 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Sequential Query Recommendation with Immediate User Feedback
May 12, 2022
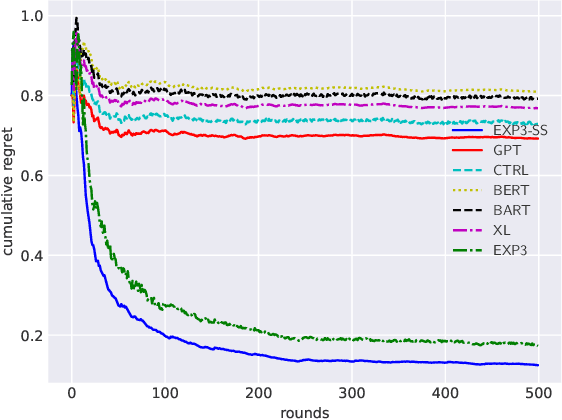
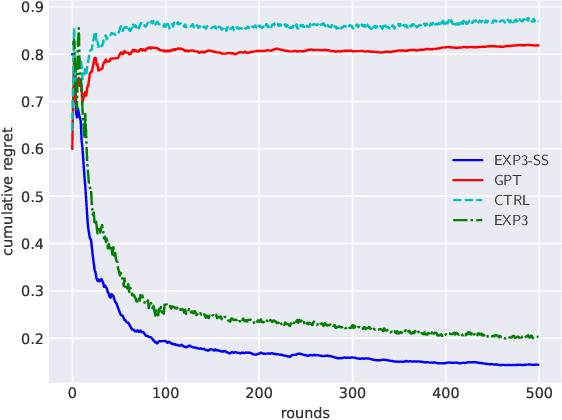
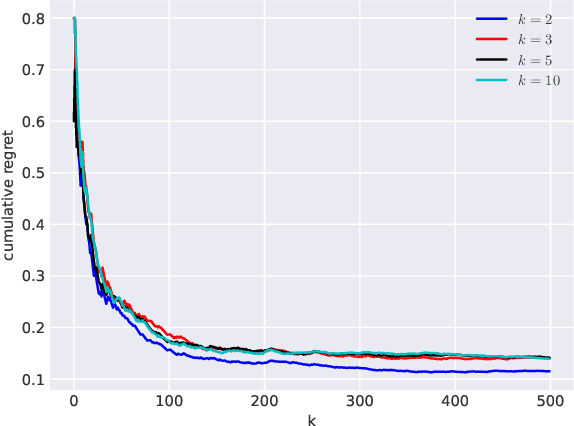
We propose an algorithm for next query recommendation in interactive data exploration settings, like knowledge discovery for information gathering. The state-of-the-art query recommendation algorithms are based on sequence-to-sequence learning approaches that exploit historical interaction data. We propose to augment the transformer-based causal language models for query recommendations to adapt to the immediate user feedback using multi-armed bandit (MAB) framework. We conduct a large-scale experimental study using log files from a popular online literature discovery service and demonstrate that our algorithm improves the cumulative regret substantially, with respect to the state-of-the-art transformer-based query recommendation models, which do not make use of the immediate user feedback. Our data model and source code are available at ~\url{https://anonymous.4open.science/r/exp3_ss-9985/}.
Re-ranking Based Diversification: A Unifying View
Jun 26, 2019
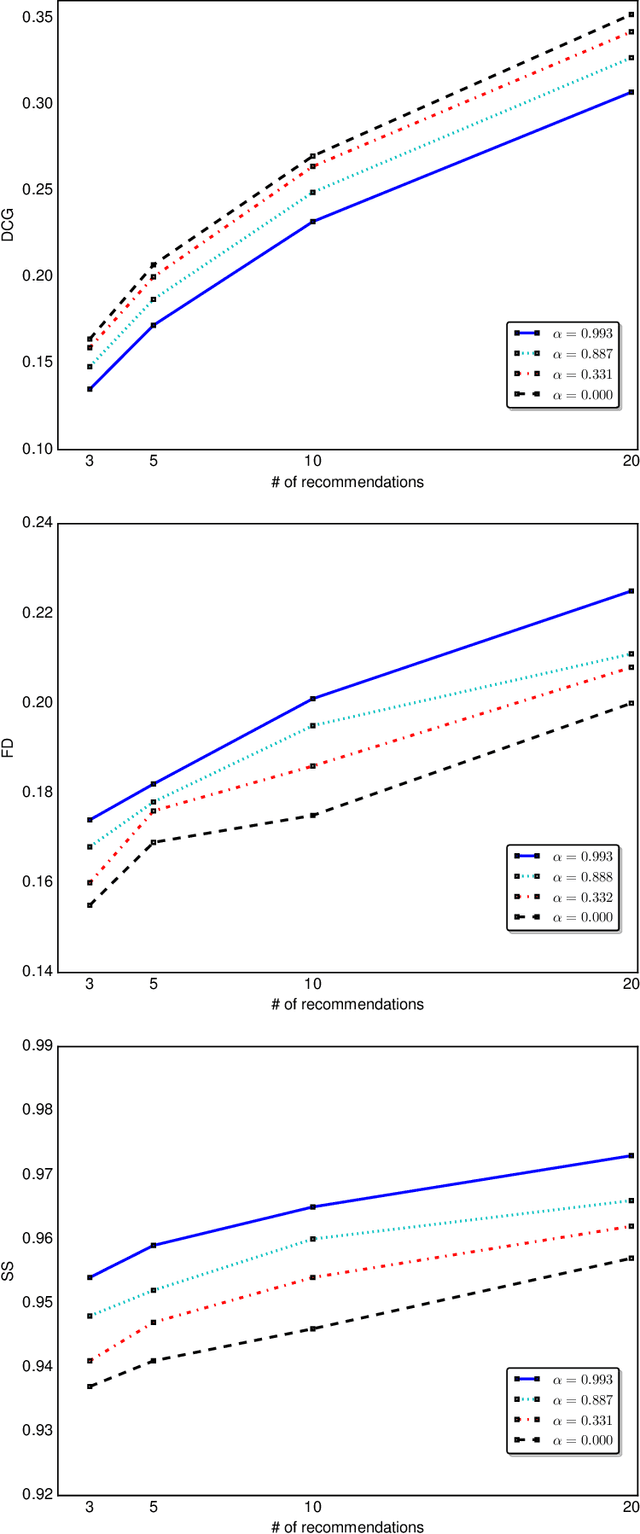
We analyze different re-ranking algorithms for diversification and show that majority of them are based on maximizing submodular/modular functions from the class of parameterized concave/linear over modular functions. We study the optimality of such algorithms in terms of the `total curvature'. We also show that by adjusting the hyperparameter of the concave/linear composition to trade-off relevance and diversity, if any, one is in fact tuning the `total curvature' of the function for relevance-diversity trade-off.
Risk Aware Ranking for Top-$k$ Recommendations
Apr 12, 2019
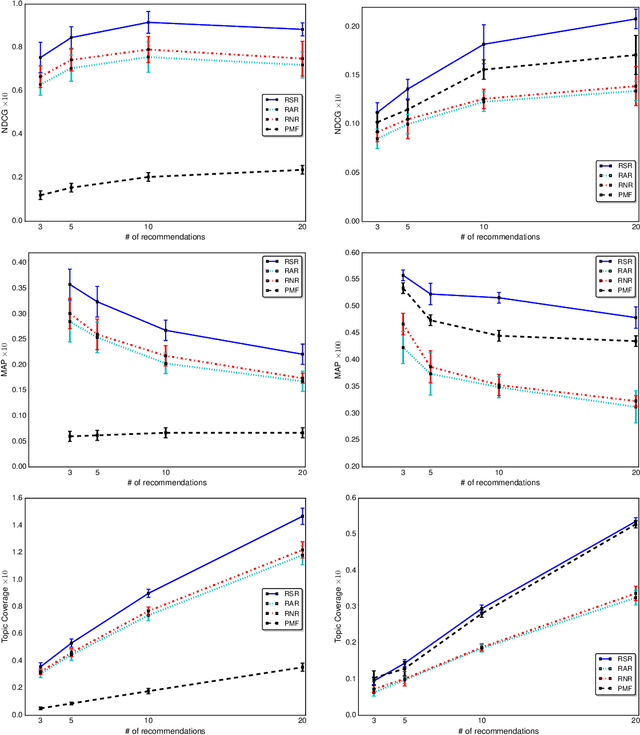
Given an incomplete ratings data over a set of users and items, the preference completion problem aims to estimate a personalized total preference order over a subset of the items. In practical settings, a ranked list of top-$k$ items from the estimated preference order is recommended to the end user in the decreasing order of preference for final consumption. We analyze this model and observe that such a ranking model results in suboptimal performance when the payoff associated with the recommended items is different. We propose a novel and very efficient algorithm for the preference ranking considering the uncertainty regarding the payoffs of the items. Once the preference scores for the users are obtained using any preference learning algorithm, we show that ranking the items using a risk seeking utility function results in the best ranking performance.
Reuse and Adaptation for Entity Resolution through Transfer Learning
Sep 28, 2018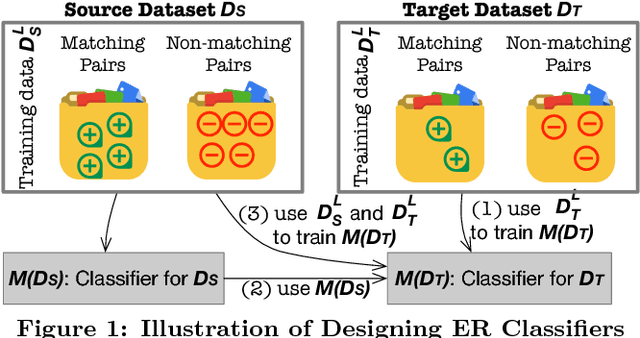
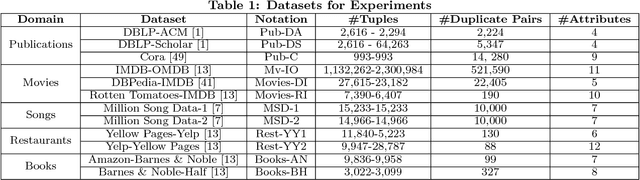
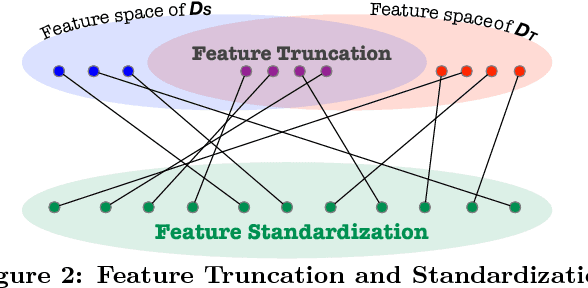

Entity resolution (ER) is one of the fundamental problems in data integration, where machine learning (ML) based classifiers often provide the state-of-the-art results. Considerable human effort goes into feature engineering and training data creation. In this paper, we investigate a new problem: Given a dataset D_T for ER with limited or no training data, is it possible to train a good ML classifier on D_T by reusing and adapting the training data of dataset D_S from same or related domain? Our major contributions include (1) a distributed representation based approach to encode each tuple from diverse datasets into a standard feature space; (2) identification of common scenarios where the reuse of training data can be beneficial; and (3) five algorithms for handling each of the aforementioned scenarios. We have performed comprehensive experiments on 12 datasets from 5 different domains (publications, movies, songs, restaurants, and books). Our experiments show that our algorithms provide significant benefits such as providing superior performance for a fixed training data size.
Theory of Optimizing Pseudolinear Performance Measures: Application to F-measure
Jan 01, 2018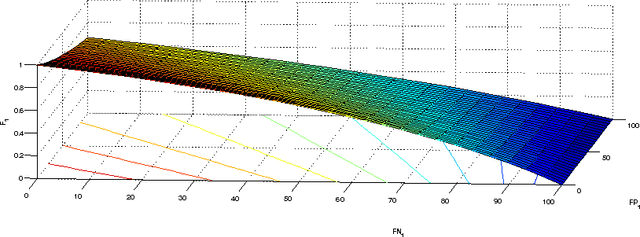
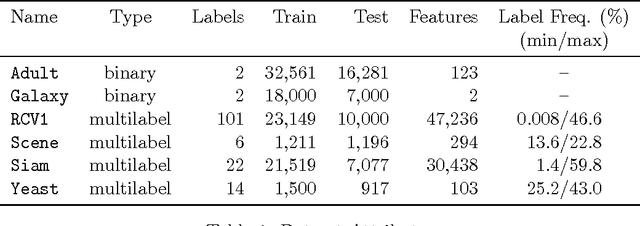
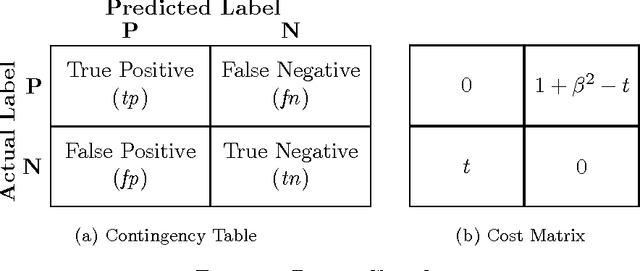

Non-linear performance measures are widely used for the evaluation of learning algorithms. For example, $F$-measure is a commonly used performance measure for classification problems in machine learning and information retrieval community. We study the theoretical properties of a subset of non-linear performance measures called pseudo-linear performance measures which includes $F$-measure, \emph{Jaccard Index}, among many others. We establish that many notions of $F$-measures and \emph{Jaccard Index} are pseudo-linear functions of the per-class false negatives and false positives for binary, multiclass and multilabel classification. Based on this observation, we present a general reduction of such performance measure optimization problem to cost-sensitive classification problem with unknown costs. We then propose an algorithm with provable guarantees to obtain an approximately optimal classifier for the $F$-measure by solving a series of cost-sensitive classification problems. The strength of our analysis is to be valid on any dataset and any class of classifiers, extending the existing theoretical results on pseudo-linear measures, which are asymptotic in nature. We also establish the multi-objective nature of the $F$-score maximization problem by linking the algorithm with the weighted-sum approach used in multi-objective optimization. We present numerical experiments to illustrate the relative importance of cost asymmetry and thresholding when learning linear classifiers on various $F$-measure optimization tasks.
SAGA: A Submodular Greedy Algorithm For Group Recommendation
Dec 25, 2017
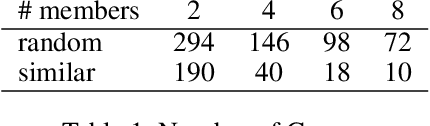
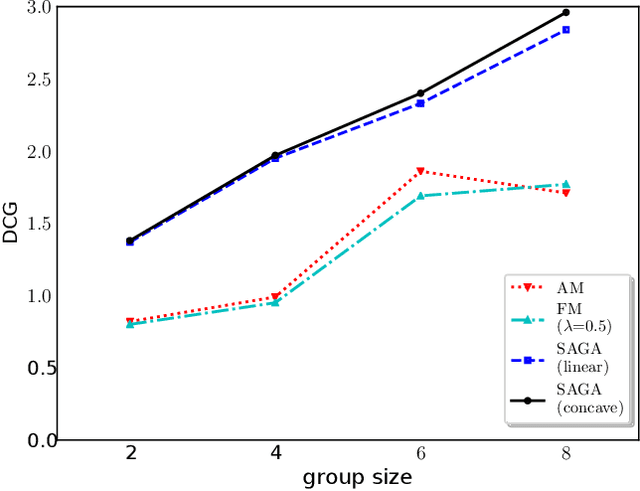
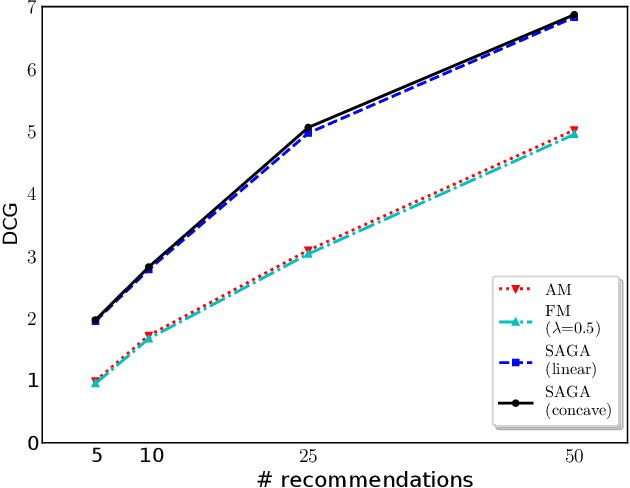
In this paper, we propose a unified framework and an algorithm for the problem of group recommendation where a fixed number of items or alternatives can be recommended to a group of users. The problem of group recommendation arises naturally in many real world contexts, and is closely related to the budgeted social choice problem studied in economics. We frame the group recommendation problem as choosing a subgraph with the largest group consensus score in a completely connected graph defined over the item affinity matrix. We propose a fast greedy algorithm with strong theoretical guarantees, and show that the proposed algorithm compares favorably to the state-of-the-art group recommendation algorithms according to commonly used relevance and coverage performance measures on benchmark dataset.
Topic Extraction and Bundling of Related Scientific Articles
May 01, 2015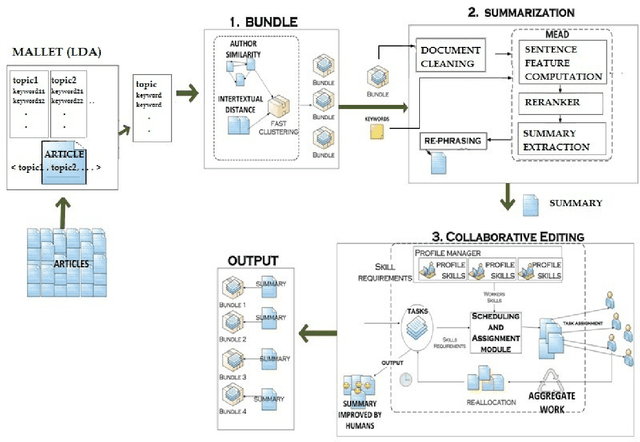

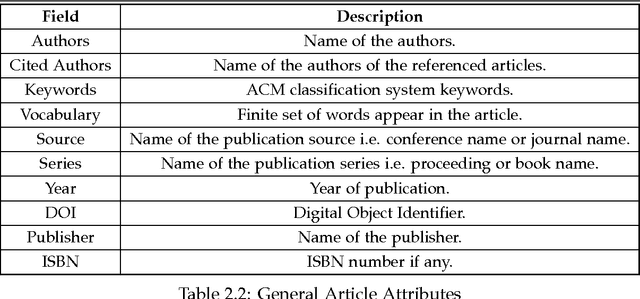
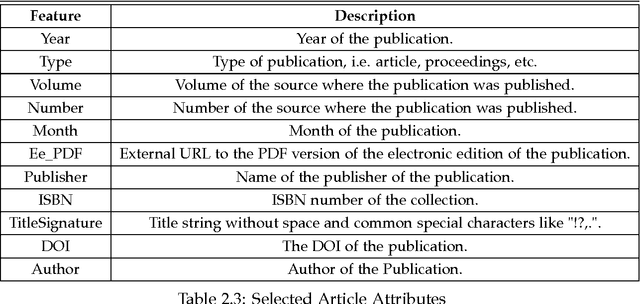
Automatic classification of scientific articles based on common characteristics is an interesting problem with many applications in digital library and information retrieval systems. Properly organized articles can be useful for automatic generation of taxonomies in scientific writings, textual summarization, efficient information retrieval etc. Generating article bundles from a large number of input articles, based on the associated features of the articles is tedious and computationally expensive task. In this report we propose an automatic two-step approach for topic extraction and bundling of related articles from a set of scientific articles in real-time. For topic extraction, we make use of Latent Dirichlet Allocation (LDA) topic modeling techniques and for bundling, we make use of hierarchical agglomerative clustering techniques. We run experiments to validate our bundling semantics and compare it with existing models in use. We make use of an online crowdsourcing marketplace provided by Amazon called Amazon Mechanical Turk to carry out experiments. We explain our experimental setup and empirical results in detail and show that our method is advantageous over existing ones.