 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Shot Audio to Animated Video Generation
Feb 19, 2021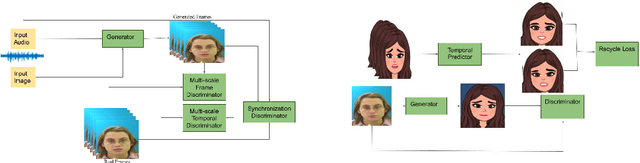


We consider the challenging problem of audio to animated video generation. We propose a novel method OneShotAu2AV to generate an animated video of arbitrary length using an audio clip and a single unseen image of a person as an input. The proposed method consists of two stages. In the first stage, OneShotAu2AV generates the talking-head video in the human domain given an audio and a person's image. In the second stage, the talking-head video from the human domain is converted to the animated domain. The model architecture of the first stage consists of spatially adaptive normalization based multi-level generator and multiple multilevel discriminators along with multiple adversarial and non-adversarial losses. The second stage leverages attention based normalization driven GAN architecture along with temporal predictor based recycle loss and blink loss coupled with lipsync loss, for unsupervised generation of animated video. In our approach, the input audio clip is not restricted to any specific language, which gives the method multilingual applicability. OneShotAu2AV can generate animated videos that have: (a) lip movements that are in sync with the audio, (b) natural facial expressions such as blinks and eyebrow movements, (c) head movements. Experimental evaluation demonstrates superior performance of OneShotAu2AV as compared to U-GAT-IT and RecycleGan on multiple quantitative metrics including KID(Kernel Inception Distance), Word error rate, blinks/sec
Robust One Shot Audio to Video Generation
Dec 14, 2020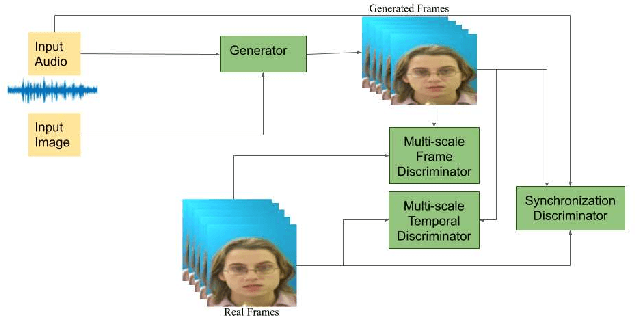
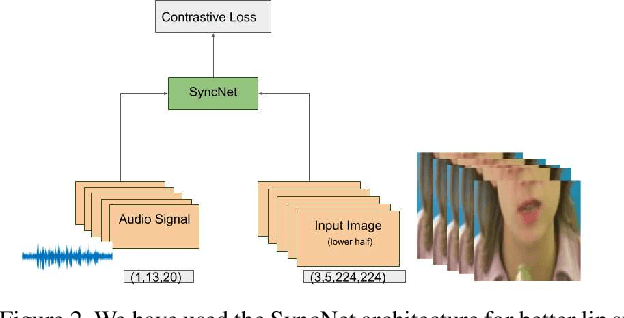

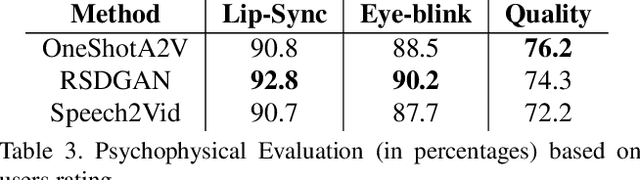
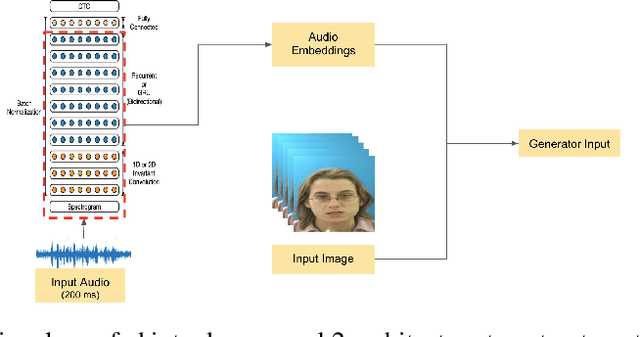
Audio to Video generation is an interesting problem that has numerous applications across industry verticals including film making, multi-media, marketing, education and others. High-quality video generation with expressive facial movements is a challenging problem that involves complex learning steps for generative adversarial networks. Further, enabling one-shot learning for an unseen single image increases the complexity of the problem while simultaneously making it more applicable to practical scenarios. In the paper, we propose a novel approach OneShotA2V to synthesize a talking person video of arbitrary length using as input: an audio signal and a single unseen image of a person. OneShotA2V leverages curriculum learning to learn movements of expressive facial components and hence generates a high-quality talking-head video of the given person. Further, it feeds the features generated from the audio input directly into a generative adversarial network and it adapts to any given unseen selfie by applying fewshot learning with only a few output updation epochs. OneShotA2V leverages spatially adaptive normalization based multi-level generator and multiple multi-level discriminators based architecture. The input audio clip is not restricted to any specific language, which gives the method multilingual applicability. Experimental evaluation demonstrates superior performance of OneShotA2V as compared to Realistic Speech-Driven Facial Animation with GANs(RSDGAN) [43], Speech2Vid [8], and other approaches, on multiple quantitative metrics including: SSIM (structural similarity index), PSNR (peak signal to noise ratio) and CPBD (image sharpness). Further, qualitative evaluation and Online Turing tests demonstrate the efficacy of our approach.