 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Transfer Learning for Question Answering
Paper and Code
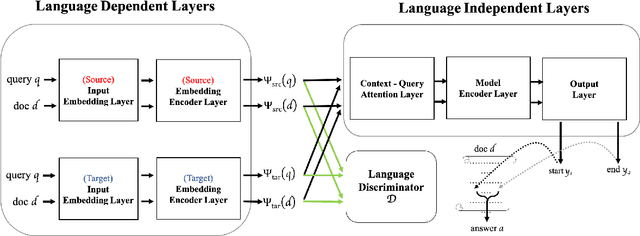

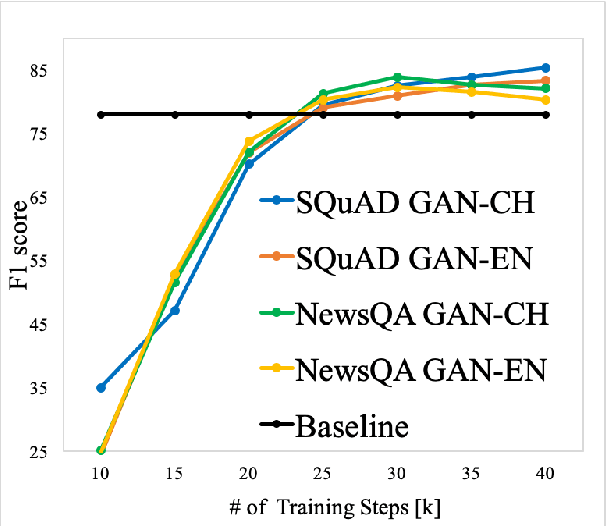

Deep learning based question answering (QA) on English documents has achieved success because there is a large amount of English training examples. However, for most languages, training examples for high-quality QA models are not available. In this paper, we explore the problem of cross-lingual transfer learning for QA, where a source language task with plentiful annotations is utilized to improve the performance of a QA model on a target language task with limited available annotations. We examine two different approaches. A machine translation (MT) based approach translates the source language into the target language, or vice versa. Although the MT-based approach brings improvement, it assumes the availability of a sentence-level translation system. A GAN-based approach incorporates a language discriminator to learn language-universal feature representations, and consequentially transfer knowledge from the source language. The GAN-based approach rivals the performance of the MT-based approach with fewer linguistic resources. Applying both approaches simultaneously yield the best results. We use two English benchmark datasets, SQuAD and NewsQA, as source language data, and show significant improvements over a number of established baselines on a Chinese QA task. We achieve the new state-of-the-art on the Chinese QA dataset.