 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Deep Learning in SystemML using Layer-wise Adaptive Rate Scaling(LARS) Optimizer
Feb 05, 2021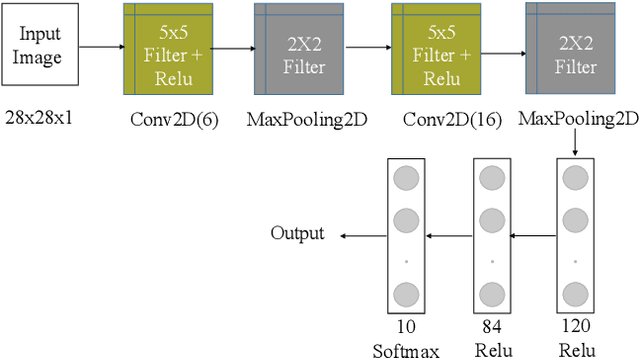

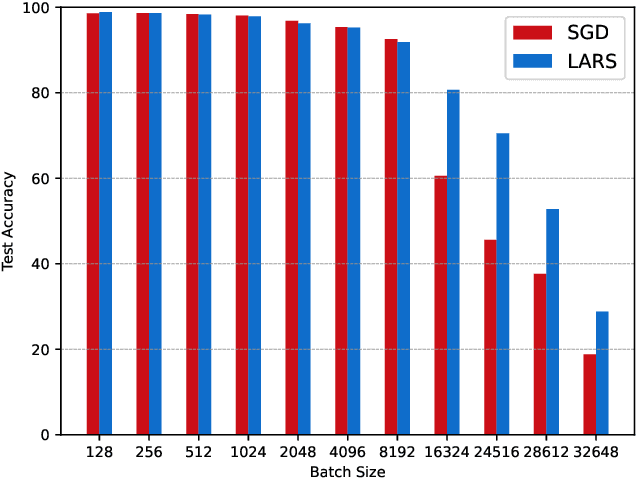
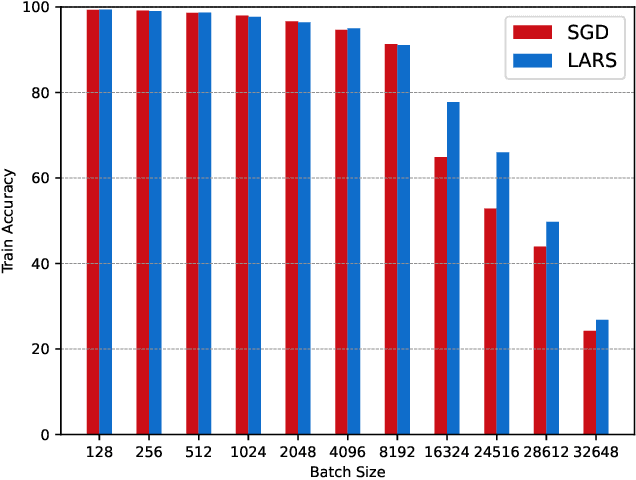
Increasing the batch size of a deep learning model is a challenging task. Although it might help in utilizing full available system memory during training phase of a model, it results in significant loss of test accuracy most often. LARS solved this issue by introducing an adaptive learning rate for each layer of a deep learning model. However, there are doubts on how popular distributed machine learning systems such as SystemML or MLlib will perform with this optimizer. In this work, we apply LARS optimizer to a deep learning model implemented using SystemML.We perform experiments with various batch sizes and compare the performance of LARS optimizer with \textit{Stochastic Gradient Descent}. Our experimental results show that LARS optimizer performs significantly better than Stochastic Gradient Descent for large batch sizes even with the distributed machine learning framework, SystemML.