 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient exact computation of the conjunctive and disjunctive decompositions of D-S Theory for information fusion: Translation and extension
Jul 13, 2021Dempster-Shafer Theory (DST) generalizes Bayesian probability theory, offering useful additional information, but suffers from a high computational burden. A lot of work has been done to reduce the complexity of computations used in information fusion with Dempster's rule. Yet, few research had been conducted to reduce the complexity of computations for the conjunctive and disjunctive decompositions of evidence, which are at the core of other important methods of information fusion. In this paper, we propose a method designed to exploit the actual evidence (information) contained in these decompositions in order to compute them. It is based on a new notion that we call focal point, derived from the notion of focal set. With it, we are able to reduce these computations up to a linear complexity in the number of focal sets in some cases. In a broader perspective, our formulas have the potential to be tractable when the size of the frame of discernment exceeds a few dozen possible states, contrary to the existing litterature. This article extends (and translates) our work published at the french conference GRETSI in 2019.
Focal points and their implications for Möbius Transforms and Dempster-Shafer Theory
Dec 05, 2020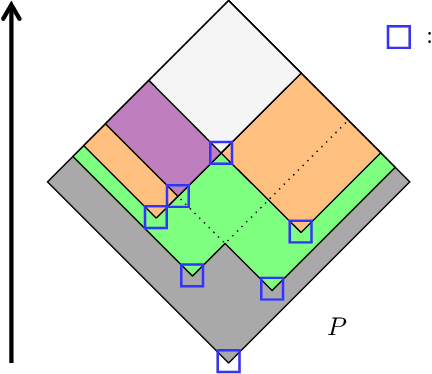
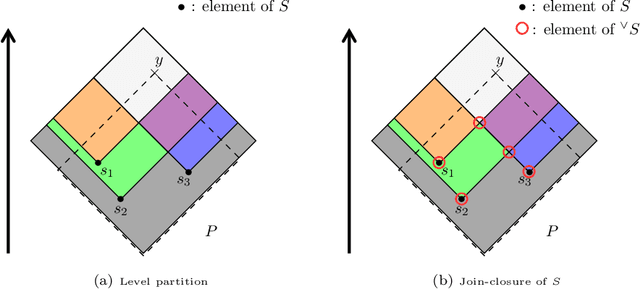
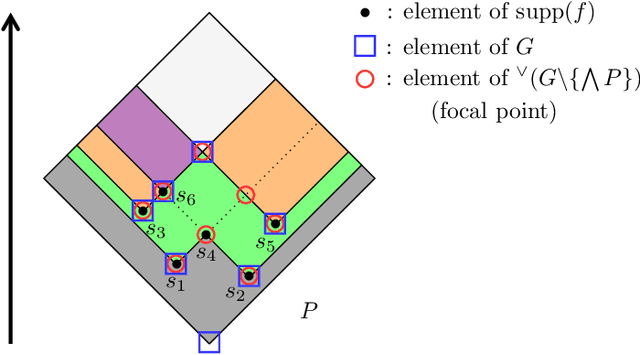
Dempster-Shafer Theory (DST) generalizes Bayesian probability theory, offering useful additional information, but suffers from a much higher computational burden. A lot of work has been done to reduce the time complexity of information fusion with Dempster's rule, which is a pointwise multiplication of two zeta transforms, and optimal general algorithms have been found to get the complete definition of these transforms. Yet, it is shown in this paper that the zeta transform and its inverse, the M\"obius transform, can be exactly simplified, fitting the quantity of information contained in belief functions. Beyond that, this simplification actually works for any function on any partially ordered set. It relies on a new notion that we call focal point and that constitutes the smallest domain on which both the zeta and M\"obius transforms can be defined. We demonstrate the interest of these general results for DST, not only for the reduction in complexity of most transformations between belief representations and their fusion, but also for theoretical purposes. Indeed, we provide a new generalization of the conjunctive decomposition of evidence and formulas uncovering how each decomposition weight is tied to the corresponding mass function.
A Variational Time Series Feature Extractor for Action Prediction
Sep 26, 2018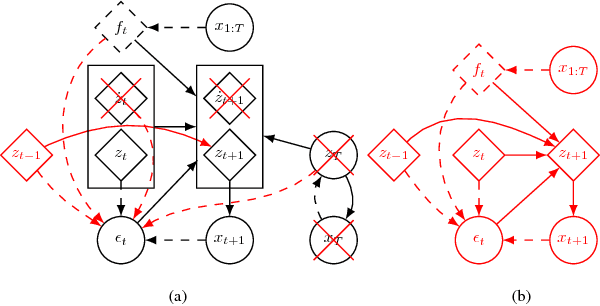

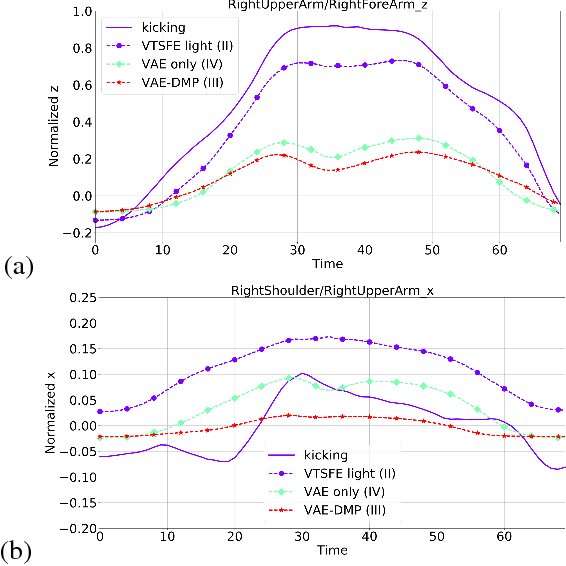
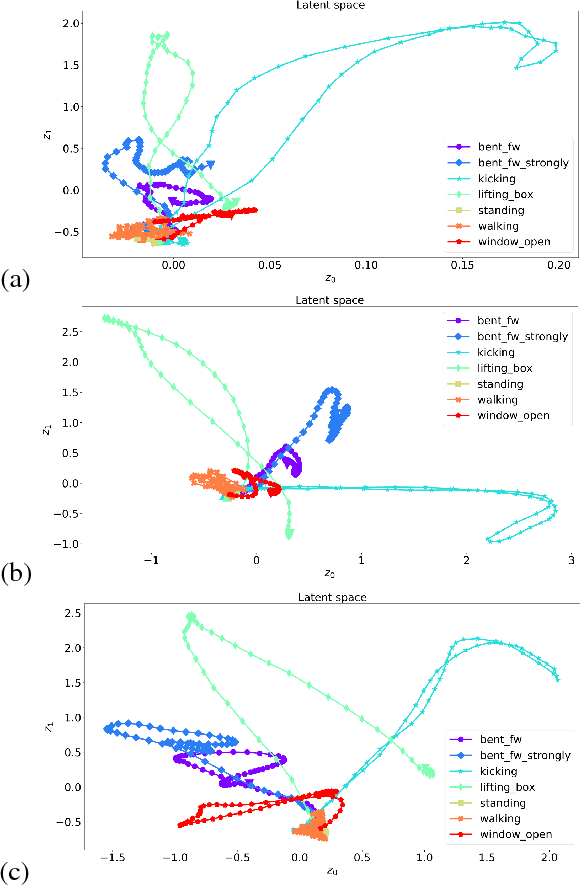
We propose a Variational Time Series Feature Extractor (VTSFE), inspired by the VAE-DMP model of Chen et al., to be used for action recognition and prediction. Our method is based on variational autoencoders. It improves VAE-DMP in that it has a better noise inference model, a simpler transition model constraining the acceleration in the trajectories of the latent space, and a tighter lower bound for the variational inference. We apply the method for classification and prediction of whole-body movements on a dataset with 7 tasks and 10 demonstrations per task, recorded with a wearable motion capture suit. The comparison with VAE and VAE-DMP suggests the better performance of our method for feature extraction. An open-source software implementation of each method with TensorFlow is also provided. In addition, a more detailed version of this work can be found in the indicated code repository. Although it was meant to, the VTSFE hasn't been tested for action prediction, due to a lack of time in the context of Maxime Chaveroche's Master thesis at INRIA.