 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Knowledge Sea: Planet-scale answer retrieval using LLMs
Feb 07, 2024Information retrieval is a rapidly evolving field of information retrieval, which is characterized by a continuous refinement of techniques and technologies, from basic hyperlink-based navigation to sophisticated algorithm-driven search engines. This paper aims to provide a comprehensive overview of the evolution of Information Retrieval Technology, with a particular focus on the role of Large Language Models (LLMs) in bridging the gap between traditional search methods and the emerging paradigm of answer retrieval. The integration of LLMs in the realms of response retrieval and indexing signifies a paradigm shift in how users interact with information systems. This paradigm shift is driven by the integration of large language models (LLMs) like GPT-4, which are capable of understanding and generating human-like text, thus enabling them to provide more direct and contextually relevant answers to user queries. Through this exploration, we seek to illuminate the technological milestones that have shaped this journey and the potential future directions in this rapidly changing field.
Viz: A QLoRA-based Copyright Marketplace for Legally Compliant Generative AI
Dec 31, 2023This paper aims to introduce and analyze the Viz system in a comprehensive way, a novel system architecture that integrates Quantized Low-Rank Adapters (QLoRA) to fine-tune large language models (LLM) within a legally compliant and resource efficient marketplace. Viz represents a significant contribution to the field of artificial intelligence, particularly in addressing the challenges of computational efficiency, legal compliance, and economic sustainability in the utilization and monetization of LLMs. The paper delineates the scholarly discourse and developments that have informed the creation of Viz, focusing primarily on the advancements in LLM models, copyright issues in AI training (NYT case, 2023), and the evolution of model fine-tuning techniques, particularly low-rank adapters and quantized low-rank adapters, to create a sustainable and economically compliant framework for LLM utilization. The economic model it proposes benefits content creators, AI developers, and end-users, delineating a harmonious integration of technology, economy, and law, offering a comprehensive solution to the complex challenges of today's AI landscape.
TSO: Curriculum Generation using continuous optimization
Jun 16, 2021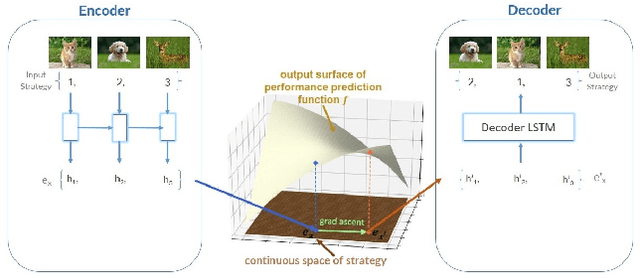
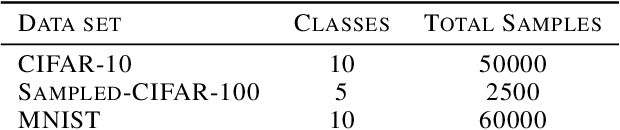


The training of deep learning models poses vast challenges of including parameter tuning and ordering of training data. Significant research has been done in Curriculum learning for optimizing the sequence of training data. Recent works have focused on using complex reinforcement learning techniques to find the optimal data ordering strategy to maximize learning for a given network. In this paper, we present a simple and efficient technique based on continuous optimization. We call this new approach Training Sequence Optimization (TSO). There are three critical components in our proposed approach: (a) An encoder network maps/embeds training sequence into continuous space. (b) A predictor network uses the continuous representation of a strategy as input and predicts the accuracy for fixed network architecture. (c) A decoder further maps a continuous representation of a strategy to the ordered training dataset. The performance predictor and encoder enable us to perform gradient-based optimization in the continuous space to find the embedding of optimal training data ordering with potentially better accuracy. Experiments show that we can gain 2AP with our generated optimal curriculum strategy over the random strategy using the CIFAR-100 dataset and have better boosts than the state of the art CL algorithms. We do an ablation study varying the architecture, dataset and sample sizes showcasing our approach's robustness.
One Shot Audio to Animated Video Generation
Feb 19, 2021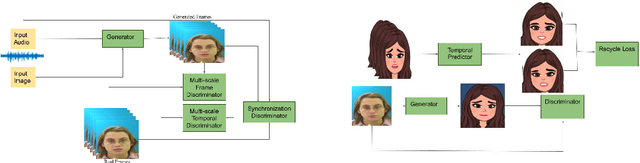
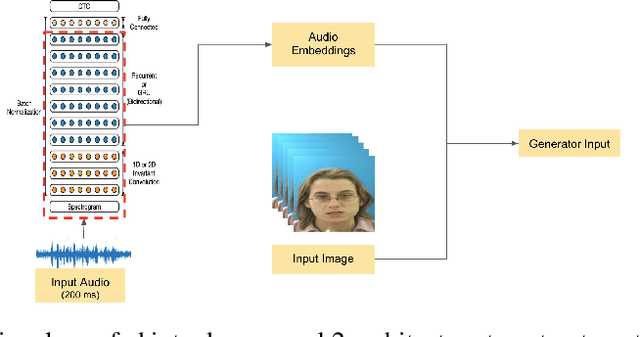


We consider the challenging problem of audio to animated video generation. We propose a novel method OneShotAu2AV to generate an animated video of arbitrary length using an audio clip and a single unseen image of a person as an input. The proposed method consists of two stages. In the first stage, OneShotAu2AV generates the talking-head video in the human domain given an audio and a person's image. In the second stage, the talking-head video from the human domain is converted to the animated domain. The model architecture of the first stage consists of spatially adaptive normalization based multi-level generator and multiple multilevel discriminators along with multiple adversarial and non-adversarial losses. The second stage leverages attention based normalization driven GAN architecture along with temporal predictor based recycle loss and blink loss coupled with lipsync loss, for unsupervised generation of animated video. In our approach, the input audio clip is not restricted to any specific language, which gives the method multilingual applicability. OneShotAu2AV can generate animated videos that have: (a) lip movements that are in sync with the audio, (b) natural facial expressions such as blinks and eyebrow movements, (c) head movements. Experimental evaluation demonstrates superior performance of OneShotAu2AV as compared to U-GAT-IT and RecycleGan on multiple quantitative metrics including KID(Kernel Inception Distance), Word error rate, blinks/sec
CatFedAvg: Optimising Communication-efficiency and Classification Accuracy in Federated Learning
Nov 14, 2020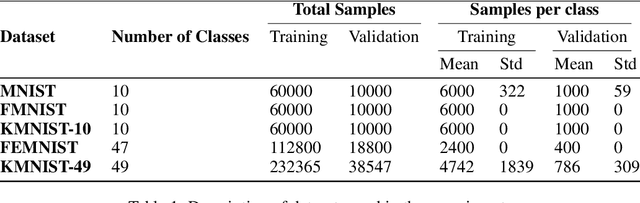
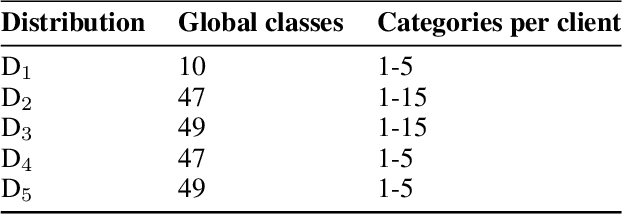
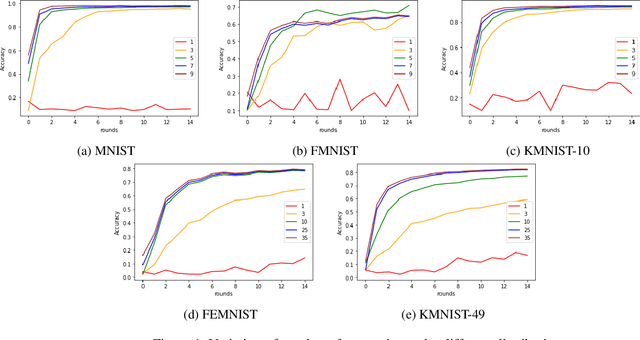

Federated learning has allowed the training of statistical models over remote devices without the transfer of raw client data. In practice, training in heterogeneous and large networks introduce novel challenges in various aspects like network load, quality of client data, security and privacy. Recent works in FL have worked on improving communication efficiency and addressing uneven client data distribution independently, but none have provided a unified solution for both challenges. We introduce a new family of Federated Learning algorithms called CatFedAvg which not only improves the communication efficiency but improves the quality of learning using a category coverage maximization strategy. We use the FedAvg framework and introduce a simple and efficient step every epoch to collect meta-data about the client's training data structure which the central server uses to request a subset of weight updates. We explore two distinct variations which allow us to further explore the tradeoffs between communication efficiency and model accuracy. Our experiments based on a vision classification task have shown that an increase of 10% absolute points in accuracy using the MNIST dataset with 70% absolute points lower network transfer over FedAvg. We also run similar experiments with Fashion MNIST, KMNIST-10, KMNIST-49 and EMNIST-47. Further, under extreme data imbalance experiments for both globally and individual clients, we see the model performing better than FedAvg. The ablation study further explores its behaviour under varying data and client parameter conditions showcasing the robustness of the proposed approach.
Fed-Focal Loss for imbalanced data classification in Federated Learning
Nov 12, 2020
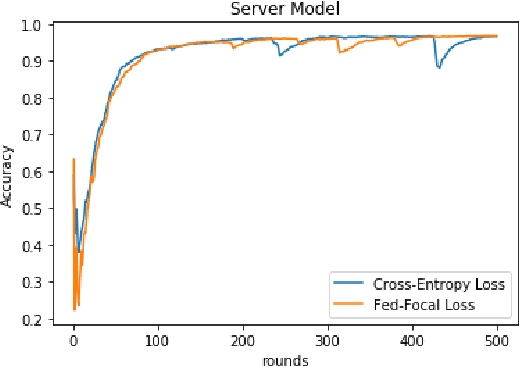
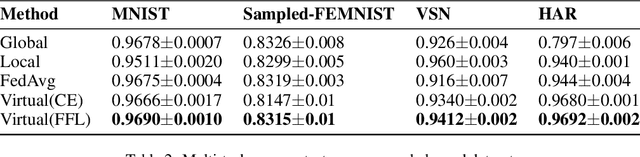

The Federated Learning setting has a central server coordinating the training of a model on a network of devices. One of the challenges is variable training performance when the dataset has a class imbalance. In this paper, we address this by introducing a new loss function called Fed-Focal Loss. We propose to address the class imbalance by reshaping cross-entropy loss such that it down-weights the loss assigned to well-classified examples along the lines of focal loss. Additionally, by leveraging a tunable sampling framework, we take into account selective client model contributions on the central server to further focus the detector during training and hence improve its robustness. Using a detailed experimental analysis with the VIRTUAL (Variational Federated Multi-Task Learning) approach, we demonstrate consistently superior performance in both the balanced and unbalanced scenarios for MNIST, FEMNIST, VSN and HAR benchmarks. We obtain a more than 9% (absolute percentage) improvement in the unbalanced MNIST benchmark. We further show that our technique can be adopted across multiple Federated Learning algorithms to get improvements.