 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-inflation in the Multivariate Poisson Lognormal Family
May 23, 2024Analyzing high-dimensional count data is a challenge and statistical model-based approaches provide an adequate and efficient framework that preserves explainability. The (multivariate) Poisson-Log-Normal (PLN) model is one such model: it assumes count data are driven by an underlying structured latent Gaussian variable, so that the dependencies between counts solely stems from the latent dependencies. However PLN doesn't account for zero-inflation, a feature frequently observed in real-world datasets. Here we introduce the Zero-Inflated PLN (ZIPLN) model, adding a multivariate zero-inflated component to the model, as an additional Bernoulli latent variable. The Zero-Inflation can be fixed, site-specific, feature-specific or depends on covariates. We estimate model parameters using variational inference that scales up to datasets with a few thousands variables and compare two approximations: (i) independent Gaussian and Bernoulli variational distributions or (ii) Gaussian variational distribution conditioned on the Bernoulli one. The method is assessed on synthetic data and the efficiency of ZIPLN is established even when zero-inflation concerns up to $90\%$ of the observed counts. We then apply both ZIPLN and PLN to a cow microbiome dataset, containing $90.6\%$ of zeroes. Accounting for zero-inflation significantly increases log-likelihood and reduces dispersion in the latent space, thus leading to improved group discrimination.
Sparsity by Worst-Case Penalties
Jul 19, 2017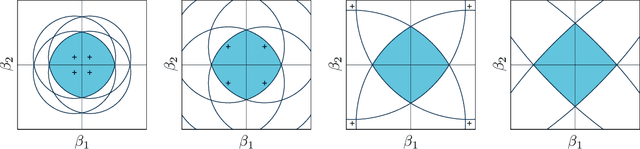
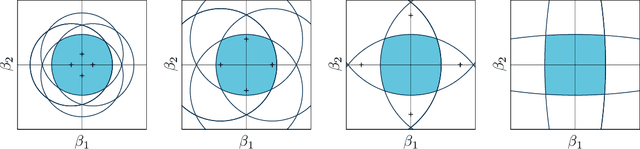
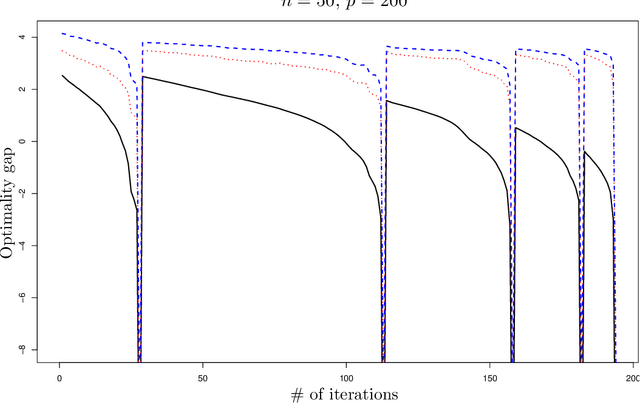
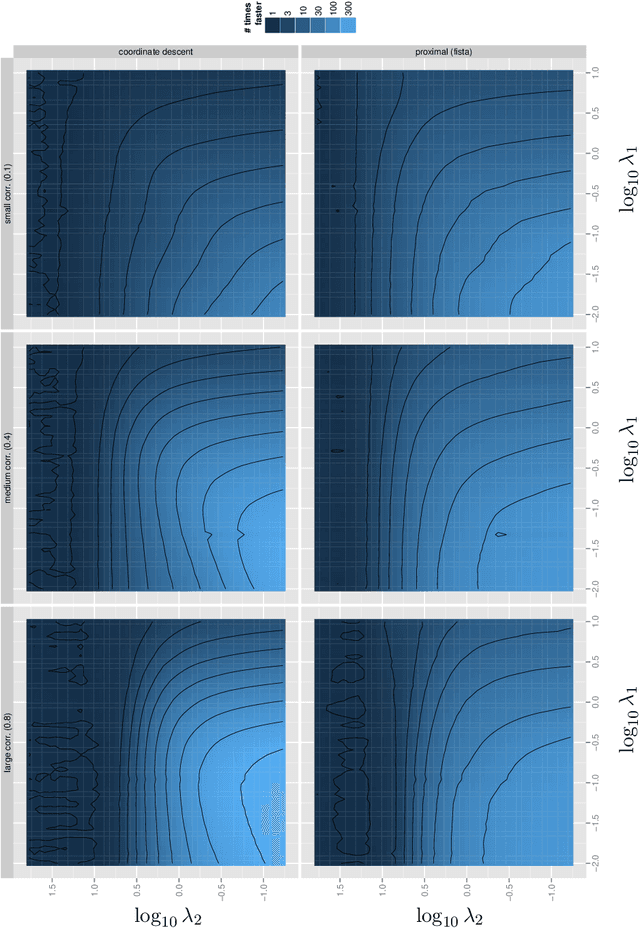
This paper proposes a new interpretation of sparse penalties such as the elastic-net and the group-lasso. Beyond providing a new viewpoint on these penalization schemes, our approach results in a unified optimization strategy. Our experiments demonstrate that this strategy, implemented on the elastic-net, is computationally extremely efficient for small to medium size problems. Our accompanying software solves problems very accurately, at machine precision, in the time required to get a rough estimate with competing state-of-the-art algorithms. We illustrate on real and artificial datasets that this accuracy is required to for the correctness of the support of the solution, which is an important element for the interpretability of sparsity-inducing penalties.