 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcoAssistant: Using LLM Assistant More Affordably and Accurately
Oct 03, 2023Today, users ask Large language models (LLMs) as assistants to answer queries that require external knowledge; they ask about the weather in a specific city, about stock prices, and even about where specific locations are within their neighborhood. These queries require the LLM to produce code that invokes external APIs to answer the user's question, yet LLMs rarely produce correct code on the first try, requiring iterative code refinement upon execution results. In addition, using LLM assistants to support high query volumes can be expensive. In this work, we contribute a framework, EcoAssistant, that enables LLMs to answer code-driven queries more affordably and accurately. EcoAssistant contains three components. First, it allows the LLM assistants to converse with an automatic code executor to iteratively refine code or to produce answers based on the execution results. Second, we use a hierarchy of LLM assistants, which attempts to answer the query with weaker, cheaper LLMs before backing off to stronger, expensive ones. Third, we retrieve solutions from past successful queries as in-context demonstrations to help subsequent queries. Empirically, we show that EcoAssistant offers distinct advantages for affordability and accuracy, surpassing GPT-4 by 10 points of success rate with less than 50% of GPT-4's cost.
Cost-Effective Hyperparameter Optimization for Large Language Model Generation Inference
Mar 08, 2023Large Language Models (LLMs) like GPT-3 have sparked significant interest in their generative capabilities, leading to the development of various commercial applications. The high cost of using the models drives application builders to maximize the value of generation under a limited inference budget. This paper presents a study of optimizing inference hyperparameters like the number of responses, temperature and max tokens, which significantly affects the utility/cost of text generation. We design a framework named EcoOptiGen which leverages economical hyperparameter optimization and cost-based pruning. Experiments with the latest GPT-3.5 models on a variety of tasks verify its effectiveness. EcoOptiGen is implemented in the FLAML library: https://github.com/microsoft/FLAML, and we provide one example of using it at: https://microsoft.github.io/FLAML/docs/Examples/Integrate%20-%20OpenAI.
On Improving Summarization Factual Consistency from Natural Language Feedback
Dec 20, 2022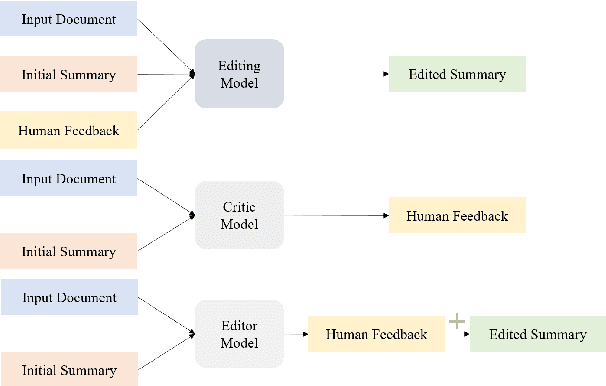
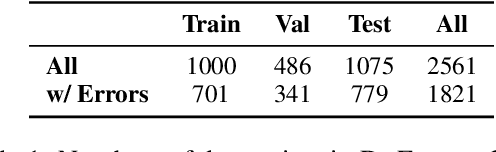

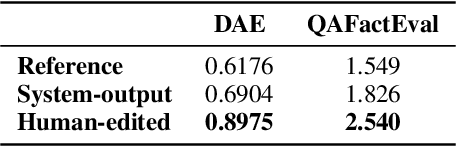
Despite the recent progress in language generation models, their outputs may not always meet user expectations. In this work, we study whether informational feedback in natural language can be leveraged to improve generation quality and user preference alignment. To this end, we consider factual consistency in summarization, the quality that the summary should only contain information supported by the input documents, for user preference alignment. We collect a high-quality dataset, DeFacto, containing human demonstrations and informational feedback in natural language consisting of corrective instructions, edited summaries, and explanations with respect to the factual consistency of the summary. Using our dataset, we study two natural language generation tasks: 1) editing a summary using the human feedback, and 2) generating human feedback from the original summary. Using the two tasks, we further evaluate if models can automatically correct factual inconsistencies in generated summaries. We show that the human-edited summaries we collected are more factually consistent, and pre-trained language models can leverage our dataset to improve the factual consistency of original system-generated summaries in our proposed generation tasks. We make the DeFacto dataset publicly available at https://github.com/microsoft/DeFacto.
Leveraging Locality in Abstractive Text Summarization
May 25, 2022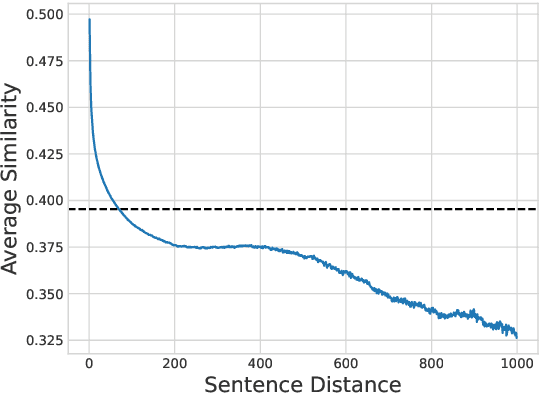
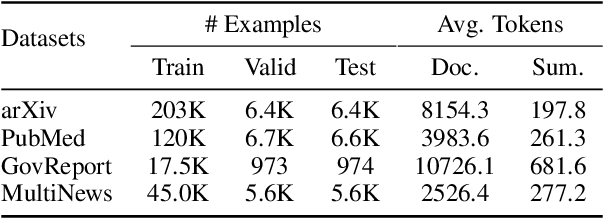
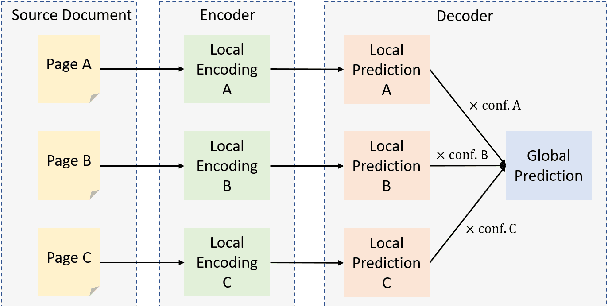
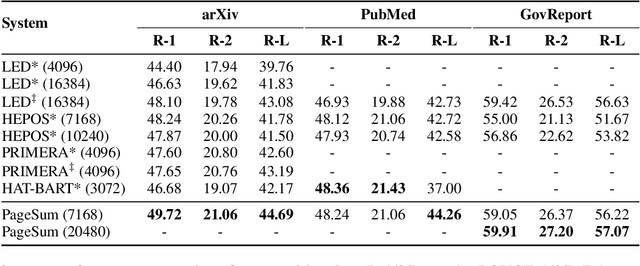
Despite the successes of neural attention models for natural language generation tasks, the quadratic memory complexity of the self-attention module with respect to the input length hinders their applications in long text summarization. Instead of designing more efficient attention modules, we approach this problem by investigating if models with a restricted context can have competitive performance compared with the memory-efficient attention models that maintain a global context by treating the input as an entire sequence. Our model is applied to individual pages, which contain parts of inputs grouped by the principle of locality, during both encoding and decoding stages. We empirically investigated three kinds of localities in text summarization at different levels, ranging from sentences to documents. Our experimental results show that our model can have better performance compared with strong baseline models with efficient attention modules, and our analysis provides further insights of our locality-aware modeling strategy.
Sparsely Activated Mixture-of-Experts are Robust Multi-Task Learners
Apr 16, 2022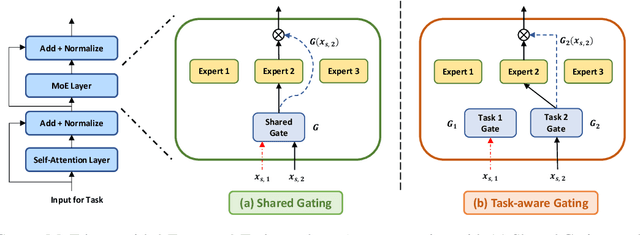
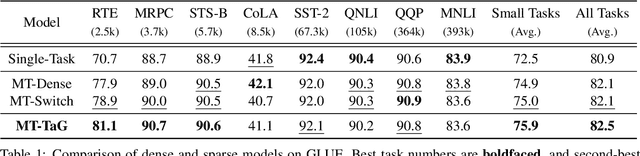
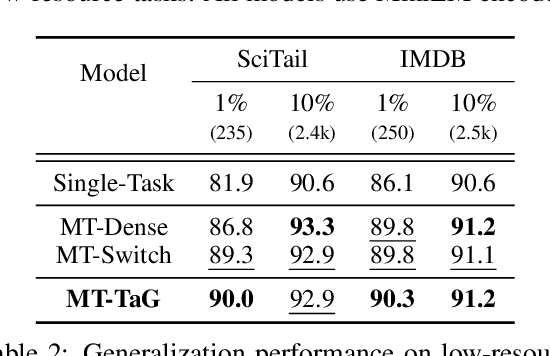
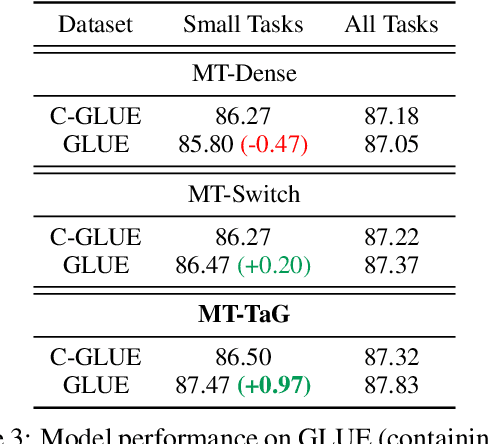
Traditional multi-task learning (MTL) methods use dense networks that use the same set of shared weights across several different tasks. This often creates interference where two or more tasks compete to pull model parameters in different directions. In this work, we study whether sparsely activated Mixture-of-Experts (MoE) improve multi-task learning by specializing some weights for learning shared representations and using the others for learning task-specific information. To this end, we devise task-aware gating functions to route examples from different tasks to specialized experts which share subsets of network weights conditioned on the task. This results in a sparsely activated multi-task model with a large number of parameters, but with the same computational cost as that of a dense model. We demonstrate such sparse networks to improve multi-task learning along three key dimensions: (i) transfer to low-resource tasks from related tasks in the training mixture; (ii) sample-efficient generalization to tasks not seen during training by making use of task-aware routing from seen related tasks; (iii) robustness to the addition of unrelated tasks by avoiding catastrophic forgetting of existing tasks.
Summ^N: A Multi-Stage Summarization Framework for Long Input Dialogues and Documents
Oct 16, 2021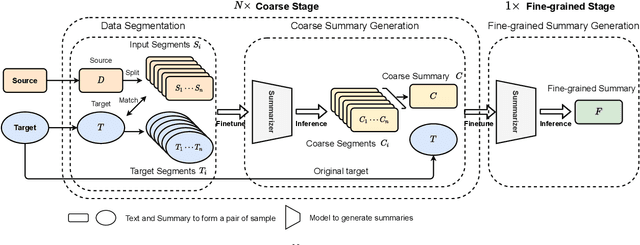
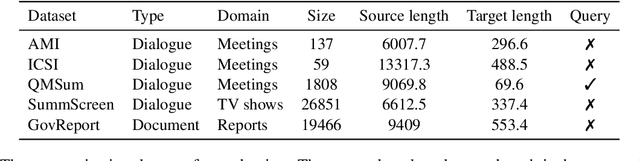
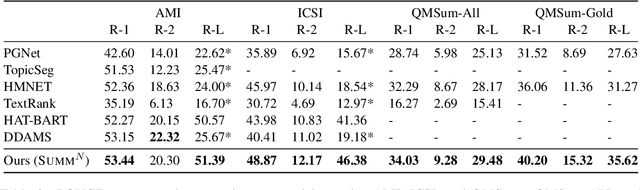
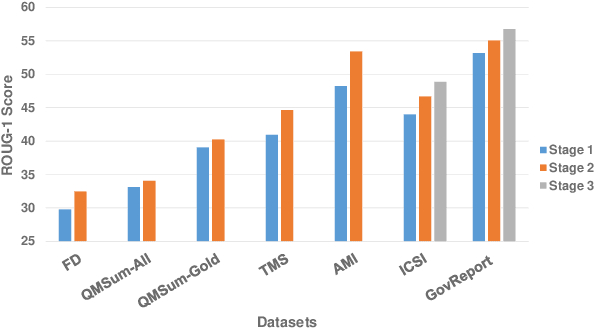
Text summarization is an essential task to help readers capture salient information from documents, news, interviews, and meetings. However, most state-of-the-art pretrained language models are unable to efficiently process long text commonly seen in the summarization problem domain. In this paper, we propose Summ^N, a simple, flexible, and effective multi-stage framework for input texts that are longer than the maximum context lengths of typical pretrained LMs. Summ^N first generates the coarse summary in multiple stages and then produces the final fine-grained summary based on them. The framework can process input text of arbitrary length by adjusting the number of stages while keeping the LM context size fixed. Moreover, it can deal with both documents and dialogues and can be used on top of any underlying backbone abstractive summarization model. Our experiments demonstrate that Summ^N significantly outperforms previous state-of-the-art methods by improving ROUGE scores on three long meeting summarization datasets AMI, ICSI, and QMSum, two long TV series datasets from SummScreen, and a newly proposed long document summarization dataset GovReport. Our data and code are available at https://github.com/chatc/Summ-N.
DYLE: Dynamic Latent Extraction for Abstractive Long-Input Summarization
Oct 15, 2021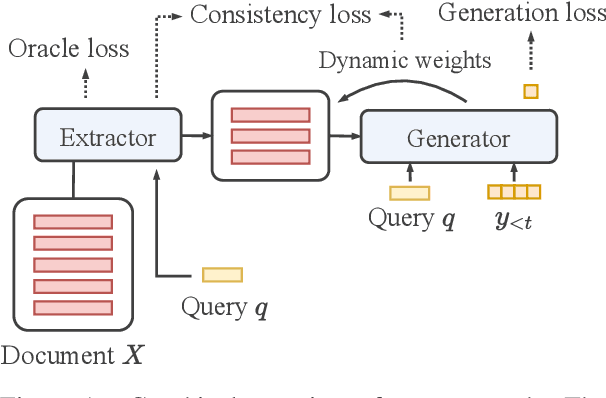
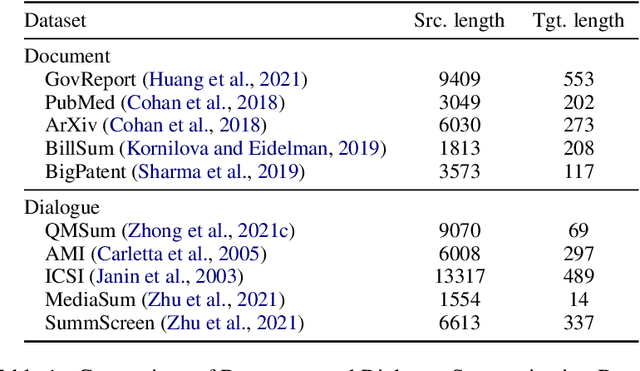
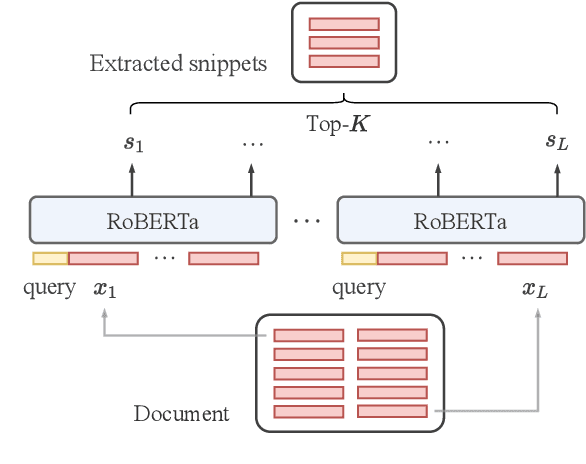
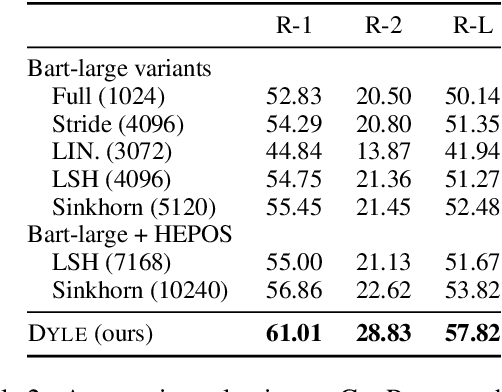
Transformer-based models have achieved state-of-the-art performance on short text summarization. However, they still struggle with long-input summarization. In this paper, we present a new approach for long-input summarization: Dynamic Latent Extraction for Abstractive Summarization. We jointly train an extractor with an abstractor and treat the extracted text snippets as the latent variable. We propose extractive oracles to provide the extractor with a strong learning signal. We introduce consistency loss, which encourages the extractor to approximate the averaged dynamic weights predicted by the generator. We conduct extensive tests on two long-input summarization datasets, GovReport (document) and QMSum (dialogue). Our model significantly outperforms the current state-of-the-art, including a 6.21 ROUGE-2 improvement on GovReport and a 2.13 ROUGE-1 improvement on QMSum. Further analysis shows that the dynamic weights make our generation process highly interpretable. Our code will be publicly available upon publication.