 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRILL: Grounded Vision-language Pre-training via Aligning Text and Image Regions
May 24, 2023



Generalization to unseen tasks is an important ability for few-shot learners to achieve better zero-/few-shot performance on diverse tasks. However, such generalization to vision-language tasks including grounding and generation tasks has been under-explored; existing few-shot VL models struggle to handle tasks that involve object grounding and multiple images such as visual commonsense reasoning or NLVR2. In this paper, we introduce GRILL, GRounded vIsion Language aLigning, a novel VL model that can be generalized to diverse tasks including visual question answering, captioning, and grounding tasks with no or very few training instances. Specifically, GRILL learns object grounding and localization by exploiting object-text alignments, which enables it to transfer to grounding tasks in a zero-/few-shot fashion. We evaluate our model on various zero-/few-shot VL tasks and show that it consistently surpasses the state-of-the-art few-shot methods.
Sparsely Activated Mixture-of-Experts are Robust Multi-Task Learners
Apr 16, 2022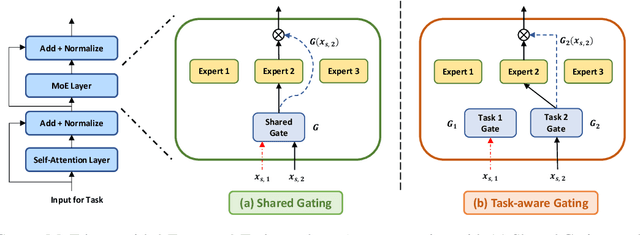
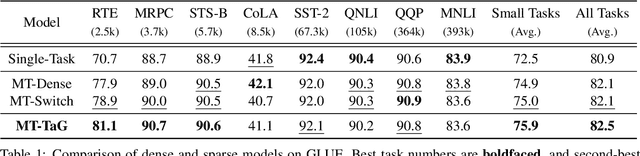
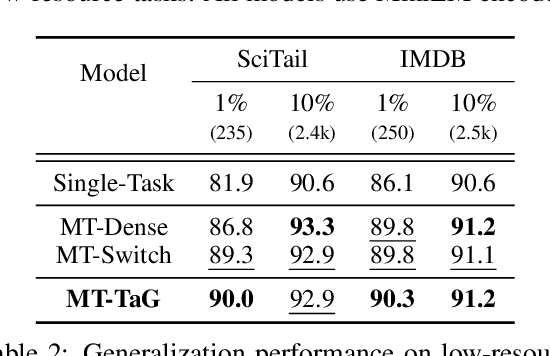
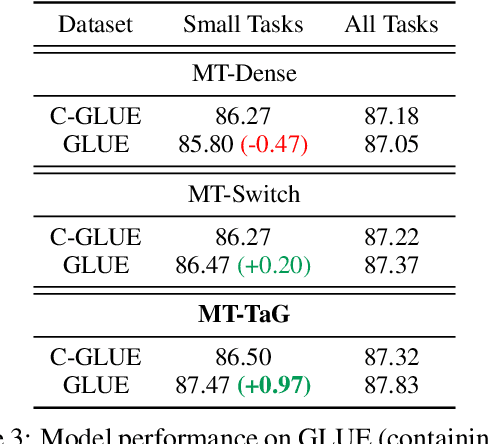
Traditional multi-task learning (MTL) methods use dense networks that use the same set of shared weights across several different tasks. This often creates interference where two or more tasks compete to pull model parameters in different directions. In this work, we study whether sparsely activated Mixture-of-Experts (MoE) improve multi-task learning by specializing some weights for learning shared representations and using the others for learning task-specific information. To this end, we devise task-aware gating functions to route examples from different tasks to specialized experts which share subsets of network weights conditioned on the task. This results in a sparsely activated multi-task model with a large number of parameters, but with the same computational cost as that of a dense model. We demonstrate such sparse networks to improve multi-task learning along three key dimensions: (i) transfer to low-resource tasks from related tasks in the training mixture; (ii) sample-efficient generalization to tasks not seen during training by making use of task-aware routing from seen related tasks; (iii) robustness to the addition of unrelated tasks by avoiding catastrophic forgetting of existing tasks.
Zero-Shot Dense Retrieval with Momentum Adversarial Domain Invariant Representations
Oct 14, 2021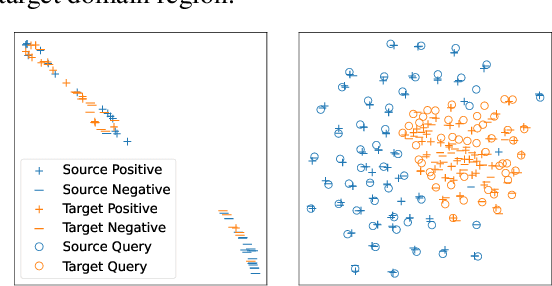
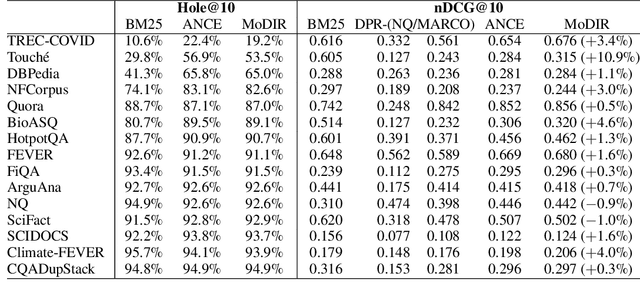
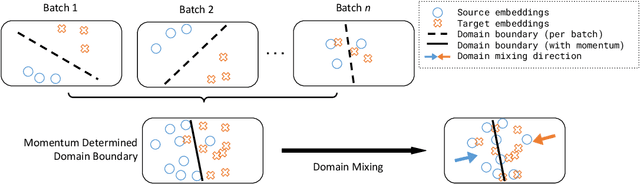

Dense retrieval (DR) methods conduct text retrieval by first encoding texts in the embedding space and then matching them by nearest neighbor search. This requires strong locality properties from the representation space, i.e, the close allocations of each small group of relevant texts, which are hard to generalize to domains without sufficient training data. In this paper, we aim to improve the generalization ability of DR models from source training domains with rich supervision signals to target domains without any relevant labels, in the zero-shot setting. To achieve that, we propose Momentum adversarial Domain Invariant Representation learning (MoDIR), which introduces a momentum method in the DR training process to train a domain classifier distinguishing source versus target, and then adversarially updates the DR encoder to learn domain invariant representations. Our experiments show that MoDIR robustly outperforms its baselines on 10+ ranking datasets from the BEIR benchmark in the zero-shot setup, with more than 10% relative gains on datasets with enough sensitivity for DR models' evaluation. Source code of this paper will be released.
Few-Shot Named Entity Recognition: A Comprehensive Study
Dec 29, 2020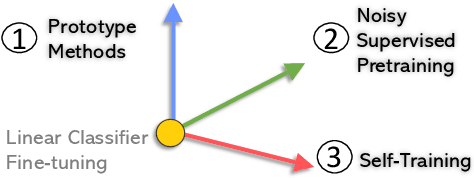

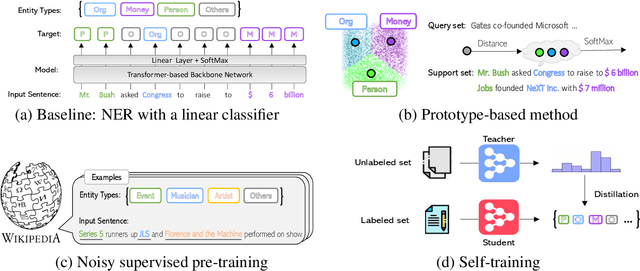
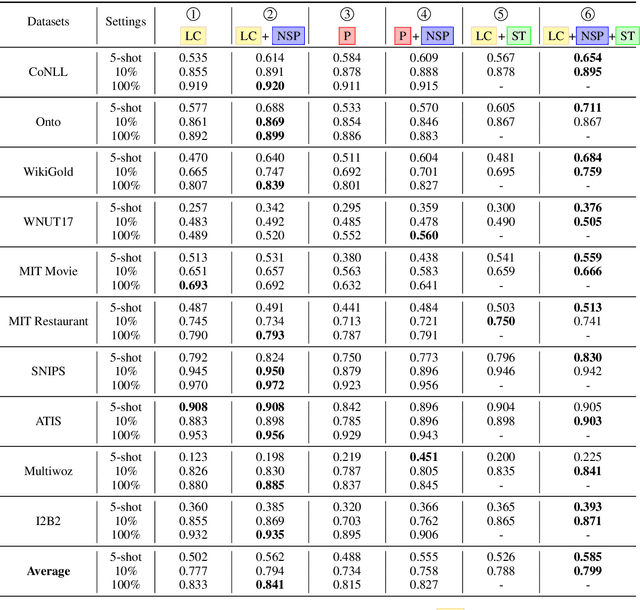
This paper presents a comprehensive study to efficiently build named entity recognition (NER) systems when a small number of in-domain labeled data is available. Based upon recent Transformer-based self-supervised pre-trained language models (PLMs), we investigate three orthogonal schemes to improve the model generalization ability for few-shot settings: (1) meta-learning to construct prototypes for different entity types, (2) supervised pre-training on noisy web data to extract entity-related generic representations and (3) self-training to leverage unlabeled in-domain data. Different combinations of these schemes are also considered. We perform extensive empirical comparisons on 10 public NER datasets with various proportions of labeled data, suggesting useful insights for future research. Our experiments show that (i) in the few-shot learning setting, the proposed NER schemes significantly improve or outperform the commonly used baseline, a PLM-based linear classifier fine-tuned on domain labels; (ii) We create new state-of-the-art results on both few-shot and training-free settings compared with existing methods. We will release our code and pre-trained models for reproducible research.
Off-policy evaluation for slate recommendation
Nov 06, 2017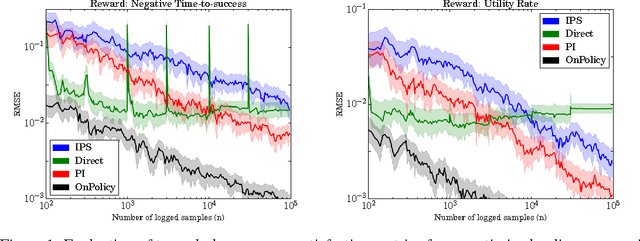
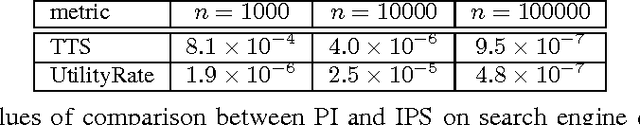
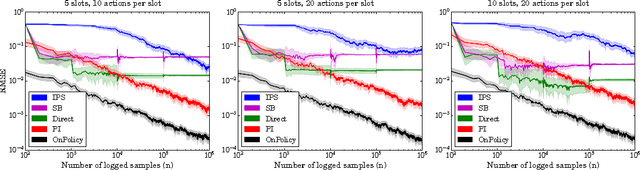
This paper studies the evaluation of policies that recommend an ordered set of items (e.g., a ranking) based on some context---a common scenario in web search, ads, and recommendation. We build on techniques from combinatorial bandits to introduce a new practical estimator that uses logged data to estimate a policy's performance. A thorough empirical evaluation on real-world data reveals that our estimator is accurate in a variety of settings, including as a subroutine in a learning-to-rank task, where it achieves competitive performance. We derive conditions under which our estimator is unbiased---these conditions are weaker than prior heuristics for slate evaluation---and experimentally demonstrate a smaller bias than parametric approaches, even when these conditions are violated. Finally, our theory and experiments also show exponential savings in the amount of required data compared with general unbiased estimators.