 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCO-VIST: Social Interaction Commonsense Knowledge-based Visual Storytelling
Paper and Code
Feb 01, 2024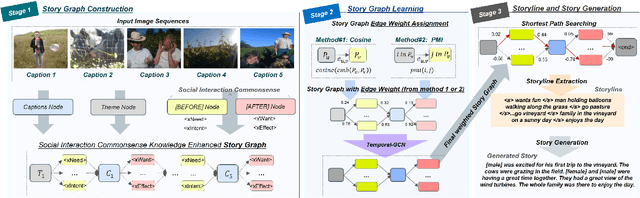

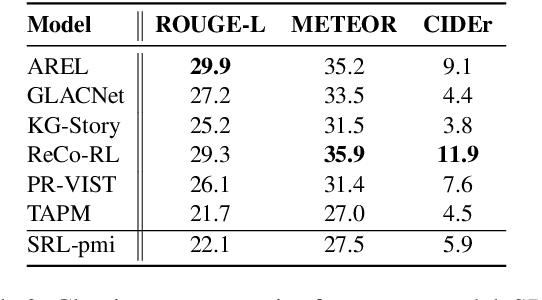
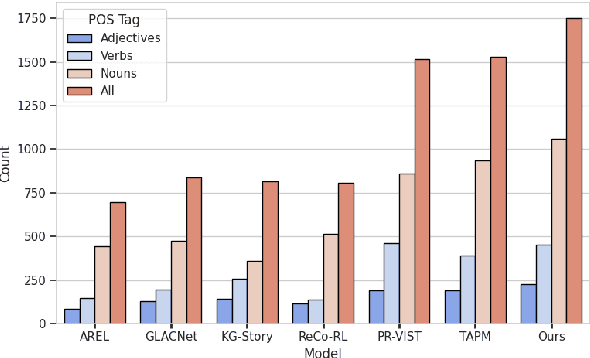
Visual storytelling aims to automatically generate a coherent story based on a given image sequence. Unlike tasks like image captioning, visual stories should contain factual descriptions, worldviews, and human social commonsense to put disjointed elements together to form a coherent and engaging human-writeable story. However, most models mainly focus on applying factual information and using taxonomic/lexical external knowledge when attempting to create stories. This paper introduces SCO-VIST, a framework representing the image sequence as a graph with objects and relations that includes human action motivation and its social interaction commonsense knowledge. SCO-VIST then takes this graph representing plot points and creates bridges between plot points with semantic and occurrence-based edge weights. This weighted story graph produces the storyline in a sequence of events using Floyd-Warshall's algorithm. Our proposed framework produces stories superior across multiple metrics in terms of visual grounding, coherence, diversity, and humanness, per both automatic and human evaluations.