 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKL Regularized Normalization Framework for Low Resource Tasks
Paper and Code
Dec 21, 2022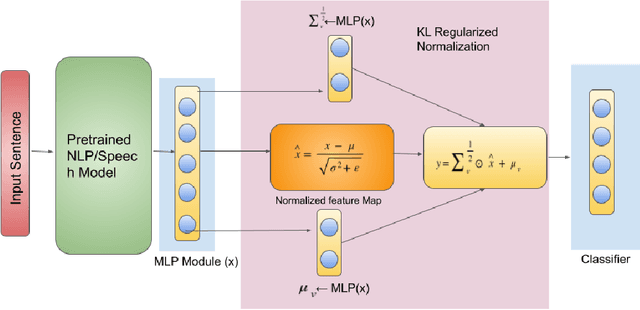
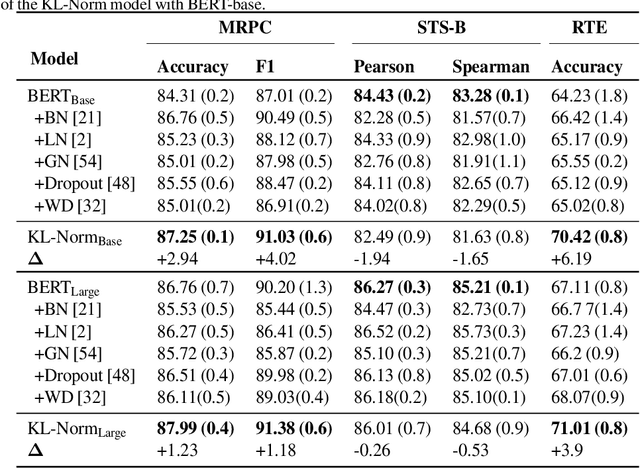
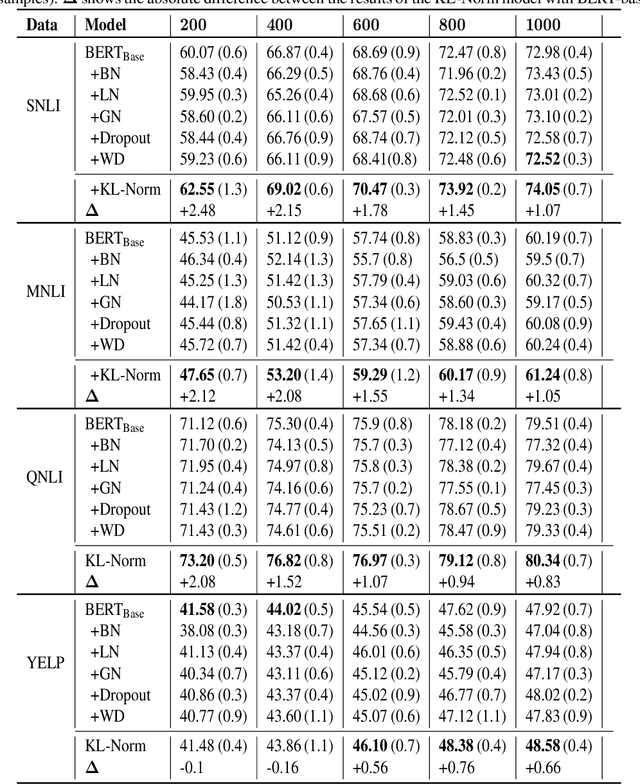
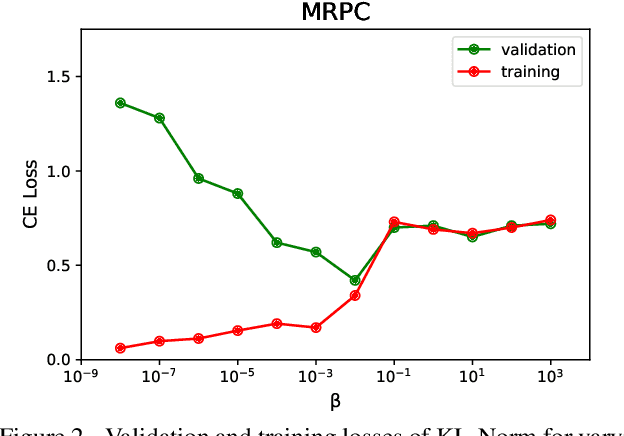
Large pre-trained models, such as Bert, GPT, and Wav2Vec, have demonstrated great potential for learning representations that are transferable to a wide variety of downstream tasks . It is difficult to obtain a large quantity of supervised data due to the limited availability of resources and time. In light of this, a significant amount of research has been conducted in the area of adopting large pre-trained datasets for diverse downstream tasks via fine tuning, linear probing, or prompt tuning in low resource settings. Normalization techniques are essential for accelerating training and improving the generalization of deep neural networks and have been successfully used in a wide variety of applications. A lot of normalization techniques have been proposed but the success of normalization in low resource downstream NLP and speech tasks is limited. One of the reasons is the inability to capture expressiveness by rescaling parameters of normalization. We propose KullbackLeibler(KL) Regularized normalization (KL-Norm) which make the normalized data well behaved and helps in better generalization as it reduces over-fitting, generalises well on out of domain distributions and removes irrelevant biases and features with negligible increase in model parameters and memory overheads. Detailed experimental evaluation on multiple low resource NLP and speech tasks, demonstrates the superior performance of KL-Norm as compared to other popular normalization and regularization techniques.