 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning for Few-Shot Dialogue State Tracking
Paper and Code

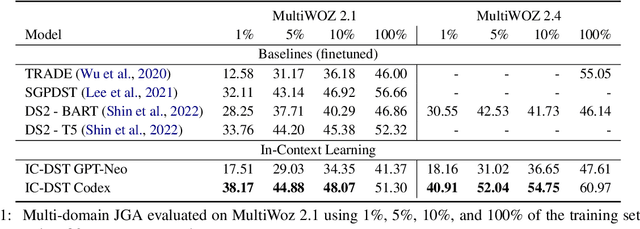


Collecting and annotating task-oriented dialogues is time-consuming and costly. Thus, few-shot learning for dialogue tasks presents an exciting opportunity. In this work, we propose an in-context (IC) learning framework for few-shot dialogue state tracking (DST), where a large pre-trained language model (LM) takes a test instance and a few annotated examples as input, and directly decodes the dialogue states without any parameter updates. This makes the LM more flexible and scalable compared to prior few-shot DST work when adapting to new domains and scenarios. We study ways to formulate dialogue context into prompts for LMs and propose an efficient approach to retrieve dialogues as exemplars given a test instance and a selection pool of few-shot examples. To better leverage the pre-trained LMs, we also reformulate DST into a text-to-SQL problem. Empirical results on MultiWOZ 2.1 and 2.4 show that our method IC-DST outperforms previous fine-tuned state-of-the-art models in few-shot settings.