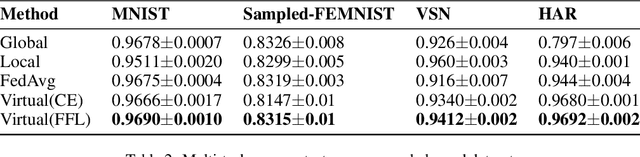

The Federated Learning setting has a central server coordinating the training of a model on a network of devices. One of the challenges is variable training performance when the dataset has a class imbalance. In this paper, we address this by introducing a new loss function called Fed-Focal Loss. We propose to address the class imbalance by reshaping cross-entropy loss such that it down-weights the loss assigned to well-classified examples along the lines of focal loss. Additionally, by leveraging a tunable sampling framework, we take into account selective client model contributions on the central server to further focus the detector during training and hence improve its robustness. Using a detailed experimental analysis with the VIRTUAL (Variational Federated Multi-Task Learning) approach, we demonstrate consistently superior performance in both the balanced and unbalanced scenarios for MNIST, FEMNIST, VSN and HAR benchmarks. We obtain a more than 9% (absolute percentage) improvement in the unbalanced MNIST benchmark. We further show that our technique can be adopted across multiple Federated Learning algorithms to get improvements.