 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Extraction and Bundling of Related Scientific Articles
Paper and Code
May 01, 2015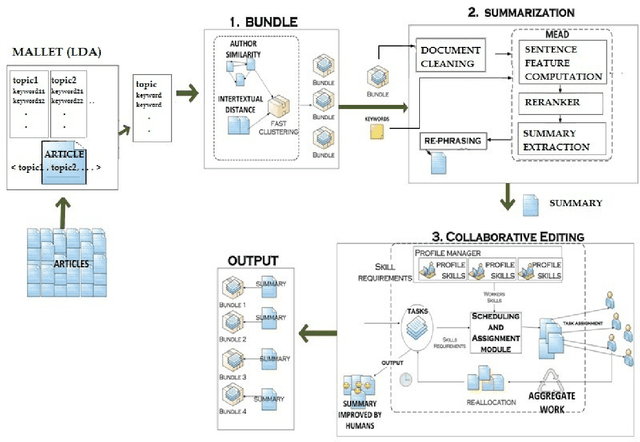

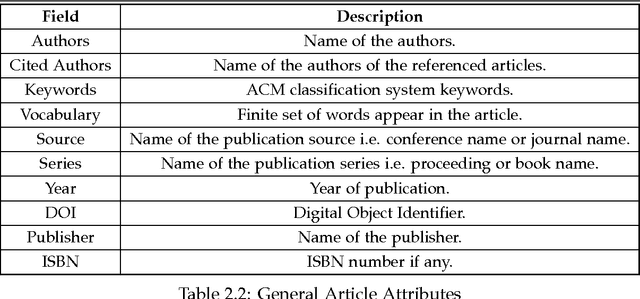
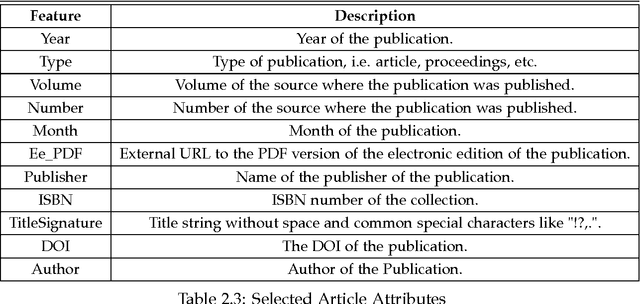
Automatic classification of scientific articles based on common characteristics is an interesting problem with many applications in digital library and information retrieval systems. Properly organized articles can be useful for automatic generation of taxonomies in scientific writings, textual summarization, efficient information retrieval etc. Generating article bundles from a large number of input articles, based on the associated features of the articles is tedious and computationally expensive task. In this report we propose an automatic two-step approach for topic extraction and bundling of related articles from a set of scientific articles in real-time. For topic extraction, we make use of Latent Dirichlet Allocation (LDA) topic modeling techniques and for bundling, we make use of hierarchical agglomerative clustering techniques. We run experiments to validate our bundling semantics and compare it with existing models in use. We make use of an online crowdsourcing marketplace provided by Amazon called Amazon Mechanical Turk to carry out experiments. We explain our experimental setup and empirical results in detail and show that our method is advantageous over existing ones.