 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware segmentation for rainfall prediction post processing
Aug 28, 2024

Accurate precipitation forecasts are crucial for applications such as flood management, agricultural planning, water resource allocation, and weather warnings. Despite advances in numerical weather prediction (NWP) models, they still exhibit significant biases and uncertainties, especially at high spatial and temporal resolutions. To address these limitations, we explore uncertainty-aware deep learning models for post-processing daily cumulative quantitative precipitation forecasts to obtain forecast uncertainties that lead to a better trade-off between accuracy and reliability. Our study compares different state-of-the-art models, and we propose a variant of the well-known SDE-Net, called SDE U-Net, tailored to segmentation problems like ours. We evaluate its performance for both typical and intense precipitation events. Our results show that all deep learning models significantly outperform the average baseline NWP solution, with our implementation of the SDE U-Net showing the best trade-off between accuracy and reliability. Integrating these models, which account for uncertainty, into operational forecasting systems can improve decision-making and preparedness for weather-related events.
Level Up Your Tutorials: VLMs for Game Tutorials Quality Assessment
Aug 15, 2024



Designing effective game tutorials is crucial for a smooth learning curve for new players, especially in games with many rules and complex core mechanics. Evaluating the effectiveness of these tutorials usually requires multiple iterations with testers who have no prior knowledge of the game. Recent Vision-Language Models (VLMs) have demonstrated significant capabilities in understanding and interpreting visual content. VLMs can analyze images, provide detailed insights, and answer questions about their content. They can recognize objects, actions, and contexts in visual data, making them valuable tools for various applications, including automated game testing. In this work, we propose an automated game-testing solution to evaluate the quality of game tutorials. Our approach leverages VLMs to analyze frames from video game tutorials, answer relevant questions to simulate human perception, and provide feedback. This feedback is compared with expected results to identify confusing or problematic scenes and highlight potential errors for developers. In addition, we publish complete tutorial videos and annotated frames from different game versions used in our tests. This solution reduces the need for extensive manual testing, especially by speeding up and simplifying the initial development stages of the tutorial to improve the final game experience.
Unsupervised Concept Drift Detection from Deep Learning Representations in Real-time
Jun 24, 2024



Concept Drift is a phenomenon in which the underlying data distribution and statistical properties of a target domain change over time, leading to a degradation of the model's performance. Consequently, models deployed in production require continuous monitoring through drift detection techniques. Most drift detection methods to date are supervised, i.e., based on ground-truth labels. However, true labels are usually not available in many real-world scenarios. Although recent efforts have been made to develop unsupervised methods, they often lack the required accuracy, have a complexity that makes real-time implementation in production environments difficult, or are unable to effectively characterize drift. To address these challenges, we propose DriftLens, an unsupervised real-time concept drift detection framework. It works on unstructured data by exploiting the distribution distances of deep learning representations. DriftLens can also provide drift characterization by analyzing each label separately. A comprehensive experimental evaluation is presented with multiple deep learning classifiers for text, image, and speech. Results show that (i) DriftLens performs better than previous methods in detecting drift in $11/13$ use cases; (ii) it runs at least 5 times faster; (iii) its detected drift value is very coherent with the amount of drift (correlation $\geq 0.85$); (iv) it is robust to parameter changes.
Explaining the Deep Natural Language Processing by Mining Textual Interpretable Features
Jun 12, 2021
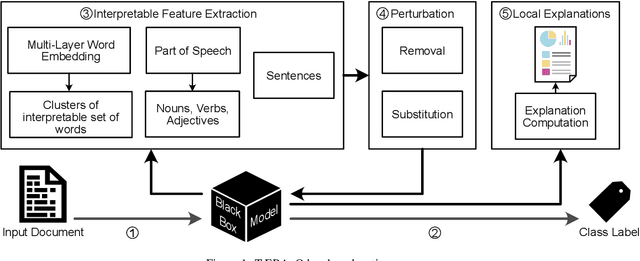
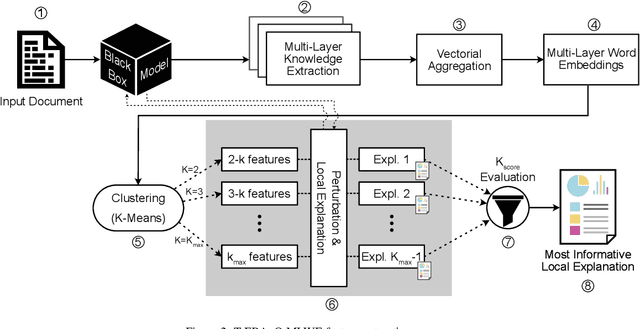
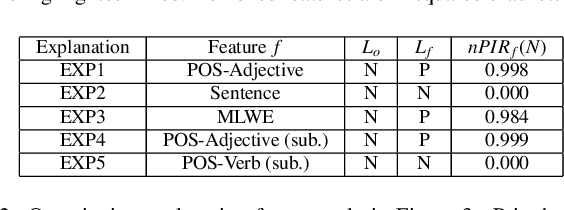
Despite the high accuracy offered by state-of-the-art deep natural-language models (e.g. LSTM, BERT), their application in real-life settings is still widely limited, as they behave like a black-box to the end-user. Hence, explainability is rapidly becoming a fundamental requirement of future-generation data-driven systems based on deep-learning approaches. Several attempts to fulfill the existing gap between accuracy and interpretability have been done. However, robust and specialized xAI (Explainable Artificial Intelligence) solutions tailored to deep natural-language models are still missing. We propose a new framework, named T-EBAnO, which provides innovative prediction-local and class-based model-global explanation strategies tailored to black-box deep natural-language models. Given a deep NLP model and the textual input data, T-EBAnO provides an objective, human-readable, domain-specific assessment of the reasons behind the automatic decision-making process. Specifically, the framework extracts sets of interpretable features mining the inner knowledge of the model. Then, it quantifies the influence of each feature during the prediction process by exploiting the novel normalized Perturbation Influence Relation index at the local level and the novel Global Absolute Influence and Global Relative Influence indexes at the global level. The effectiveness and the quality of the local and global explanations obtained with T-EBAnO are proved on (i) a sentiment analysis task performed by a fine-tuned BERT model, and (ii) a toxic comment classification task performed by an LSTM model.
Automating concept-drift detection by self-evaluating predictive model degradation
Jul 18, 2019
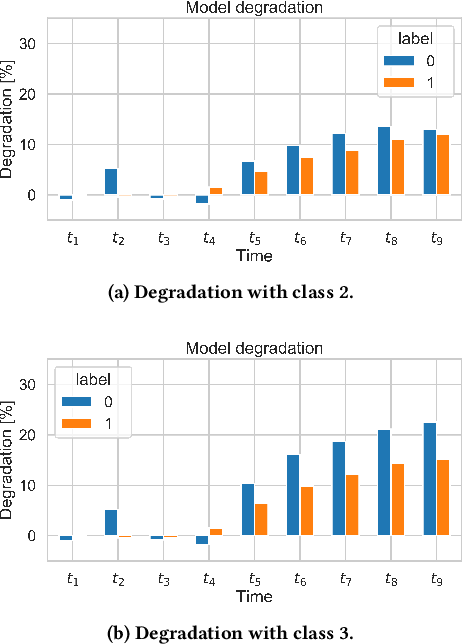
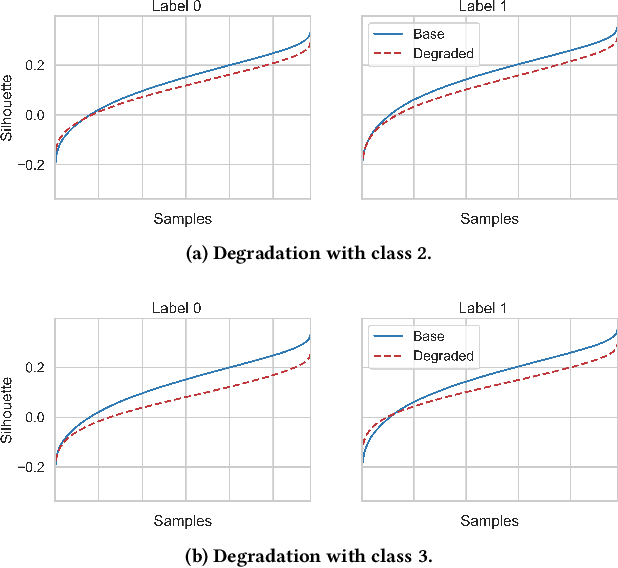
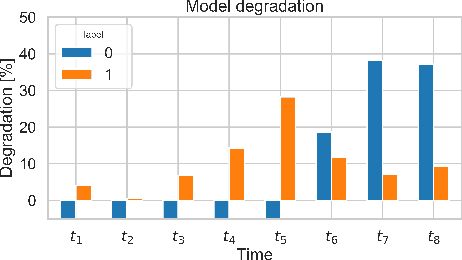
A key aspect of automating predictive machine learning entails the capability of properly triggering the update of the trained model. To this aim, suitable automatic solutions to self-assess the prediction quality and the data distribution drift between the original training set and the new data have to be devised. In this paper, we propose a novel methodology to automatically detect prediction-quality degradation of machine learning models due to class-based concept drift, i.e., when new data contains samples that do not fit the set of class labels known by the currently-trained predictive model. Experiments on synthetic and real-world public datasets show the effectiveness of the proposed methodology in automatically detecting and describing concept drift caused by changes in the class-label data distributions.