 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Improvements for Exploiting Dependency Trees in Neural Semantic Parsing
Paper and Code
Dec 25, 2021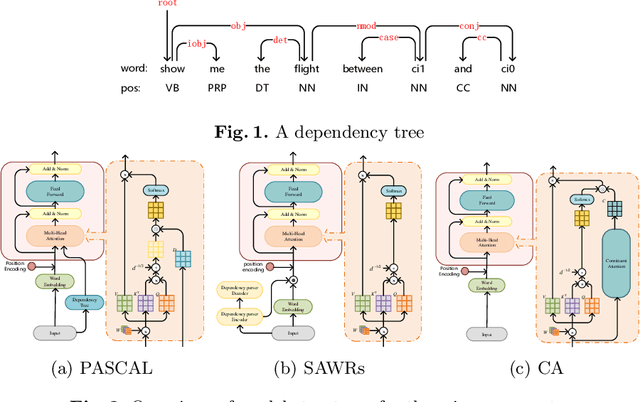
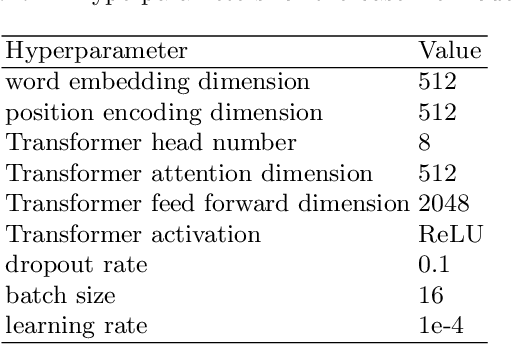
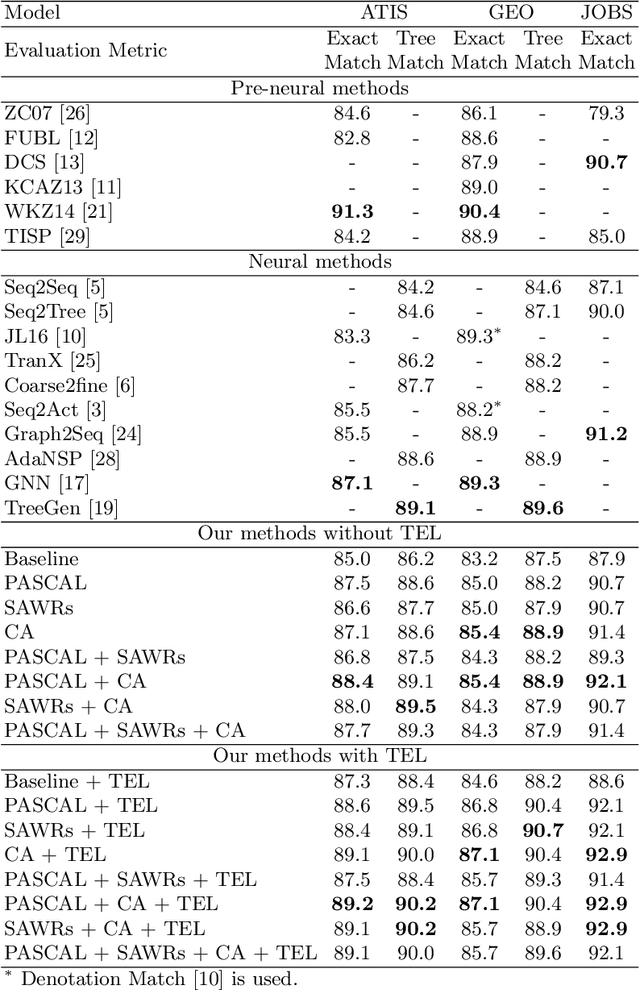
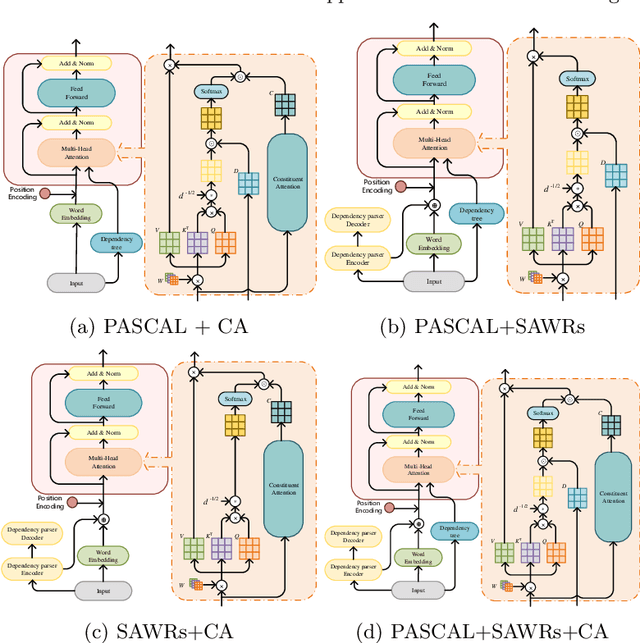
The dependency tree of a natural language sentence can capture the interactions between semantics and words. However, it is unclear whether those methods which exploit such dependency information for semantic parsing can be combined to achieve further improvement and the relationship of those methods when they combine. In this paper, we examine three methods to incorporate such dependency information in a Transformer based semantic parser and empirically study their combinations. We first replace standard self-attention heads in the encoder with parent-scaled self-attention (PASCAL) heads, i.e., the ones that can attend to the dependency parent of each token. Then we concatenate syntax-aware word representations (SAWRs), i.e., the intermediate hidden representations of a neural dependency parser, with ordinary word embedding to enhance the encoder. Later, we insert the constituent attention (CA) module to the encoder, which adds an extra constraint to attention heads that can better capture the inherent dependency structure of input sentences. Transductive ensemble learning (TEL) is used for model aggregation, and an ablation study is conducted to show the contribution of each method. Our experiments show that CA is complementary to PASCAL or SAWRs, and PASCAL + CA provides state-of-the-art performance among neural approaches on ATIS, GEO, and JOBS.