 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Matching of Data and Text
Dec 16, 2021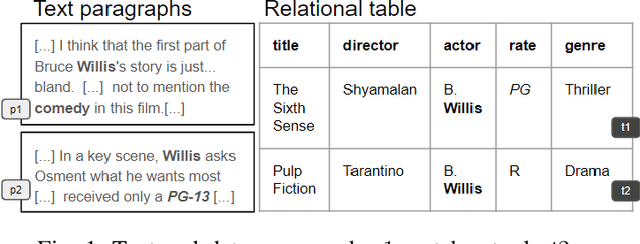
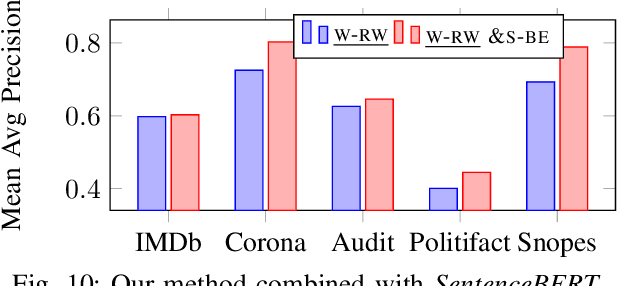

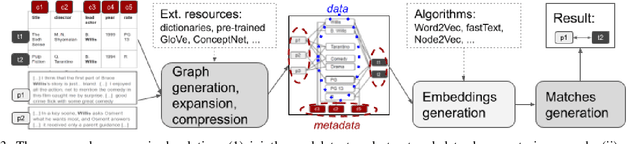
Entity resolution is a widely studied problem with several proposals to match records across relations. Matching textual content is a widespread task in many applications, such as question answering and search. While recent methods achieve promising results for these two tasks, there is no clear solution for the more general problem of matching textual content and structured data. We introduce a framework that supports this new task in an unsupervised setting for any pair of corpora, being relational tables or text documents. Our method builds a fine-grained graph over the content of the corpora and derives word embeddings to represent the objects to match in a low dimensional space. The learned representation enables effective and efficient matching at different granularity, from relational tuples to text sentences and paragraphs. Our flexible framework can exploit pre-trained resources, but it does not depends on their existence and achieves better quality performance in matching content when the vocabulary is domain specific. We also introduce optimizations in the graph creation process with an "expand and compress" approach that first identifies new valid relationships across elements, to improve matching, and then prunes nodes and edges, to reduce the graph size. Experiments on real use cases and public datasets show that our framework produces embeddings that outperform word embeddings and fine-tuned language models both in results' quality and in execution times.
RuleBert: Teaching Soft Rules to Pre-trained Language Models
Sep 24, 2021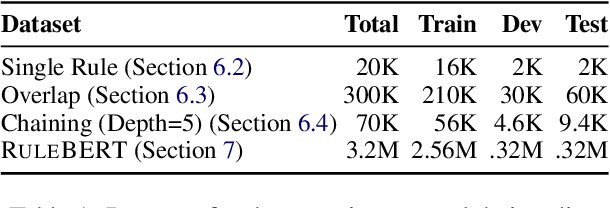
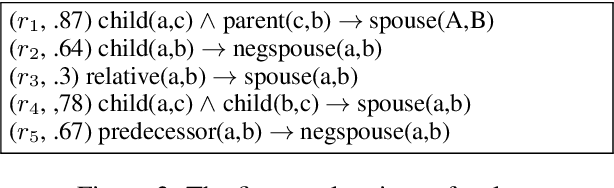
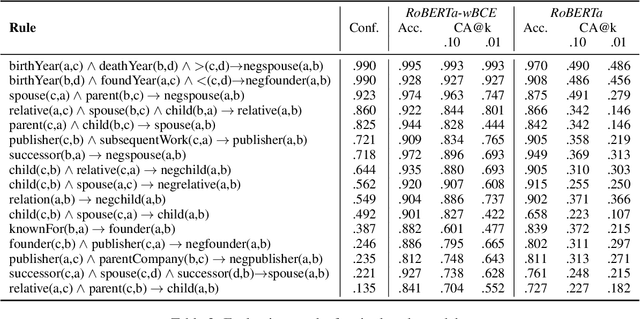
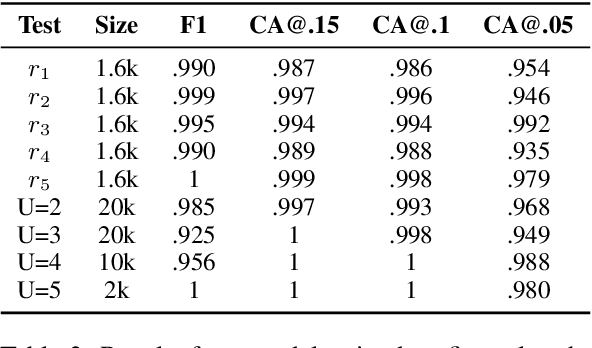
While pre-trained language models (PLMs) are the go-to solution to tackle many natural language processing problems, they are still very limited in their ability to capture and to use common-sense knowledge. In fact, even if information is available in the form of approximate (soft) logical rules, it is not clear how to transfer it to a PLM in order to improve its performance for deductive reasoning tasks. Here, we aim to bridge this gap by teaching PLMs how to reason with soft Horn rules. We introduce a classification task where, given facts and soft rules, the PLM should return a prediction with a probability for a given hypothesis. We release the first dataset for this task, and we propose a revised loss function that enables the PLM to learn how to predict precise probabilities for the task. Our evaluation results show that the resulting fine-tuned models achieve very high performance, even on logical rules that were unseen at training. Moreover, we demonstrate that logical notions expressed by the rules are transferred to the fine-tuned model, yielding state-of-the-art results on external datasets.
* Logical reasoning, soft Horn rules, Transformers, pre-trained language models, combining symbolic and probabilistic methods, BERT
Explainable Fact Checking with Probabilistic Answer Set Programming
Jun 21, 2019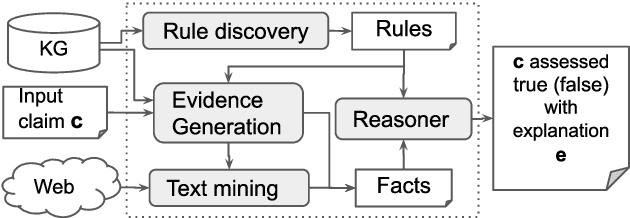

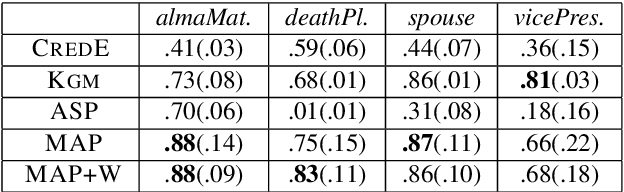
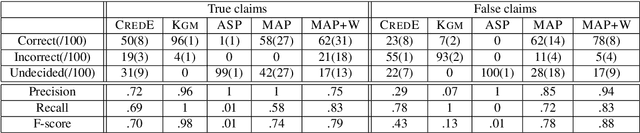
One challenge in fact checking is the ability to improve the transparency of the decision. We present a fact checking method that uses reference information in knowledge graphs (KGs) to assess claims and explain its decisions. KGs contain a formal representation of knowledge with semantic descriptions of entities and their relationships. We exploit such rich semantics to produce interpretable explanations for the fact checking output. As information in a KG is inevitably incomplete, we rely on logical rule discovery and on Web text mining to gather the evidence to assess a given claim. Uncertain rules and facts are turned into logical programs and the checking task is modeled as an inference problem in a probabilistic extension of answer set programs. Experiments show that the probabilistic inference enables the efficient labeling of claims with interpretable explanations, and the quality of the results is higher than state of the art baselines.