 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference Attacks Expose Participation Privacy in ECG Foundation Encoders
Apr 12, 2026Foundation-style ECG encoders pretrained with self-supervised learning are increasingly reused across tasks, institutions, and deployment contexts, often through model-as-a-service interfaces that expose scalar scores or latent representations. While such reuse improves data efficiency and generalization, it raises a participation privacy concern: can an adversary infer whether a specific individual or cohort contributed ECG data to pretraining, even when raw waveforms and diagnostic labels are never disclosed? In connected-health settings, training participation itself may reveal institutional affiliation, study enrollment, or sensitive health context. We present an implementation-grounded audit of membership inference attacks (MIAs) against modern self-supervised ECG foundation encoders, covering contrastive objectives (SimCLR, TS2Vec) and masked reconstruction objectives (CNN- and Transformer-based MAE). We evaluate three realistic attacker interfaces: (i) score-only black-box access to scalar outputs, (ii) adaptive learned attackers that aggregate subject-level statistics across repeated queries, and (iii) embedding-access attackers that probe latent representation geometry. Using a subject-centric protocol with window-to-subject aggregation and calibration at fixed false-positive rates under a cross-dataset auditing setting, we observe heterogeneous and objective-dependent participation leakage: leakage is most pronounced in small or institution-specific cohorts and, for contrastive encoders, can saturate in embedding space, while larger and more diverse datasets substantially attenuate operational tail risk. Overall, our results show that restricting access to raw signals or labels is insufficient to guarantee participation privacy, underscoring the need for deployment-aware auditing of reusable biosignal foundation encoders in connected-health systems.
CARE-ECG: Causal Agent-based Reasoning for Explainable and Counterfactual ECG Interpretation
Apr 12, 2026Large language models (LLMs) enable waveform-to-text ECG interpretation and interactive clinical questioning, yet most ECG-LLM systems still rely on weak signal-text alignment and retrieval without explicit physiological or causal structure. This limits grounding, temporal reasoning, and counterfactual "what-if" analysis central to clinical decision-making. We propose CARE-ECG, a causally structured ECG-language reasoning framework that unifies representation learning, diagnosis, and explanation in a single pipeline. CARE-ECG encodes multi-lead ECGs into temporally organized latent biomarkers, performs causal graph inference for probabilistic diagnosis, and supports counterfactual assessment via structural causal models. To improve faithfulness, CARE-ECG grounds language outputs through causal retrieval-augmented generation and a modular agentic pipeline that integrates history, diagnosis, and response with verification. Across multiple ECG benchmarks and expert QA settings, CARE-ECG improves diagnostic accuracy and explanation faithfulness while reducing hallucinations (e.g., 0.84 accuracy on Expert-ECG-QA and 0.76 on SCP-mapped PTB-XL under GPT-4). Overall, CARE-ECG provides traceable reasoning by exposing key latent drivers, causal evidence paths, and how alternative physiological states would change outcomes.
Modeling Wise Decision Making: A Z-Number Fuzzy Framework Inspired by Phronesis
Aug 29, 2025


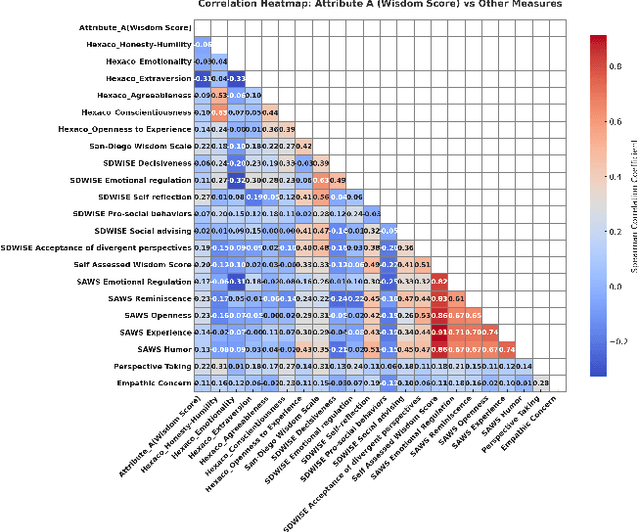
Background: Wisdom is a superordinate construct that embraces perspective taking, reflectiveness, prosocial orientation, reflective empathetic action, and intellectual humility. Unlike conventional models of reasoning that are rigidly bound by binary thinking, wisdom unfolds in shades of ambiguity, requiring both graded evaluation and self-reflective humility. Current measures depend on self-reports and seldom reflect the humility and uncertainty inherent in wise reasoning. A computational framework that takes into account both multidimensionality and confidence has the potential to improve psychological science and allow humane AI. Method: We present a fuzzy inference system with Z numbers, each of the decisions being expressed in terms of a wisdom score (restriction) and confidence score (certainty). As part of this study, participants (N = 100) were exposed to culturally neutral pictorial moral dilemma tasks to which they generated think-aloud linguistic responses, which were mapped into five theoretically based components of wisdom. The scores of each individual component were combined using a base of 21 rules, with membership functions tuned via Gaussian kernel density estimation. Results: In a proof of concept study, the system produced dual attribute wisdom representations that correlated modestly but significantly with established scales while showing negligible relations with unrelated traits, supporting convergent and divergent validity. Contribution: The contribution is to formalize wisdom as a multidimensional, uncertainty-conscious construct, operationalized in the form of Z-numbers. In addition to progressing measurement in psychology, it calculates how fuzzy Z numbers can provide AI systems with interpretable, confidence-sensitive reasoning that affords a safe, middle ground between rigorous computation and human-like judgment.
Hierarchical corpus encoder: Fusing generative retrieval and dense indices
Feb 26, 2025



Generative retrieval employs sequence models for conditional generation of document IDs based on a query (DSI (Tay et al., 2022); NCI (Wang et al., 2022); inter alia). While this has led to improved performance in zero-shot retrieval, it is a challenge to support documents not seen during training. We identify the performance of generative retrieval lies in contrastive training between sibling nodes in a document hierarchy. This motivates our proposal, the hierarchical corpus encoder (HCE), which can be supported by traditional dense encoders. Our experiments show that HCE achieves superior results than generative retrieval models under both unsupervised zero-shot and supervised settings, while also allowing the easy addition and removal of documents to the index.
Zero-Shot Dense Retrieval with Momentum Adversarial Domain Invariant Representations
Oct 14, 2021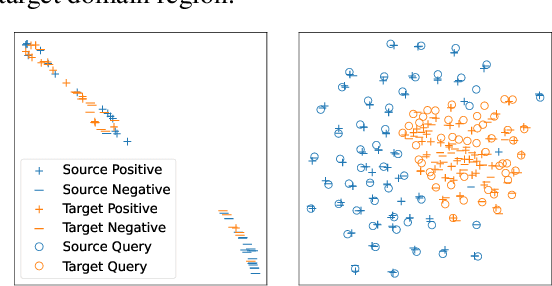
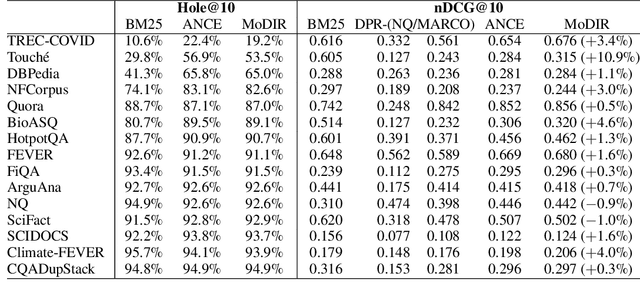
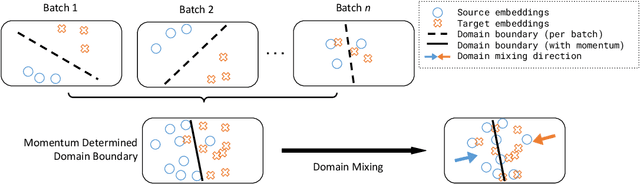

Dense retrieval (DR) methods conduct text retrieval by first encoding texts in the embedding space and then matching them by nearest neighbor search. This requires strong locality properties from the representation space, i.e, the close allocations of each small group of relevant texts, which are hard to generalize to domains without sufficient training data. In this paper, we aim to improve the generalization ability of DR models from source training domains with rich supervision signals to target domains without any relevant labels, in the zero-shot setting. To achieve that, we propose Momentum adversarial Domain Invariant Representation learning (MoDIR), which introduces a momentum method in the DR training process to train a domain classifier distinguishing source versus target, and then adversarially updates the DR encoder to learn domain invariant representations. Our experiments show that MoDIR robustly outperforms its baselines on 10+ ranking datasets from the BEIR benchmark in the zero-shot setup, with more than 10% relative gains on datasets with enough sensitivity for DR models' evaluation. Source code of this paper will be released.
Evaluating Deep Learning in SystemML using Layer-wise Adaptive Rate Scaling(LARS) Optimizer
Feb 05, 2021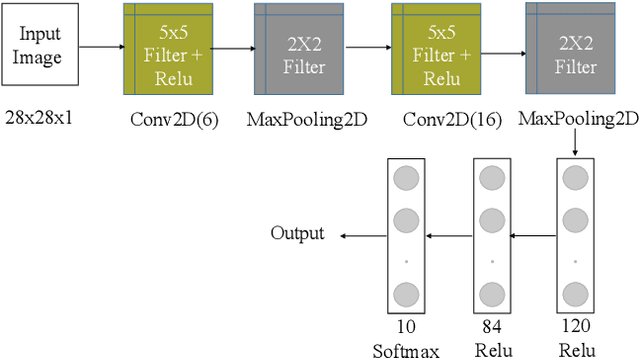

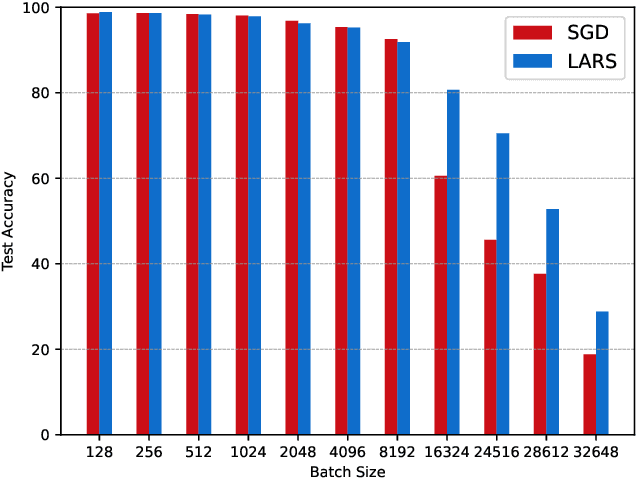
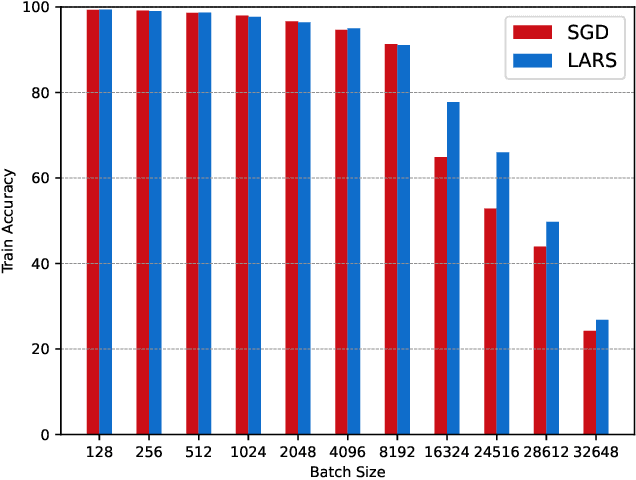
Increasing the batch size of a deep learning model is a challenging task. Although it might help in utilizing full available system memory during training phase of a model, it results in significant loss of test accuracy most often. LARS solved this issue by introducing an adaptive learning rate for each layer of a deep learning model. However, there are doubts on how popular distributed machine learning systems such as SystemML or MLlib will perform with this optimizer. In this work, we apply LARS optimizer to a deep learning model implemented using SystemML.We perform experiments with various batch sizes and compare the performance of LARS optimizer with \textit{Stochastic Gradient Descent}. Our experimental results show that LARS optimizer performs significantly better than Stochastic Gradient Descent for large batch sizes even with the distributed machine learning framework, SystemML.