 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Superclasses for Learning from Hierarchical Databases
Nov 25, 2024In many large-scale classification problems, classes are organized in a known hierarchy, typically represented as a tree expressing the inclusion of classes in superclasses. We introduce a loss for this type of supervised hierarchical classification. It utilizes the knowledge of the hierarchy to assign each example not only to a class but also to all encompassing superclasses. Applicable to any feedforward architecture with a softmax output layer, this loss is a proper scoring rule, in that its expectation is minimized by the true posterior class probabilities. This property allows us to simultaneously pursue consistent classification objectives between superclasses and fine-grained classes, and eliminates the need for a performance trade-off between different granularities. We conduct an experimental study on three reference benchmarks, in which we vary the size of the training sets to cover a diverse set of learning scenarios. Our approach does not entail any significant additional computational cost compared with the loss of cross-entropy. It improves accuracy and reduces the number of coarse errors, with predicted labels that are distant from ground-truth labels in the tree.
Learning from missing data with the Latent Block Model
Oct 23, 2020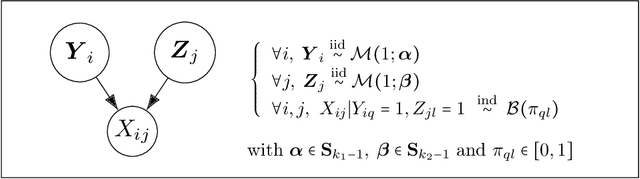

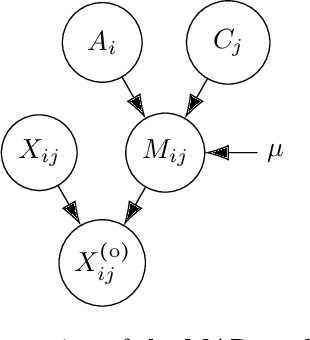
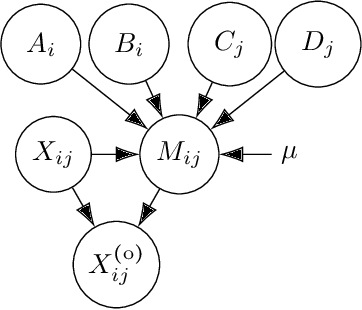
Missing data can be informative. Ignoring this information can lead to misleading conclusions when the data model does not allow information to be extracted from the missing data. We propose a co-clustering model, based on the Latent Block Model, that aims to take advantage of this nonignorable nonresponses, also known as Missing Not At Random data (MNAR). A variational expectation-maximization algorithm is derived to perform inference and a model selection criterion is presented. We assess the proposed approach on a simulation study, before using our model on the voting records from the lower house of the French Parliament, where our analysis brings out relevant groups of MPs and texts, together with a sensible interpretation of the behavior of non-voters.
Driving among Flatmobiles: Bird-Eye-View occupancy grids from a monocular camera for holistic trajectory planning
Aug 10, 2020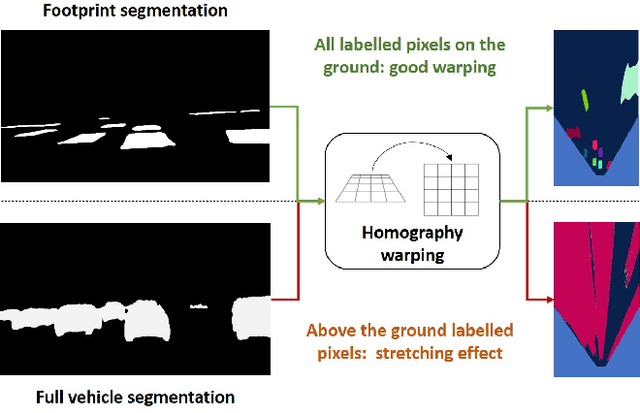
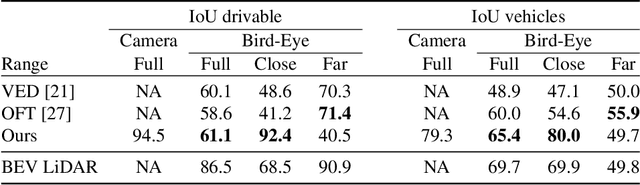

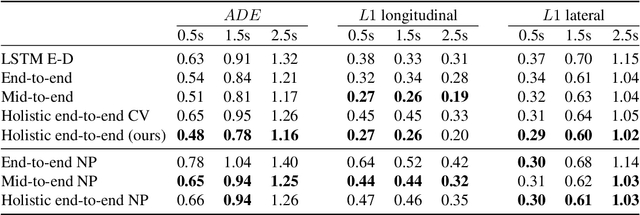
Camera-based end-to-end driving neural networks bring the promise of a low-cost system that maps camera images to driving control commands. These networks are appealing because they replace laborious hand engineered building blocks but their black-box nature makes them difficult to delve in case of failure. Recent works have shown the importance of using an explicit intermediate representation that has the benefits of increasing both the interpretability and the accuracy of networks' decisions. Nonetheless, these camera-based networks reason in camera view where scale is not homogeneous and hence not directly suitable for motion forecasting. In this paper, we introduce a novel monocular camera-only holistic end-to-end trajectory planning network with a Bird-Eye-View (BEV) intermediate representation that comes in the form of binary Occupancy Grid Maps (OGMs). To ease the prediction of OGMs in BEV from camera images, we introduce a novel scheme where the OGMs are first predicted as semantic masks in camera view and then warped in BEV using the homography between the two planes. The key element allowing this transformation to be applied to 3D objects such as vehicles, consists in predicting solely their footprint in camera-view, hence respecting the flat world hypothesis implied by the homography.
Representation Transfer by Optimal Transport
Jul 13, 2020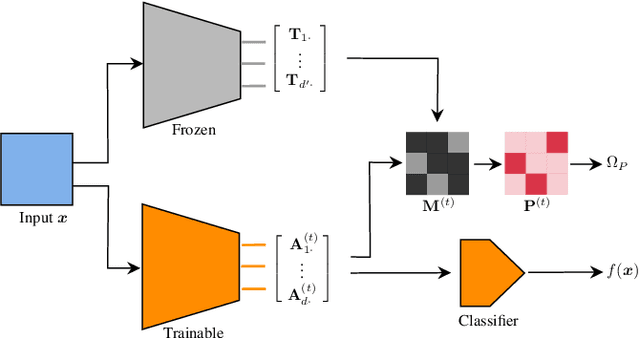


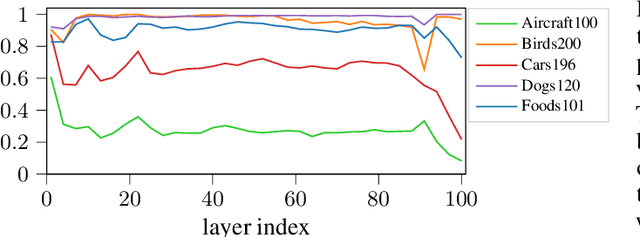
Deep learning currently provides the best representations of complex objects for a wide variety of tasks. However, learning these representations is an expensive process that requires very large training samples and significant computing resources. Thankfully, sharing these representations is a common practice, enabling to solve new tasks with relatively little training data and few computing resources; the transfer of representations is nowadays an essential ingredient in numerous real-world applications of deep learning. Transferring representations commonly relies on the parameterized form of the features making up the representation, as encoded by the computational graph of these features. In this paper, we propose to use a novel non-parametric metric between representations. It is based on a functional view of features, and takes into account certain invariances of representations, such as the permutation of their features, by relying on optimal transport. This distance is used as a regularization term promoting similarity between two representations. We show the relevance of this approach in two representation transfer settings, where the representation of a trained reference model is transferred to another one, for solving a new related task (inductive transfer learning), or for distilling knowledge to a simpler model (model compression).
Explicit Inductive Bias for Transfer Learning with Convolutional Networks
Jun 06, 2018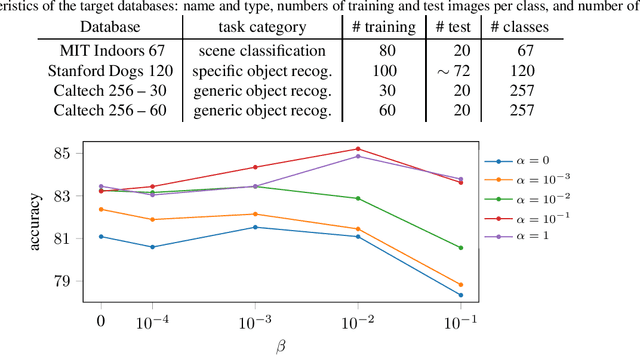

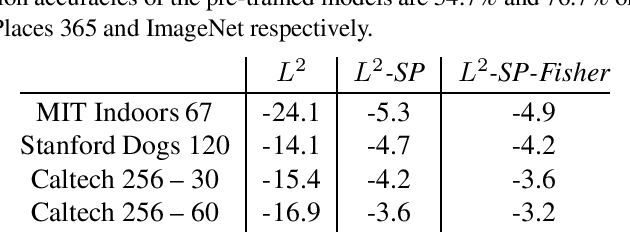

In inductive transfer learning, fine-tuning pre-trained convolutional networks substantially outperforms training from scratch. When using fine-tuning, the underlying assumption is that the pre-trained model extracts generic features, which are at least partially relevant for solving the target task, but would be difficult to extract from the limited amount of data available on the target task. However, besides the initialization with the pre-trained model and the early stopping, there is no mechanism in fine-tuning for retaining the features learned on the source task. In this paper, we investigate several regularization schemes that explicitly promote the similarity of the final solution with the initial model. We show the benefit of having an explicit inductive bias towards the initial model, and we eventually recommend a simple $L^2$ penalty with the pre-trained model being a reference as the baseline of penalty for transfer learning tasks.
Theory of Optimizing Pseudolinear Performance Measures: Application to F-measure
Jan 01, 2018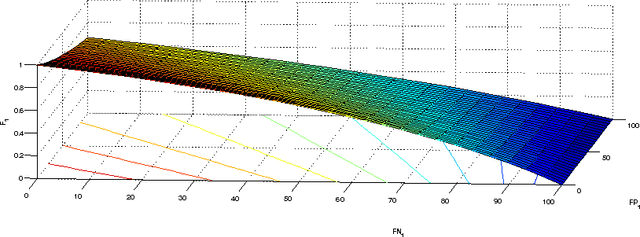
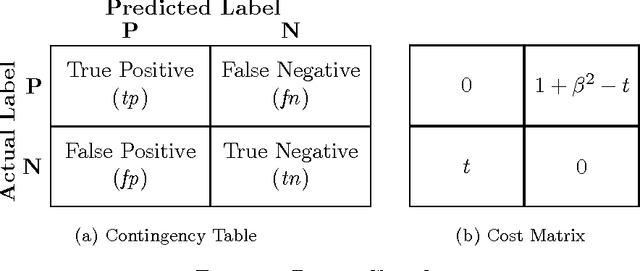

Non-linear performance measures are widely used for the evaluation of learning algorithms. For example, $F$-measure is a commonly used performance measure for classification problems in machine learning and information retrieval community. We study the theoretical properties of a subset of non-linear performance measures called pseudo-linear performance measures which includes $F$-measure, \emph{Jaccard Index}, among many others. We establish that many notions of $F$-measures and \emph{Jaccard Index} are pseudo-linear functions of the per-class false negatives and false positives for binary, multiclass and multilabel classification. Based on this observation, we present a general reduction of such performance measure optimization problem to cost-sensitive classification problem with unknown costs. We then propose an algorithm with provable guarantees to obtain an approximately optimal classifier for the $F$-measure by solving a series of cost-sensitive classification problems. The strength of our analysis is to be valid on any dataset and any class of classifiers, extending the existing theoretical results on pseudo-linear measures, which are asymptotic in nature. We also establish the multi-objective nature of the $F$-score maximization problem by linking the algorithm with the weighted-sum approach used in multi-objective optimization. We present numerical experiments to illustrate the relative importance of cost asymmetry and thresholding when learning linear classifiers on various $F$-measure optimization tasks.
Sparsity by Worst-Case Penalties
Jul 19, 2017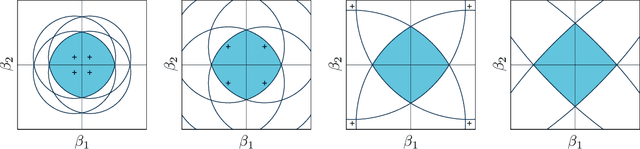
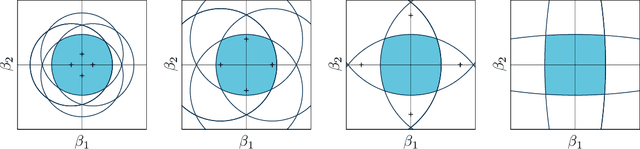
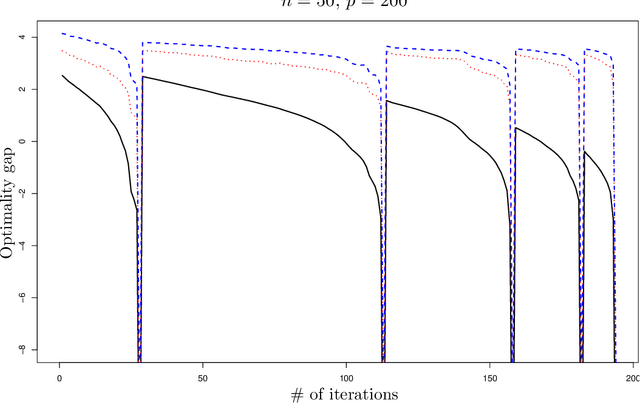
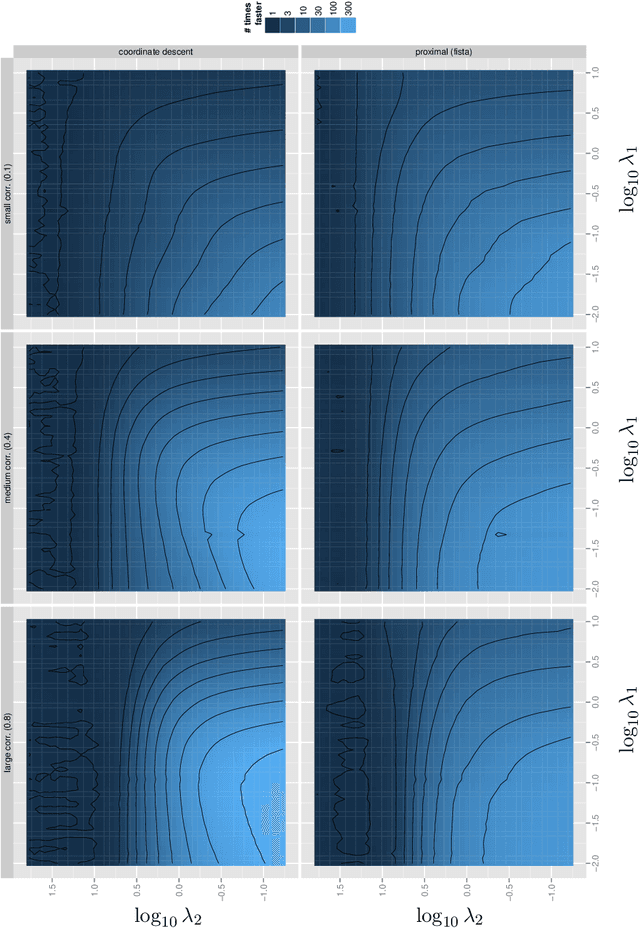
This paper proposes a new interpretation of sparse penalties such as the elastic-net and the group-lasso. Beyond providing a new viewpoint on these penalization schemes, our approach results in a unified optimization strategy. Our experiments demonstrate that this strategy, implemented on the elastic-net, is computationally extremely efficient for small to medium size problems. Our accompanying software solves problems very accurately, at machine precision, in the time required to get a rough estimate with competing state-of-the-art algorithms. We illustrate on real and artificial datasets that this accuracy is required to for the correctness of the support of the solution, which is an important element for the interpretability of sparsity-inducing penalties.
Combining Two And Three-Way Embeddings Models for Link Prediction in Knowledge Bases
Jun 02, 2015



This paper tackles the problem of endogenous link prediction for Knowledge Base completion. Knowledge Bases can be represented as directed graphs whose nodes correspond to entities and edges to relationships. Previous attempts either consist of powerful systems with high capacity to model complex connectivity patterns, which unfortunately usually end up overfitting on rare relationships, or in approaches that trade capacity for simplicity in order to fairly model all relationships, frequent or not. In this paper, we propose Tatec a happy medium obtained by complementing a high-capacity model with a simpler one, both pre-trained separately and then combined. We present several variants of this model with different kinds of regularization and combination strategies and show that this approach outperforms existing methods on different types of relationships by achieving state-of-the-art results on four benchmarks of the literature.
An Efficient Approach to Sparse Linear Discriminant Analysis
Jun 27, 2012
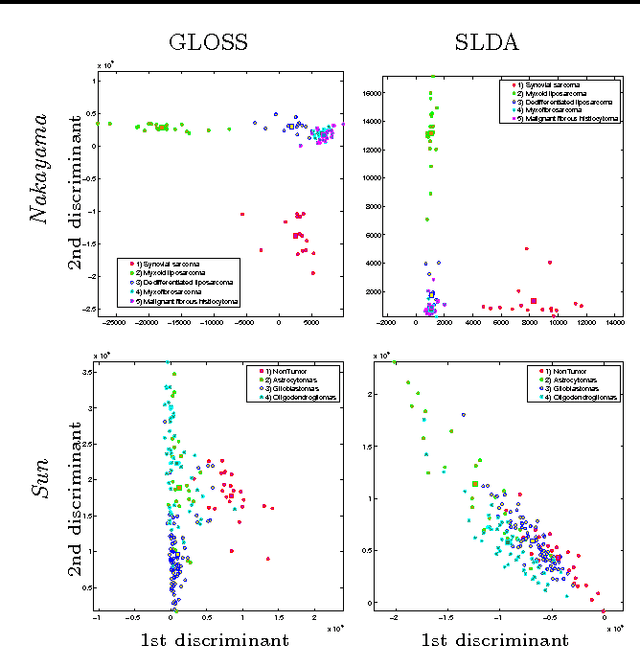

We present a novel approach to the formulation and the resolution of sparse Linear Discriminant Analysis (LDA). Our proposal, is based on penalized Optimal Scoring. It has an exact equivalence with penalized LDA, contrary to the multi-class approaches based on the regression of class indicator that have been proposed so far. Sparsity is obtained thanks to a group-Lasso penalty that selects the same features in all discriminant directions. Our experiments demonstrate that this approach generates extremely parsimonious models without compromising prediction performances. Besides prediction, the resulting sparse discriminant directions are also amenable to low-dimensional representations of data. Our algorithm is highly efficient for medium to large number of variables, and is thus particularly well suited to the analysis of gene expression data.