 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Complexity Deep Learning Augmented Wireless Channel Estimation for Pilot-Based OFDM on Zynq System on Chip
Mar 02, 2024Channel estimation (CE) is one of the critical signal-processing tasks of the wireless physical layer (PHY). Recent deep learning (DL) based CE have outperformed statistical approaches such as least-square-based CE (LS) and linear minimum mean square error-based CE (LMMSE). However, existing CE approaches have not yet been realized on system-on-chip (SoC). The first contribution of this paper is to efficiently implement the existing state-of-the-art CE algorithms on Zynq SoC (ZSoC), comprising of ARM processor and field programmable gate array (FPGA), via hardware-software co-design and fixed point analysis. We validate the superiority of DL-based CE and LMMSE over LS for various signal-to-noise ratios (SNR) and wireless channels in terms of mean square error (MSE) and bit error rate (BER). We also highlight the high complexity, execution time, and power consumption of DL-based CE and LMMSE approaches. To address this, we propose a novel compute-efficient LS-augmented interpolated deep neural network (LSiDNN) based CE algorithm and realize it on ZSoC. The proposed LSiDNN offers 88-90% lower execution time and 38-85% lower resource utilization than state-of-the-art DL-based CE for identical MSE and BER. LSiDNN offers significantly lower MSE and BER than LMMSE, and the gain improves with increased mobility between transceivers. It offers 75% lower execution time and 90-94% lower resource utilization than LMMSE.
Hardware Software Co-design of Statistical and Deep Learning Frameworks for Wideband Sensing on Zynq System on Chip
Sep 06, 2022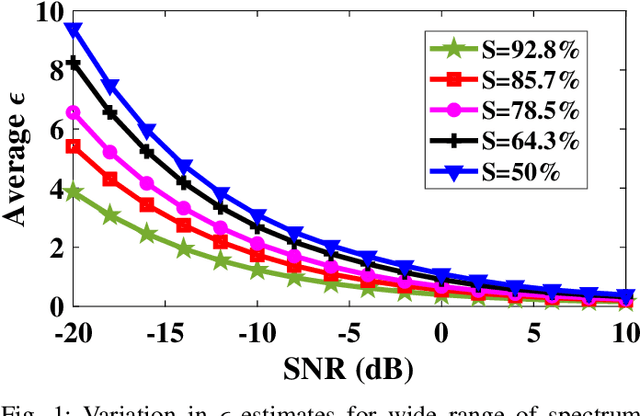
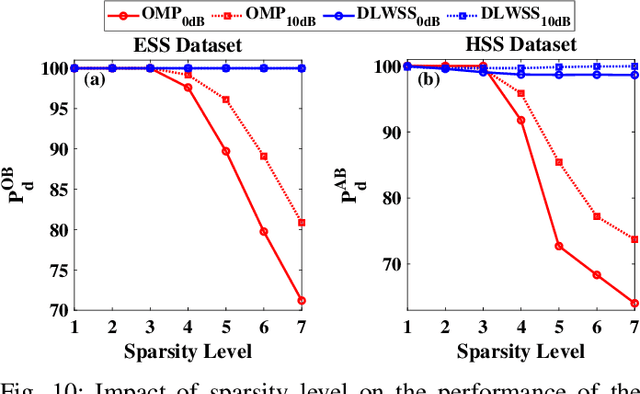
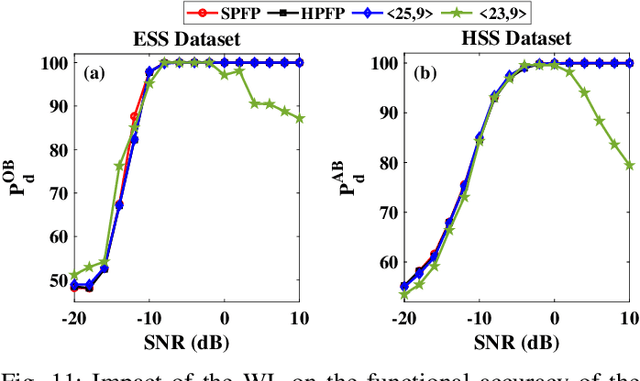
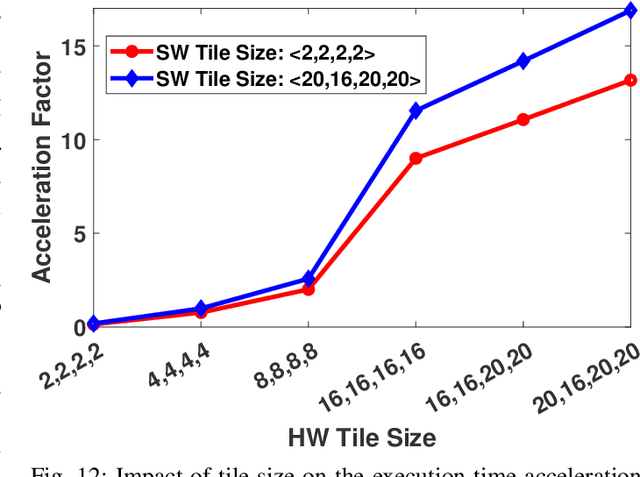
With the introduction of spectrum sharing and heterogeneous services in next-generation networks, the base stations need to sense the wideband spectrum and identify the spectrum resources to meet the quality-of-service, bandwidth, and latency constraints. Sub-Nyquist sampling (SNS) enables digitization for sparse wideband spectrum without needing Nyquist speed analog-to-digital converters. However, SNS demands additional signal processing algorithms for spectrum reconstruction, such as the well-known orthogonal matching pursuit (OMP) algorithm. OMP is also widely used in other compressed sensing applications. The first contribution of this work is efficiently mapping the OMP algorithm on the Zynq system-on-chip (ZSoC) consisting of an ARM processor and FPGA. Experimental analysis shows a significant degradation in OMP performance for sparse spectrum. Also, OMP needs prior knowledge of spectrum sparsity. We address these challenges via deep-learning-based architectures and efficiently map them on the ZSoC platform as second contribution. Via hardware-software co-design, different versions of the proposed architecture obtained by partitioning between software (ARM processor) and hardware (FPGA) are considered. The resource, power, and execution time comparisons for given memory constraints and a wide range of word lengths are presented for these architectures.