 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Modal Adaptive Normalization for Audio to Video Generation
Paper and Code
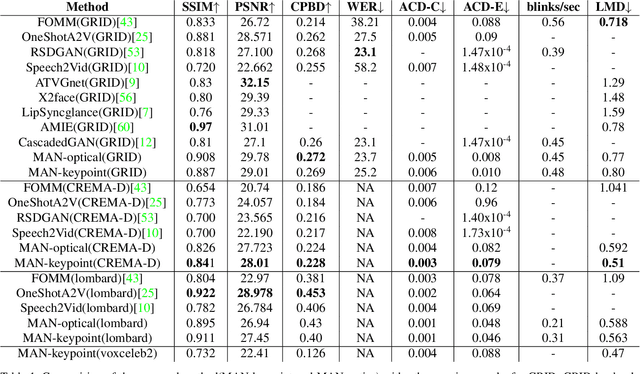

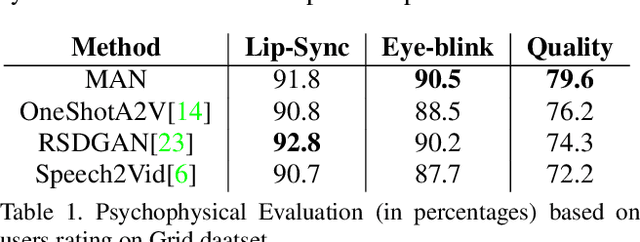
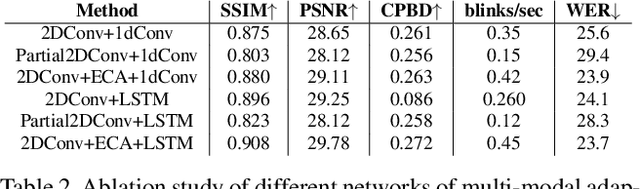
Speech-driven facial video generation has been a complex problem due to its multi-modal aspects namely audio and video domain. The audio comprises lots of underlying features such as expression, pitch, loudness, prosody(speaking style) and facial video has lots of variability in terms of head movement, eye blinks, lip synchronization and movements of various facial action units along with temporal smoothness. Synthesizing highly expressive facial videos from the audio input and static image is still a challenging task for generative adversarial networks. In this paper, we propose a multi-modal adaptive normalization(MAN) based architecture to synthesize a talking person video of arbitrary length using as input: an audio signal and a single image of a person. The architecture uses the multi-modal adaptive normalization, keypoint heatmap predictor, optical flow predictor and class activation map[58] based layers to learn movements of expressive facial components and hence generates a highly expressive talking-head video of the given person. The multi-modal adaptive normalization uses the various features of audio and video such as Mel spectrogram, pitch, energy from audio signals and predicted keypoint heatmap/optical flow and a single image to learn the respective affine parameters to generate highly expressive video. Experimental evaluation demonstrates superior performance of the proposed method as compared to Realistic Speech-Driven Facial Animation with GANs(RSDGAN) [53], Speech2Vid [10], and other approaches, on multiple quantitative metrics including: SSIM (structural similarity index), PSNR (peak signal to noise ratio), CPBD (image sharpness), WER(word error rate), blinks/sec and LMD(landmark distance). Further, qualitative evaluation and Online Turing tests demonstrate the efficacy of our approach.