 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew Shot Adaptive Normalization Driven Multi-Speaker Speech Synthesis
Paper and Code
Dec 14, 2020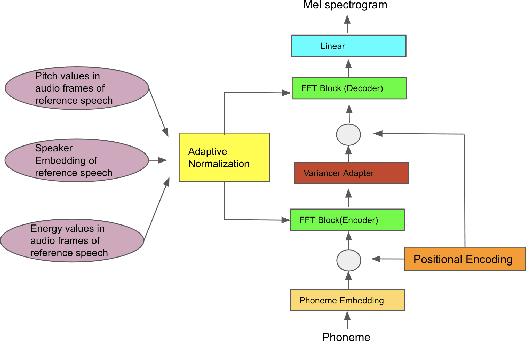

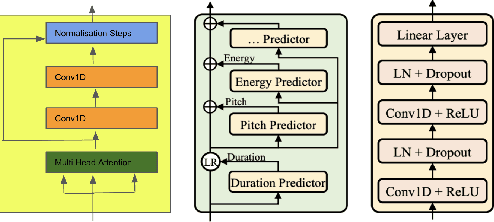
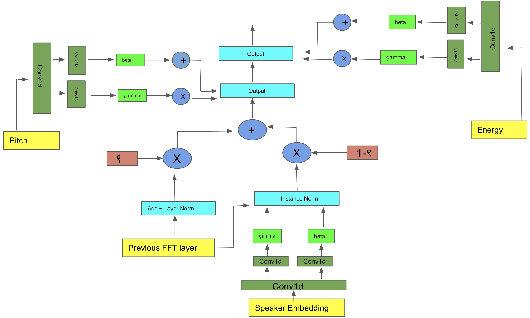
The style of the speech varies from person to person and every person exhibits his or her own style of speaking that is determined by the language, geography, culture and other factors. Style is best captured by prosody of a signal. High quality multi-speaker speech synthesis while considering prosody and in a few shot manner is an area of active research with many real-world applications. While multiple efforts have been made in this direction, it remains an interesting and challenging problem. In this paper, we present a novel few shot multi-speaker speech synthesis approach (FSM-SS) that leverages adaptive normalization architecture with a non-autoregressive multi-head attention model. Given an input text and a reference speech sample of an unseen person, FSM-SS can generate speech in that person's style in a few shot manner. Additionally, we demonstrate how the affine parameters of normalization help in capturing the prosodic features such as energy and fundamental frequency in a disentangled fashion and can be used to generate morphed speech output. We demonstrate the efficacy of our proposed architecture on multi-speaker VCTK and LibriTTS datasets, using multiple quantitative metrics that measure generated speech distortion and MoS, along with speaker embedding analysis of the generated speech vs the actual speech samples.