 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing LLMs in Software Requirements Specifications: An Empirical Evaluation
Apr 27, 2024The creation of a Software Requirements Specification (SRS) document is important for any software development project. Given the recent prowess of Large Language Models (LLMs) in answering natural language queries and generating sophisticated textual outputs, our study explores their capability to produce accurate, coherent, and structured drafts of these documents to accelerate the software development lifecycle. We assess the performance of GPT-4 and CodeLlama in drafting an SRS for a university club management system and compare it against human benchmarks using eight distinct criteria. Our results suggest that LLMs can match the output quality of an entry-level software engineer to generate an SRS, delivering complete and consistent drafts. We also evaluate the capabilities of LLMs to identify and rectify problems in a given requirements document. Our experiments indicate that GPT-4 is capable of identifying issues and giving constructive feedback for rectifying them, while CodeLlama's results for validation were not as encouraging. We repeated the generation exercise for four distinct use cases to study the time saved by employing LLMs for SRS generation. The experiment demonstrates that LLMs may facilitate a significant reduction in development time for entry-level software engineers. Hence, we conclude that the LLMs can be gainfully used by software engineers to increase productivity by saving time and effort in generating, validating and rectifying software requirements.
Towards long-tailed, multi-label disease classification from chest X-ray: Overview of the CXR-LT challenge
Oct 24, 2023



Many real-world image recognition problems, such as diagnostic medical imaging exams, are "long-tailed" $\unicode{x2013}$ there are a few common findings followed by many more relatively rare conditions. In chest radiography, diagnosis is both a long-tailed and multi-label problem, as patients often present with multiple findings simultaneously. While researchers have begun to study the problem of long-tailed learning in medical image recognition, few have studied the interaction of label imbalance and label co-occurrence posed by long-tailed, multi-label disease classification. To engage with the research community on this emerging topic, we conducted an open challenge, CXR-LT, on long-tailed, multi-label thorax disease classification from chest X-rays (CXRs). We publicly release a large-scale benchmark dataset of over 350,000 CXRs, each labeled with at least one of 26 clinical findings following a long-tailed distribution. We synthesize common themes of top-performing solutions, providing practical recommendations for long-tailed, multi-label medical image classification. Finally, we use these insights to propose a path forward involving vision-language foundation models for few- and zero-shot disease classification.
How Can We Tame the Long-Tail of Chest X-ray Datasets?
Sep 08, 2023Chest X-rays (CXRs) are a medical imaging modality that is used to infer a large number of abnormalities. While it is hard to define an exhaustive list of these abnormalities, which may co-occur on a chest X-ray, few of them are quite commonly observed and are abundantly represented in CXR datasets used to train deep learning models for automated inference. However, it is challenging for current models to learn independent discriminatory features for labels that are rare but may be of high significance. Prior works focus on the combination of multi-label and long tail problems by introducing novel loss functions or some mechanism of re-sampling or re-weighting the data. Instead, we propose that it is possible to achieve significant performance gains merely by choosing an initialization for a model that is closer to the domain of the target dataset. This method can complement the techniques proposed in existing literature, and can easily be scaled to new labels. Finally, we also examine the veracity of synthetically generated data to augment the tail labels and analyse its contribution to improving model performance.
Generalized Cross-domain Multi-label Few-shot Learning for Chest X-rays
Sep 08, 2023



Real-world application of chest X-ray abnormality classification requires dealing with several challenges: (i) limited training data; (ii) training and evaluation sets that are derived from different domains; and (iii) classes that appear during training may have partial overlap with classes of interest during evaluation. To address these challenges, we present an integrated framework called Generalized Cross-Domain Multi-Label Few-Shot Learning (GenCDML-FSL). The framework supports overlap in classes during training and evaluation, cross-domain transfer, adopts meta-learning to learn using few training samples, and assumes each chest X-ray image is either normal or associated with one or more abnormalities. Furthermore, we propose Generalized Episodic Training (GenET), a training strategy that equips models to operate with multiple challenges observed in the GenCDML-FSL scenario. Comparisons with well-established methods such as transfer learning, hybrid transfer learning, and multi-label meta-learning on multiple datasets show the superiority of our approach.
Can we Adopt Self-supervised Pretraining for Chest X-Rays?
Nov 23, 2022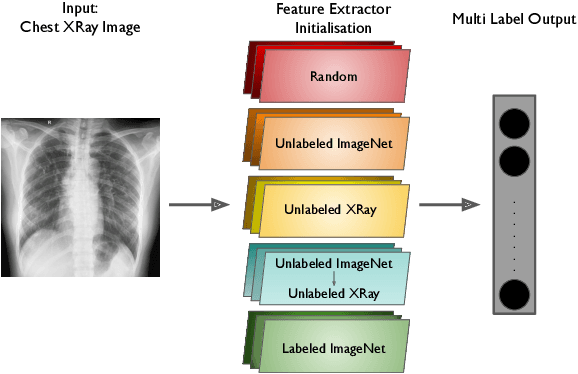



Chest radiograph (or Chest X-Ray, CXR) is a popular medical imaging modality that is used by radiologists across the world to diagnose heart or lung conditions. Over the last decade, Convolutional Neural Networks (CNN), have seen success in identifying pathologies in CXR images. Typically, these CNNs are pretrained on the standard ImageNet classification task, but this assumes availability of large-scale annotated datasets. In this work, we analyze the utility of pretraining on unlabeled ImageNet or Chest X-Ray (CXR) datasets using various algorithms and in multiple settings. Some findings of our work include: (i) supervised training with labeled ImageNet learns strong representations that are hard to beat; (ii) self-supervised pretraining on ImageNet (~1M images) shows performance similar to self-supervised pretraining on a CXR dataset (~100K images); and (iii) the CNN trained on supervised ImageNet can be trained further with self-supervised CXR images leading to improvements, especially when the downstream dataset is on the order of a few thousand images.