 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Interpretations for Explainable Natural Language Processing: A Survey
Paper and Code
Mar 20, 2021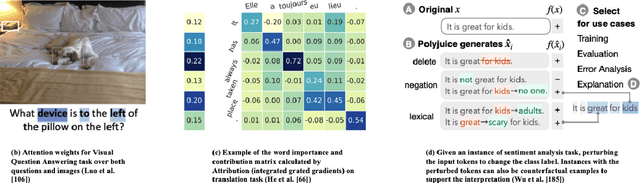
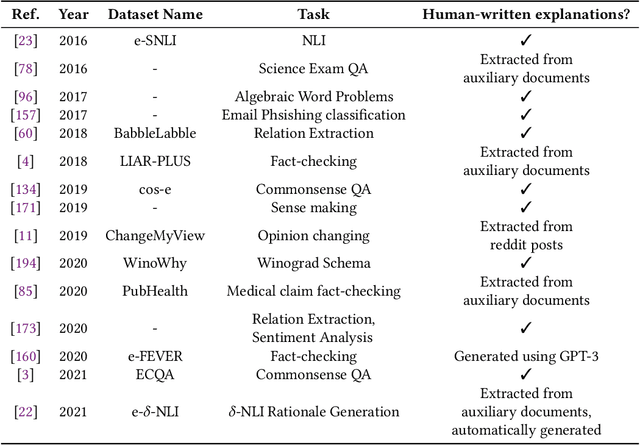
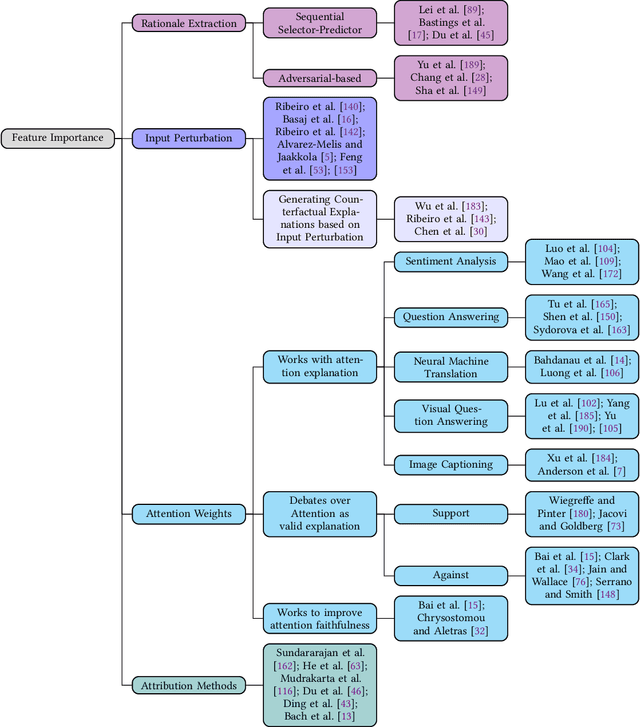
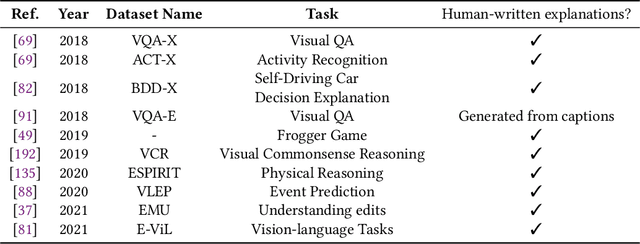
As the use of deep learning techniques has grown across various fields over the past decade, complaints about the opaqueness of the black-box models have increased, resulting in an increased focus on transparency in deep learning models. This work investigates various methods to improve the interpretability of deep neural networks for natural language processing (NLP) tasks, including machine translation and sentiment analysis. We provide a comprehensive discussion on the definition of the term \textit{interpretability} and its various aspects at the beginning of this work. The methods collected and summarised in this survey are only associated with local interpretation and are divided into three categories: 1) explaining the model's predictions through related input features; 2) explaining through natural language explanation; 3) probing the hidden states of models and word representations.