 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuerying Large Language Models with SQL
Apr 02, 2023



In many use-cases, information is stored in text but not available in structured data. However, extracting data from natural language text to precisely fit a schema, and thus enable querying, is a challenging task. With the rise of pre-trained Large Language Models (LLMs), there is now an effective solution to store and use information extracted from massive corpora of text documents. Thus, we envision the use of SQL queries to cover a broad range of data that is not captured by traditional databases by tapping the information in LLMs. To ground this vision, we present Galois, a prototype based on a traditional database architecture, but with new physical operators for querying the underlying LLM. The main idea is to execute some operators of the the query plan with prompts that retrieve data from the LLM. For a large class of SQL queries, querying LLMs returns well structured relations, with encouraging qualitative results. Preliminary experimental results make pre-trained LLMs a promising addition to the field of database systems, introducing a new direction for hybrid query processing. However, we pinpoint several research challenges that must be addressed to build a DBMS that exploits LLMs. While some of these challenges necessitate integrating concepts from the NLP literature, others offer novel research avenues for the DB community.
Crowdsourced Fact-Checking at Twitter: How Does the Crowd Compare With Experts?
Aug 19, 2022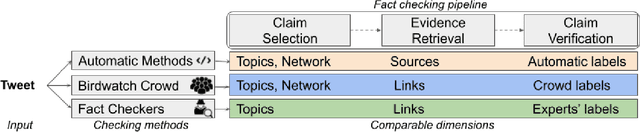
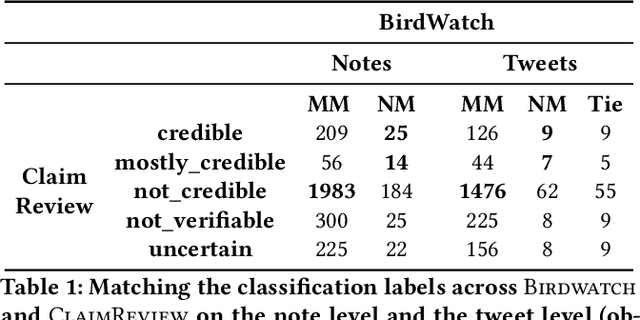

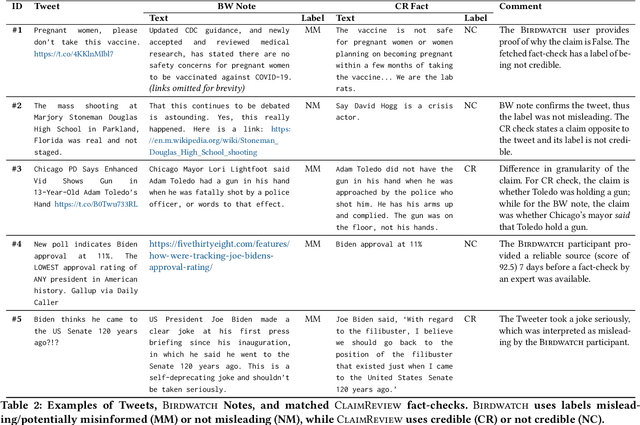
Fact-checking is one of the effective solutions in fighting online misinformation. However, traditional fact-checking is a process requiring scarce expert human resources, and thus does not scale well on social media because of the continuous flow of new content to be checked. Methods based on crowdsourcing have been proposed to tackle this challenge, as they can scale with a smaller cost, but, while they have shown to be feasible, have always been studied in controlled environments. In this work, we study the first large-scale effort of crowdsourced fact-checking deployed in practice, started by Twitter with the Birdwatch program. Our analysis shows that crowdsourcing may be an effective fact-checking strategy in some settings, even comparable to results obtained by human experts, but does not lead to consistent, actionable results in others. We processed 11.9k tweets verified by the Birdwatch program and report empirical evidence of i) differences in how the crowd and experts select content to be fact-checked, ii) how the crowd and the experts retrieve different resources to fact-check, and iii) the edge the crowd shows in fact-checking scalability and efficiency as compared to expert checkers.
RuleBert: Teaching Soft Rules to Pre-trained Language Models
Sep 24, 2021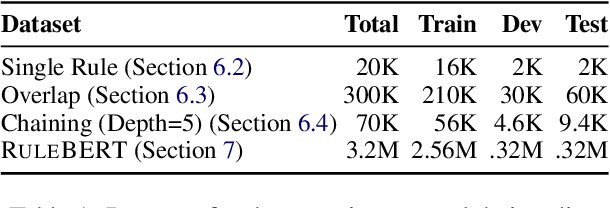
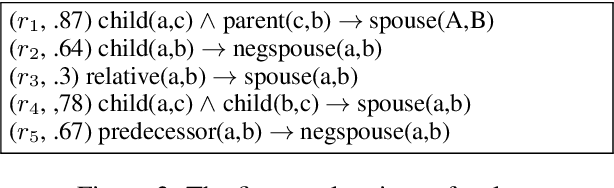
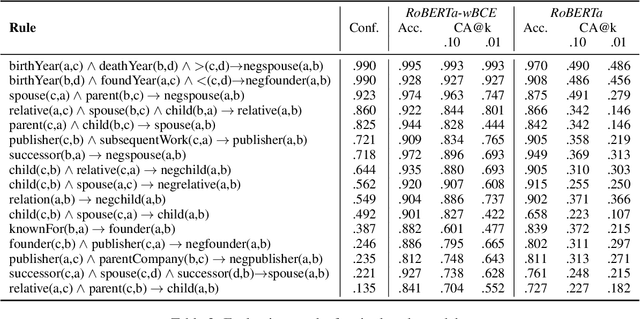
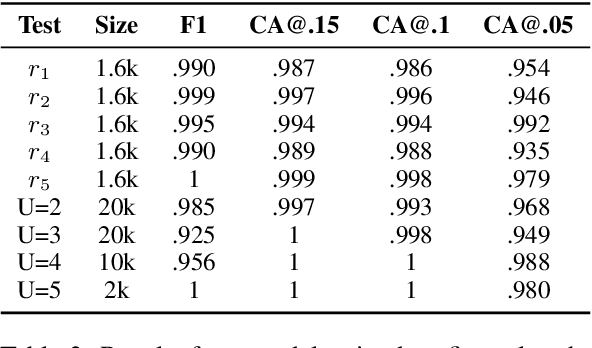
While pre-trained language models (PLMs) are the go-to solution to tackle many natural language processing problems, they are still very limited in their ability to capture and to use common-sense knowledge. In fact, even if information is available in the form of approximate (soft) logical rules, it is not clear how to transfer it to a PLM in order to improve its performance for deductive reasoning tasks. Here, we aim to bridge this gap by teaching PLMs how to reason with soft Horn rules. We introduce a classification task where, given facts and soft rules, the PLM should return a prediction with a probability for a given hypothesis. We release the first dataset for this task, and we propose a revised loss function that enables the PLM to learn how to predict precise probabilities for the task. Our evaluation results show that the resulting fine-tuned models achieve very high performance, even on logical rules that were unseen at training. Moreover, we demonstrate that logical notions expressed by the rules are transferred to the fine-tuned model, yielding state-of-the-art results on external datasets.
* Logical reasoning, soft Horn rules, Transformers, pre-trained language models, combining symbolic and probabilistic methods, BERT
Explainable Fact Checking with Probabilistic Answer Set Programming
Jun 21, 2019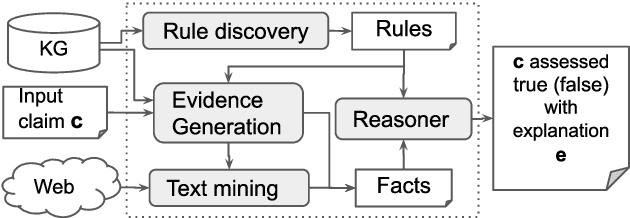

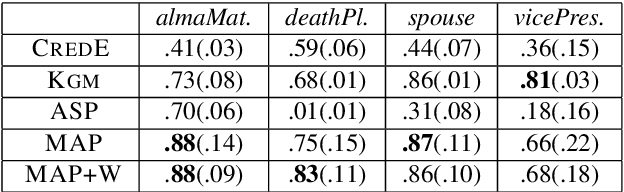
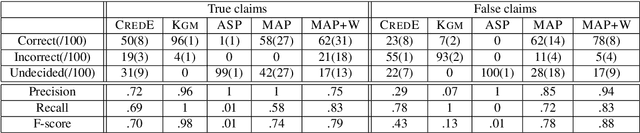
One challenge in fact checking is the ability to improve the transparency of the decision. We present a fact checking method that uses reference information in knowledge graphs (KGs) to assess claims and explain its decisions. KGs contain a formal representation of knowledge with semantic descriptions of entities and their relationships. We exploit such rich semantics to produce interpretable explanations for the fact checking output. As information in a KG is inevitably incomplete, we rely on logical rule discovery and on Web text mining to gather the evidence to assess a given claim. Uncertain rules and facts are turned into logical programs and the checking task is modeled as an inference problem in a probabilistic extension of answer set programs. Experiments show that the probabilistic inference enables the efficient labeling of claims with interpretable explanations, and the quality of the results is higher than state of the art baselines.