 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sharper Object Boundaries in Self-Supervised Depth Estimation
Sep 19, 2025Accurate monocular depth estimation is crucial for 3D scene understanding, but existing methods often blur depth at object boundaries, introducing spurious intermediate 3D points. While achieving sharp edges usually requires very fine-grained supervision, our method produces crisp depth discontinuities using only self-supervision. Specifically, we model per-pixel depth as a mixture distribution, capturing multiple plausible depths and shifting uncertainty from direct regression to the mixture weights. This formulation integrates seamlessly into existing pipelines via variance-aware loss functions and uncertainty propagation. Extensive evaluations on KITTI and VKITTIv2 show that our method achieves up to 35% higher boundary sharpness and improves point cloud quality compared to state-of-the-art baselines.
DELTA: Dense Depth from Events and LiDAR using Transformer's Attention
May 05, 2025Event cameras and LiDARs provide complementary yet distinct data: respectively, asynchronous detections of changes in lighting versus sparse but accurate depth information at a fixed rate. To this day, few works have explored the combination of these two modalities. In this article, we propose a novel neural-network-based method for fusing event and LiDAR data in order to estimate dense depth maps. Our architecture, DELTA, exploits the concepts of self- and cross-attention to model the spatial and temporal relations within and between the event and LiDAR data. Following a thorough evaluation, we demonstrate that DELTA sets a new state of the art in the event-based depth estimation problem, and that it is able to reduce the errors up to four times for close ranges compared to the previous SOTA.
Uncertainty-Aware Online Extrinsic Calibration: A Conformal Prediction Approach
Jan 12, 2025Accurate sensor calibration is crucial for autonomous systems, yet its uncertainty quantification remains underexplored. We present the first approach to integrate uncertainty awareness into online extrinsic calibration, combining Monte Carlo Dropout with Conformal Prediction to generate prediction intervals with a guaranteed level of coverage. Our method proposes a framework to enhance existing calibration models with uncertainty quantification, compatible with various network architectures. Validated on KITTI (RGB Camera-LiDAR) and DSEC (Event Camera-LiDAR) datasets, we demonstrate effectiveness across different visual sensor types, measuring performance with adapted metrics to evaluate the efficiency and reliability of the intervals. By providing calibration parameters with quantifiable confidence measures, we offer insights into the reliability of calibration estimates, which can greatly improve the robustness of sensor fusion in dynamic environments and usefully serve the Computer Vision community.
MULi-Ev: Maintaining Unperturbed LiDAR-Event Calibration
May 28, 2024Despite the increasing interest in enhancing perception systems for autonomous vehicles, the online calibration between event cameras and LiDAR - two sensors pivotal in capturing comprehensive environmental information - remains unexplored. We introduce MULi-Ev, the first online, deep learning-based framework tailored for the extrinsic calibration of event cameras with LiDAR. This advancement is instrumental for the seamless integration of LiDAR and event cameras, enabling dynamic, real-time calibration adjustments that are essential for maintaining optimal sensor alignment amidst varying operational conditions. Rigorously evaluated against the real-world scenarios presented in the DSEC dataset, MULi-Ev not only achieves substantial improvements in calibration accuracy but also sets a new standard for integrating LiDAR with event cameras in mobile platforms. Our findings reveal the potential of MULi-Ev to bolster the safety, reliability, and overall performance of event-based perception systems in autonomous driving, marking a significant step forward in their real-world deployment and effectiveness.
PseudoCal: Towards Initialisation-Free Deep Learning-Based Camera-LiDAR Self-Calibration
Sep 18, 2023



Camera-LiDAR extrinsic calibration is a critical task for multi-sensor fusion in autonomous systems, such as self-driving vehicles and mobile robots. Traditional techniques often require manual intervention or specific environments, making them labour-intensive and error-prone. Existing deep learning-based self-calibration methods focus on small realignments and still rely on initial estimates, limiting their practicality. In this paper, we present PseudoCal, a novel self-calibration method that overcomes these limitations by leveraging the pseudo-LiDAR concept and working directly in the 3D space instead of limiting itself to the camera field of view. In typical autonomous vehicle and robotics contexts and conventions, PseudoCal is able to perform one-shot calibration quasi-independently of initial parameter estimates, addressing extreme cases that remain unsolved by existing approaches.
Learning to Estimate Two Dense Depths from LiDAR and Event Data
Feb 28, 2023



Event cameras do not produce images, but rather a continuous flow of events, which encode changes of illumination for each pixel independently and asynchronously. While they output temporally rich information, they lack any depth information which could facilitate their use with other sensors. LiDARs can provide this depth information, but are by nature very sparse, which makes the depth-to-event association more complex. Furthermore, as events represent changes of illumination, they might also represent changes of depth; associating them with a single depth is therefore inadequate. In this work, we propose to address these issues by fusing information from an event camera and a LiDAR using a learning-based approach to estimate accurate dense depth maps. To solve the "potential change of depth" problem, we propose here to estimate two depth maps at each step: one "before" the events happen, and one "after" the events happen. We further propose to use this pair of depths to compute a depth difference for each event, to give them more context. We train and evaluate our network, ALED, on both synthetic and real driving sequences, and show that it is able to predict dense depths with an error reduction of up to 61% compared to the current state of the art. We also demonstrate the quality of our 2-depths-to-event association, and the usefulness of the depth difference information. Finally, we release SLED, a novel synthetic dataset comprising events, LiDAR point clouds, RGB images, and dense depth maps.
Real-Time Optical Flow for Vehicular Perception with Low- and High-Resolution Event Cameras
Dec 20, 2021


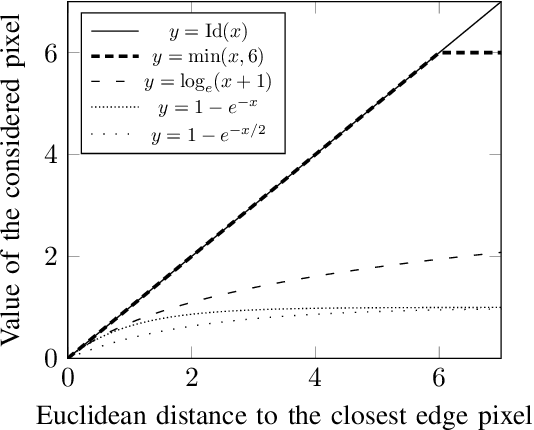
Event cameras capture changes of illumination in the observed scene rather than accumulating light to create images. Thus, they allow for applications under high-speed motion and complex lighting conditions, where traditional framebased sensors show their limits with blur and over- or underexposed pixels. Thanks to these unique properties, they represent nowadays an highly attractive sensor for ITS-related applications. Event-based optical flow (EBOF) has been studied following the rise in popularity of these neuromorphic cameras. The recent arrival of high-definition neuromorphic sensors, however, challenges the existing approaches, because of the increased resolution of the events pixel array and a much higher throughput. As an answer to these points, we propose an optimized framework for computing optical flow in real-time with both low- and high-resolution event cameras. We formulate a novel dense representation for the sparse events flow, in the form of the "inverse exponential distance surface". It serves as an interim frame, designed for the use of proven, state-of-the-art frame-based optical flow computation methods. We evaluate our approach on both low- and high-resolution driving sequences, and show that it often achieves better results than the current state of the art, while also reaching higher frame rates, 250Hz at 346 x 260 pixels and 77Hz at 1280 x 720 pixels.
Continuous Conditional Random Field Convolution for Point Cloud Segmentation
Oct 12, 2021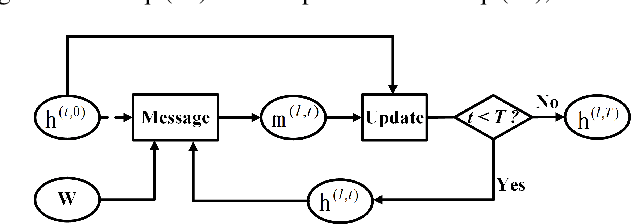
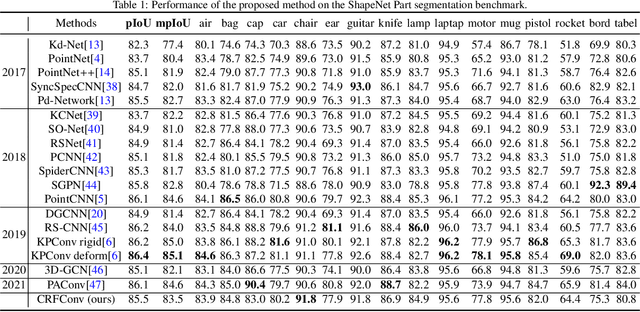
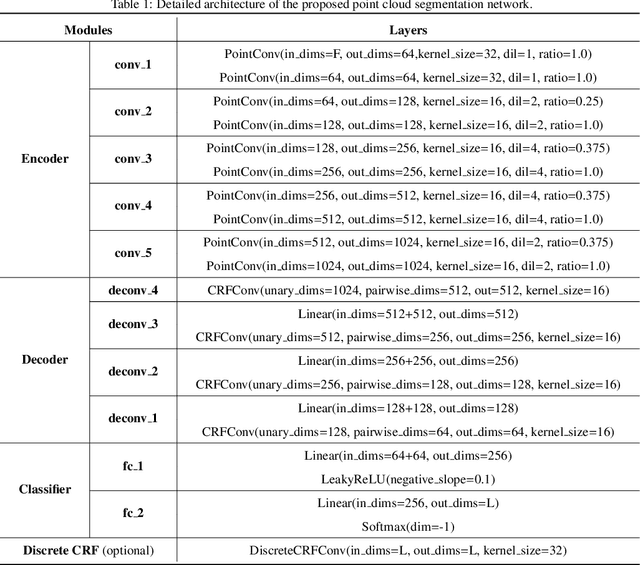

Point cloud segmentation is the foundation of 3D environmental perception for modern intelligent systems. To solve this problem and image segmentation, conditional random fields (CRFs) are usually formulated as discrete models in label space to encourage label consistency, which is actually a kind of postprocessing. In this paper, we reconsider the CRF in feature space for point cloud segmentation because it can capture the structure of features well to improve the representation ability of features rather than simply smoothing. Therefore, we first model the point cloud features with a continuous quadratic energy model and formulate its solution process as a message-passing graph convolution, by which it can be easily integrated into a deep network. We theoretically demonstrate that the message passing in the graph convolution is equivalent to the mean-field approximation of a continuous CRF model. Furthermore, we build an encoder-decoder network based on the proposed continuous CRF graph convolution (CRFConv), in which the CRFConv embedded in the decoding layers can restore the details of high-level features that were lost in the encoding stage to enhance the location ability of the network, thereby benefiting segmentation. Analogous to the CRFConv, we show that the classical discrete CRF can also work collaboratively with the proposed network via another graph convolution to further improve the segmentation results. Experiments on various point cloud benchmarks demonstrate the effectiveness and robustness of the proposed method. Compared with the state-of-the-art methods, the proposed method can also achieve competitive segmentation performance.
* 20 pages + 8 pages (supplemental material)
Efficient exact computation of the conjunctive and disjunctive decompositions of D-S Theory for information fusion: Translation and extension
Jul 13, 2021Dempster-Shafer Theory (DST) generalizes Bayesian probability theory, offering useful additional information, but suffers from a high computational burden. A lot of work has been done to reduce the complexity of computations used in information fusion with Dempster's rule. Yet, few research had been conducted to reduce the complexity of computations for the conjunctive and disjunctive decompositions of evidence, which are at the core of other important methods of information fusion. In this paper, we propose a method designed to exploit the actual evidence (information) contained in these decompositions in order to compute them. It is based on a new notion that we call focal point, derived from the notion of focal set. With it, we are able to reduce these computations up to a linear complexity in the number of focal sets in some cases. In a broader perspective, our formulas have the potential to be tractable when the size of the frame of discernment exceeds a few dozen possible states, contrary to the existing litterature. This article extends (and translates) our work published at the french conference GRETSI in 2019.
Fusion of neural networks, for LIDAR-based evidential road mapping
Feb 05, 2021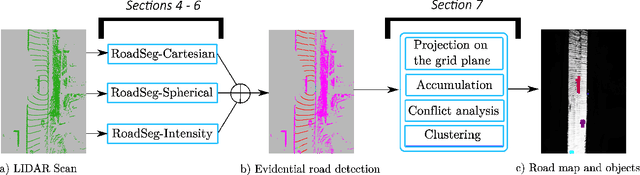
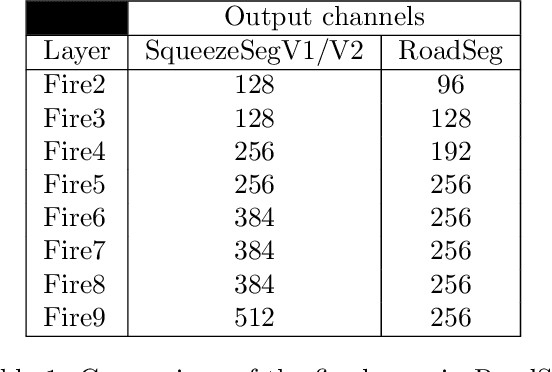
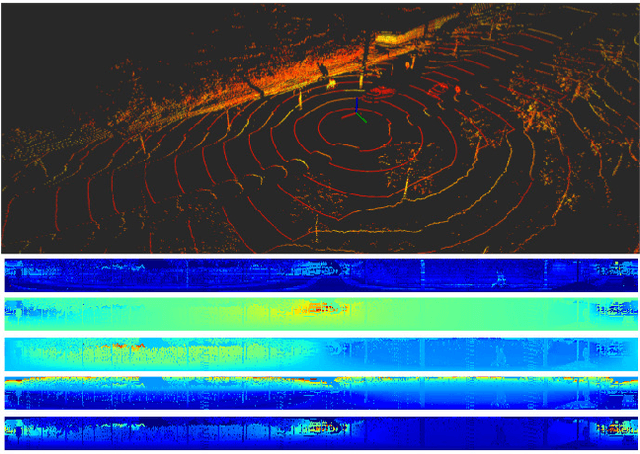

LIDAR sensors are usually used to provide autonomous vehicles with 3D representations of their environment. In ideal conditions, geometrical models could detect the road in LIDAR scans, at the cost of a manual tuning of numerical constraints, and a lack of flexibility. We instead propose an evidential pipeline, to accumulate road detection results obtained from neural networks. First, we introduce RoadSeg, a new convolutional architecture that is optimized for road detection in LIDAR scans. RoadSeg is used to classify individual LIDAR points as either belonging to the road, or not. Yet, such point-level classification results need to be converted into a dense representation, that can be used by an autonomous vehicle. We thus secondly present an evidential road mapping algorithm, that fuses consecutive road detection results. We benefitted from a reinterpretation of logistic classifiers, which can be seen as generating a collection of simple evidential mass functions. An evidential grid map that depicts the road can then be obtained, by projecting the classification results from RoadSeg into grid cells, and by handling moving objects via conflict analysis. The system was trained and evaluated on real-life data. A python implementation maintains a 10 Hz framerate. Since road labels were needed for training, a soft labelling procedure, relying lane-level HD maps, was used to generate coarse training and validation sets. An additional test set was manually labelled for evaluation purposes. So as to reach satisfactory results, the system fuses road detection results obtained from three variants of RoadSeg, processing different LIDAR features.