 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Model Training to Model Raising
Nov 17, 2025
Current AI training methods align models with human values only after their core capabilities have been established, resulting in models that are easily misaligned and lack deep-rooted value systems. We propose a paradigm shift from "model training" to "model raising", in which alignment is woven into a model's development from the start. We identify several key components for this paradigm, all centered around redesigning the training corpus: reframing training data from a first-person perspective, recontextualizing information as lived experience, simulating social interactions, and scaffolding the ordering of training data. We expect that this redesign of the training corpus will lead to an early commitment to values from the first training token onward, such that knowledge, skills, and values are intrinsically much harder to separate. In an ecosystem in which large language model capabilities start overtaking human capabilities in many tasks, this seems to us like a critical need.
Code and Pixels: Multi-Modal Contrastive Pre-training for Enhanced Tabular Data Analysis
Jan 13, 2025



Learning from tabular data is of paramount importance, as it complements the conventional analysis of image and video data by providing a rich source of structured information that is often critical for comprehensive understanding and decision-making processes. We present Multi-task Contrastive Masked Tabular Modeling (MT-CMTM), a novel method aiming to enhance tabular models by leveraging the correlation between tabular data and corresponding images. MT-CMTM employs a dual strategy combining contrastive learning with masked tabular modeling, optimizing the synergy between these data modalities. Central to our approach is a 1D Convolutional Neural Network with residual connections and an attention mechanism (1D-ResNet-CBAM), designed to efficiently process tabular data without relying on images. This enables MT-CMTM to handle purely tabular data for downstream tasks, eliminating the need for potentially costly image acquisition and processing. We evaluated MT-CMTM on the DVM car dataset, which is uniquely suited for this particular scenario, and the newly developed HIPMP dataset, which connects membrane fabrication parameters with image data. Our MT-CMTM model outperforms the proposed tabular 1D-ResNet-CBAM, which is trained from scratch, achieving a relative 1.48% improvement in relative MSE on HIPMP and a 2.38% increase in absolute accuracy on DVM. These results demonstrate MT-CMTM's robustness and its potential to advance the field of multi-modal learning.
There and Back Again: The AI Alignment Paradox
May 31, 2024The field of AI alignment aims to steer AI systems toward human goals, preferences, and ethical principles. Its contributions have been instrumental for improving the output quality, safety, and trustworthiness of today's AI models. This perspective article draws attention to a fundamental challenge inherent in all AI alignment endeavors, which we term the "AI alignment paradox": The better we align AI models with our values, the easier we make it for adversaries to misalign the models. We illustrate the paradox by sketching three concrete example incarnations for the case of language models, each corresponding to a distinct way in which adversaries can exploit the paradox. With AI's increasing real-world impact, it is imperative that a broad community of researchers be aware of the AI alignment paradox and work to find ways to break out of it, in order to ensure the beneficial use of AI for the good of humanity.
Fleet of Agents: Coordinated Problem Solving with Large Language Models using Genetic Particle Filtering
May 07, 2024



Large language models (LLMs) have significantly evolved, moving from simple output generation to complex reasoning and from stand-alone usage to being embedded into broader frameworks. In this paper, we introduce \emph{Fleet of Agents (FoA)}, a novel framework utilizing LLMs as agents to navigate through dynamic tree searches, employing a genetic-type particle filtering approach. FoA spawns a multitude of agents, each exploring autonomously, followed by a selection phase where resampling based on a heuristic value function optimizes the balance between exploration and exploitation. This mechanism enables dynamic branching, adapting the exploration strategy based on discovered solutions. We experimentally validate FoA using two benchmark tasks, "Game of 24" and "Mini-Crosswords". FoA outperforms the previously proposed Tree-of-Thoughts method in terms of efficacy and efficiency: it significantly decreases computational costs (by calling the value function less frequently) while preserving comparable or even superior accuracy.
Emojinize: Enriching Any Text with Emoji Translations
Mar 07, 2024



Emoji have become ubiquitous in written communication, on the Web and beyond. They can emphasize or clarify emotions, add details to conversations, or simply serve decorative purposes. This casual use, however, barely scratches the surface of the expressive power of emoji. To further unleash this power, we present Emojinize, a method for translating arbitrary text phrases into sequences of one or more emoji without requiring human input. By leveraging the power of large language models, Emojinize can choose appropriate emoji by disambiguating based on context (eg, cricket-bat vs bat) and can express complex concepts compositionally by combining multiple emoji (eq, "Emojinize" is translated to input-latin-letters right-arrow grinning-face). In a cloze test--based user study, we show that Emojinize's emoji translations increase the human guessability of masked words by 55%, whereas human-picked emoji translations do so by only 29%. These results suggest that emoji provide a sufficiently rich vocabulary to accurately translate a wide variety of words. Moreover, annotating words and phrases with Emojinize's emoji translations opens the door to numerous downstream applications, including children learning how to read, adults learning foreign languages, and text understanding for people with learning disabilities.
Broccoli: Sprinkling Lightweight Vocabulary Learning into Everyday Information Diets
Apr 16, 2021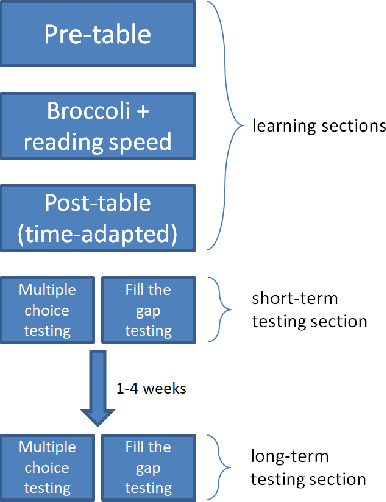
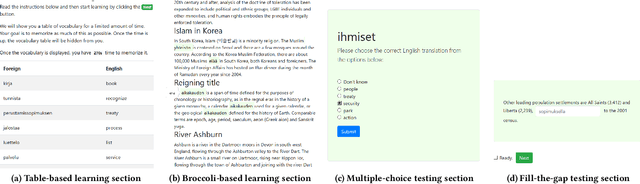
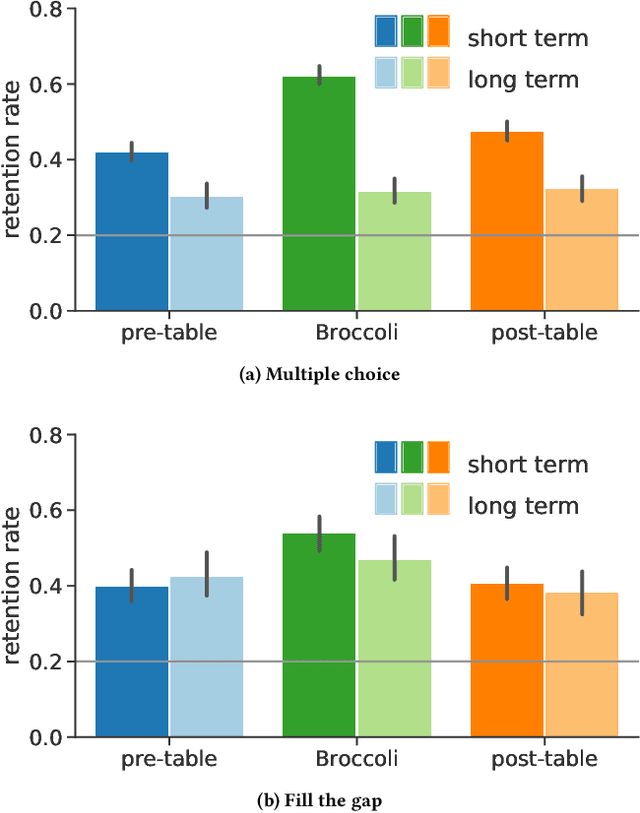
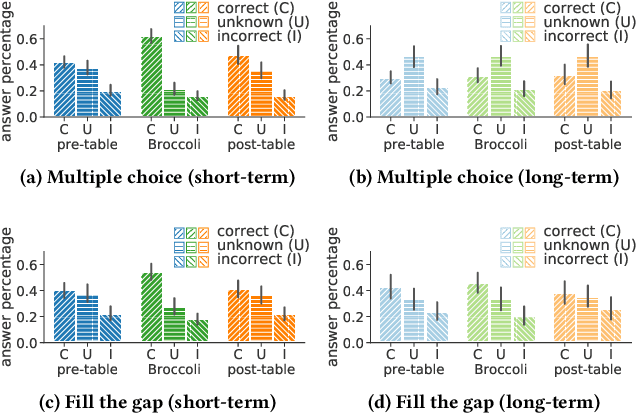
The learning of a new language remains to this date a cognitive task that requires considerable diligence and willpower, recent advances and tools notwithstanding. In this paper, we propose Broccoli, a new paradigm aimed at reducing the required effort by seamlessly embedding vocabulary learning into users' everyday information diets. This is achieved by inconspicuously switching chosen words encountered by the user for their translation in the target language. Thus, by seeing words in context, the user can assimilate new vocabulary without much conscious effort. We validate our approach in a careful user study, finding that the efficacy of the lightweight Broccoli approach is competitive with traditional, memorization-based vocabulary learning. The low cognitive overhead is manifested in a pronounced decrease in learners' usage of mnemonic learning strategies, as compared to traditional learning. Finally, we establish that language patterns in typical information diets are compatible with spaced-repetition strategies, thus enabling an efficient use of the Broccoli paradigm. Overall, our work establishes the feasibility of a novel and powerful "install-and-forget" approach for embedded language acquisition.