 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatFedAvg: Optimising Communication-efficiency and Classification Accuracy in Federated Learning
Nov 14, 2020
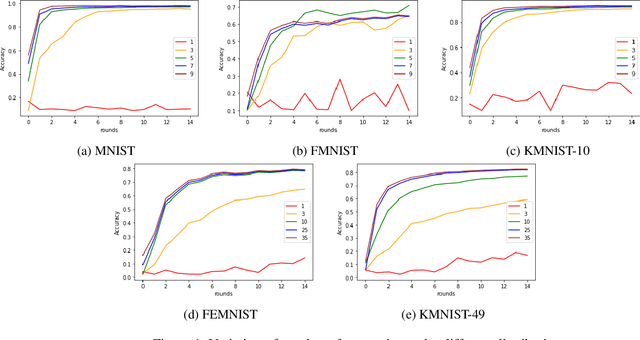

Federated learning has allowed the training of statistical models over remote devices without the transfer of raw client data. In practice, training in heterogeneous and large networks introduce novel challenges in various aspects like network load, quality of client data, security and privacy. Recent works in FL have worked on improving communication efficiency and addressing uneven client data distribution independently, but none have provided a unified solution for both challenges. We introduce a new family of Federated Learning algorithms called CatFedAvg which not only improves the communication efficiency but improves the quality of learning using a category coverage maximization strategy. We use the FedAvg framework and introduce a simple and efficient step every epoch to collect meta-data about the client's training data structure which the central server uses to request a subset of weight updates. We explore two distinct variations which allow us to further explore the tradeoffs between communication efficiency and model accuracy. Our experiments based on a vision classification task have shown that an increase of 10% absolute points in accuracy using the MNIST dataset with 70% absolute points lower network transfer over FedAvg. We also run similar experiments with Fashion MNIST, KMNIST-10, KMNIST-49 and EMNIST-47. Further, under extreme data imbalance experiments for both globally and individual clients, we see the model performing better than FedAvg. The ablation study further explores its behaviour under varying data and client parameter conditions showcasing the robustness of the proposed approach.
Fed-Focal Loss for imbalanced data classification in Federated Learning
Nov 12, 2020
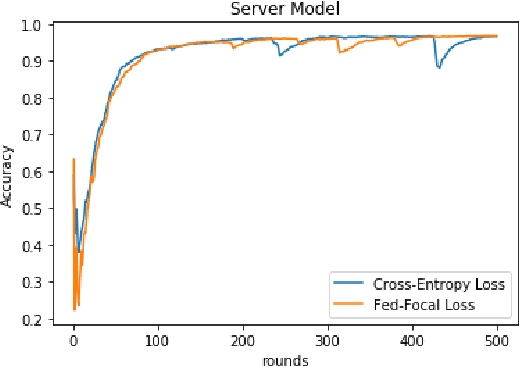
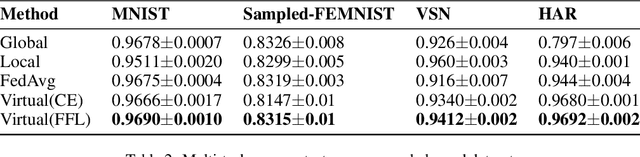

The Federated Learning setting has a central server coordinating the training of a model on a network of devices. One of the challenges is variable training performance when the dataset has a class imbalance. In this paper, we address this by introducing a new loss function called Fed-Focal Loss. We propose to address the class imbalance by reshaping cross-entropy loss such that it down-weights the loss assigned to well-classified examples along the lines of focal loss. Additionally, by leveraging a tunable sampling framework, we take into account selective client model contributions on the central server to further focus the detector during training and hence improve its robustness. Using a detailed experimental analysis with the VIRTUAL (Variational Federated Multi-Task Learning) approach, we demonstrate consistently superior performance in both the balanced and unbalanced scenarios for MNIST, FEMNIST, VSN and HAR benchmarks. We obtain a more than 9% (absolute percentage) improvement in the unbalanced MNIST benchmark. We further show that our technique can be adopted across multiple Federated Learning algorithms to get improvements.