 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneGPT: A Language Model for 3D Scene Understanding
Paper and Code
Aug 13, 2024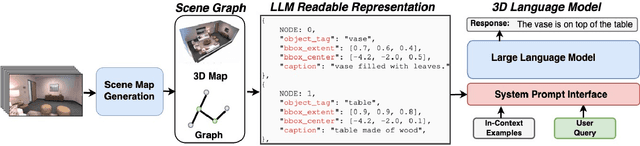
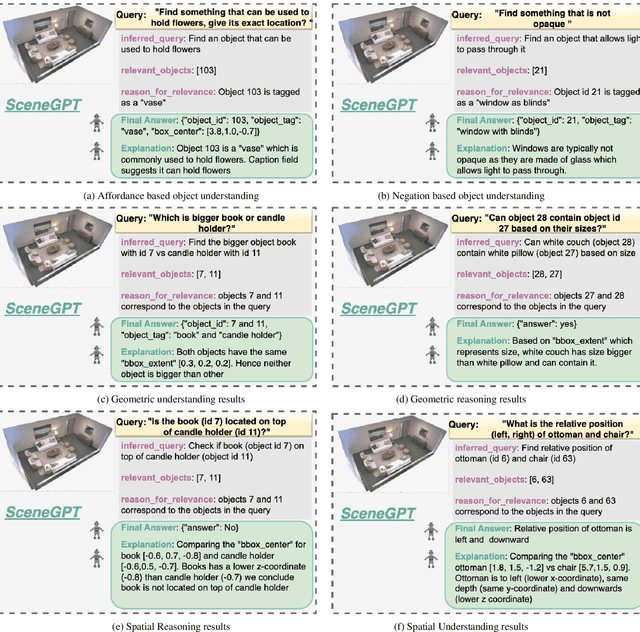
Building models that can understand and reason about 3D scenes is difficult owing to the lack of data sources for 3D supervised training and large-scale training regimes. In this work we ask - How can the knowledge in a pre-trained language model be leveraged for 3D scene understanding without any 3D pre-training. The aim of this work is to establish whether pre-trained LLMs possess priors/knowledge required for reasoning in 3D space and how can we prompt them such that they can be used for general purpose spatial reasoning and object understanding in 3D. To this end, we present SceneGPT, an LLM based scene understanding system which can perform 3D spatial reasoning without training or explicit 3D supervision. The key components of our framework are - 1) a 3D scene graph, that serves as scene representation, encoding the objects in the scene and their spatial relationships 2) a pre-trained LLM that can be adapted with in context learning for 3D spatial reasoning. We evaluate our framework qualitatively on object and scene understanding tasks including object semantics, physical properties and affordances (object-level) and spatial understanding (scene-level).